标签:
主机名称 | 主机ip | 配置 | 主要功能 |
master1 | 硬盘300G,内存32G,CPU8核 | 管理主节点 | |
master2 | 硬盘300G,内存32G,CPU8核 | 管理备份节点 | |
slave1 | 硬盘300G,内存8G,CPU4核 | 数据节点 | |
slave2 | 硬盘300G,内存8G,CPU4核 | 数据节点 | |
slave3 | 硬盘300G,内存8G,CPU4核 | 数据节点 | |
slave4 | 硬盘500G,内存4G,CPU2核 | mysql数据库 |
本次集群使用6台物理机,操作系统都采用centOS6.4版本
hadoop-2.2.0.tar.gz
apache-hive-1.0.1-bin.tar.gz
sqoop-1.4.4.bin__hadoop-0.20.tar.gz
zookeeper-3.4.6.tar.gz
jdk1.7
集群组件包
集群机器配置
设置静态IP
vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0 #描述网卡对应的设备别名,例如ifcfg-eth0的文件中它为eth0
BOOTPROTO=static #设置网卡获得ip地址的方式,可能的选项为static,dhcp或bootp,分别对应静态指定的 ip地址,通过dhcp协议获得的ip地址,通过bootp协议获得的ip地址
BROADCAST=192.168.0.255 #对应的子网广播地址
HWADDR=00:07:E9:05:E8:B4 #对应的网卡物。
修改主机名
vi /etc/sysconfig/network
hostname=master1
重启一下网络service network restart
验证reboot -h now 立刻重启 然后hostname
关闭防火墙
关闭已经启动的防火墙: service iptables stop (只能关闭当前)
验证:service iptables status
Firewall is not running
关闭防火墙开机自动启动功能:
(1). 先查看查看: chkconfig --list |grep iptables
iptables 0:off 1:off 2:on 3:on 4:on 5:on 6:off
(2). 关闭 chkconfig iptables off
验证:chkconfig --list |grep iptables
配置SSH免密码登录
ssh-keygen 生产密码 回车按三下
赋给其他机器的秘钥:ssh-copy-id+ip(例如:ssh-copy-id 10.1.1.1)
六台机器每台机器都要把当前机器的秘钥发送到其他五台机器上,实现五台机器免秘钥登录。
安装JDK
把机器自带的jdk删掉:显示机器安装过的jdk命令rpm -qa | grep jdk
卸载命令:
# rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.62.1.11.11.90.el6_4.x86_64
# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.25-2.3.10.4.el6_4.x86_64
# rpm -e --nodeps tzdata-java-2013c-2.el6.noarch
配置zookeeper
tar -zxvf zookeeper-3.4.6.tar.gz 解压zookeeper包
cd zookeeper安装路径的conf目录修改文件zoo_sample.cfg 为zoo.cfg
修改配置文件vi zoo.cfg
