标签:style blog http java color strong
源码编译
我的测试环境:
- 系统:Centos 6.4 - 64位
- Java:1.7.45
- Scala:2.10.4
- Hadoop:2.2.0
Spark 1.0.0 源码地址:http://d3kbcqa49mib13.cloudfront.net/spark-1.0.0.tgz
解压源码,在根去根目录下执行以下命令(sbt编译我没尝试)
./make-distribution.sh --hadoop 2.2.0 --with-yarn --tgz --with-hive
几个重要参数
--hadoop :指定Hadoop版本
--with-yarn yarn支持是必须的
--with-hive 读取hive数据也是必须的,反正我很讨厌Shark,以后开发们可以在Spark上自己封装SQL&HQL客户端,也是个不错的选择。
# --tgz: Additionally creates spark-$VERSION-bin.tar.gz
# --hadoop VERSION: Builds against specified version of Hadoop.
# --with-yarn: Enables support for Hadoop YARN.
# --with-hive: Enable support for reading Hive tables.
# --name: A moniker for the release target. Defaults to the Hadoop verison.不想自己编译的话直接下载二进制包吧:
Spark 1.0.0 on Hadoop 1 / CDH3, CDH4 二进制包:http://d3kbcqa49mib13.cloudfront.net/spark-1.0.0-bin-hadoop1.tgz
Spark 1.0.0 on Hadoop 2 / CDH5, HDP2 二进制包:http://d3kbcqa49mib13.cloudfront.net/spark-1.0.0-bin-hadoop2.tgz
进过漫长的等待,在源码跟目录下会生成一个tgz压缩包

把这个包copy到你想部署的目录并解压。
环境变量:
export SCALA_HOME=/opt/scala-2.10.4
export PATH=$PATH:$SCALA_HOME/bin
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
特别注意:只需要把解压包copy到yarn集群中的任意一台。一个节点就够了,不需要在所有节点都部署,除非你需要多个Client节点调用spark作业。
在这里我们不需要搭建独立的Spark集群,利用Yarn Client调用Hadoop集群的计算资源。
- cp 解压后的目录/conf/log4j.properties.template 解压后的目录/conf/log4j.properties
- cp 解压后的目录/conf/spark-env.sh.template 解压后的目录/conf/spark-env.sh
编辑spark-env.sh
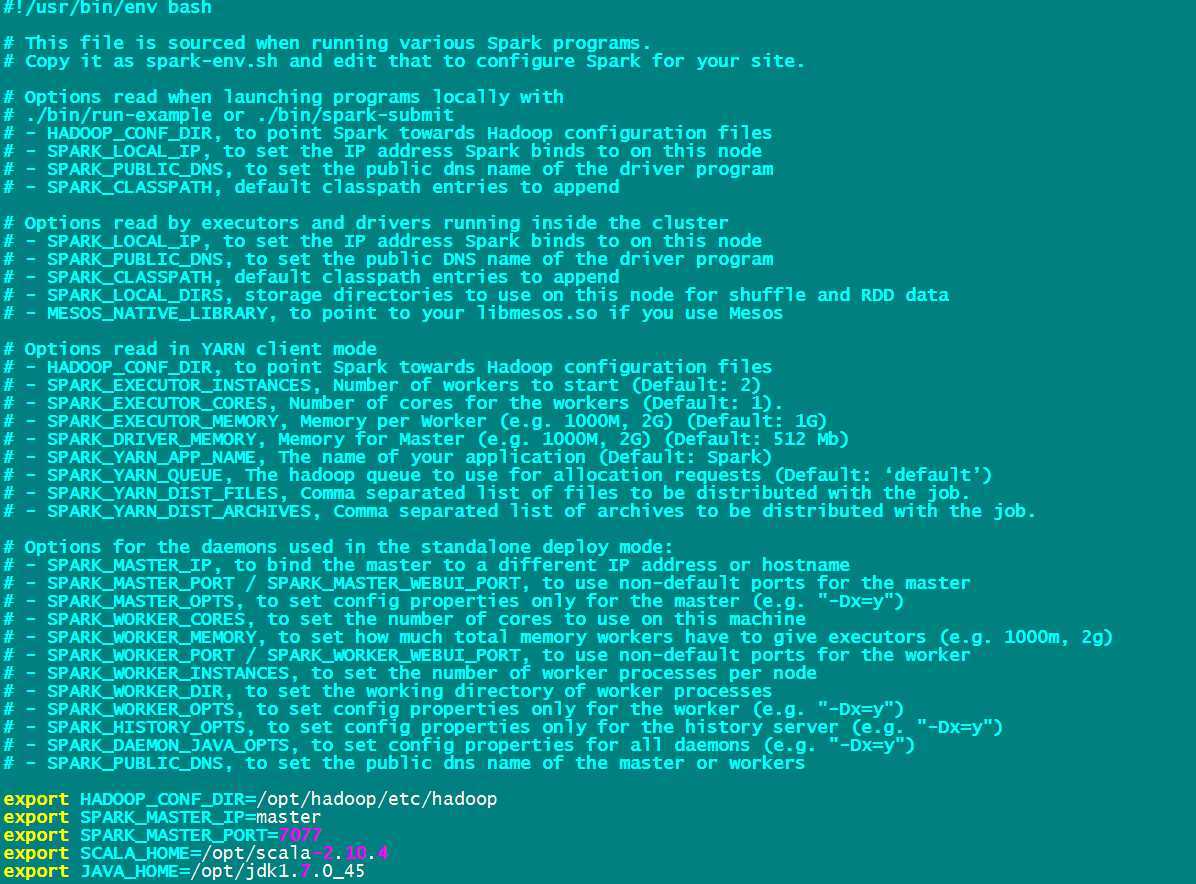
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export SCALA_HOME=/opt/scala-2.10.4
export JAVA_HOME=/opt/jdk1.7.0_45
编辑History Server
通过配置conf/spark-defaults.conf可以查看已完成job的历史记录
spark.eventLog.enabled=true
spark.eventLog.dir=hdfs://XX
具体配置参见Spark1.0.0 history server 配置。
这是我的配置,配置和之前的几个版本略有不同,但大差不差。
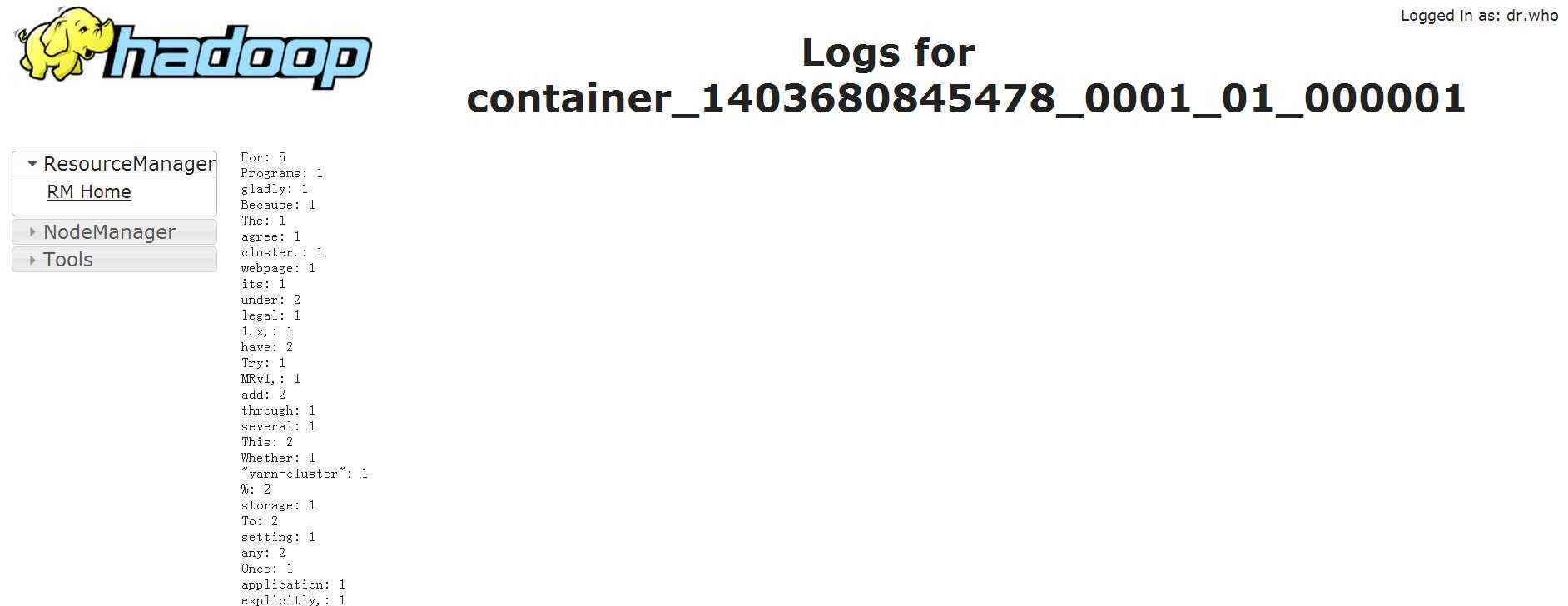
用Yarn Client调用一下MR中的经典例子:Spark版的word count
这里要特别注意,SparkContext有变动,之前版本wordcount例子中的的第一个参数要去掉。
- SPARK_JAR=./lib/spark-assembly-1.0.0-hadoop2.2.0.jar \
- ./bin/spark-class org.apache.spark.deploy.yarn.Client \
- --jar ./lib/spark-examples-1.0.0-hadoop2.2.0.jar \
- --class org.apache.spark.examples.JavaWordCount \
- --args hdfs://master:9000/user/hadoop/README.md \
- --num-executors 2 \
- --executor-cores 1 \
- --driver-memory 1024M \
- --executor-memory 1000M \
- --name "word count on spark"
运行结果在stdout中查看
Spark 1.0.0 部署Hadoop 2.2.0上,布布扣,bubuko.com
标签:style blog http java color strong
原文地址:http://www.cnblogs.com/rjf-cloud/p/3847462.html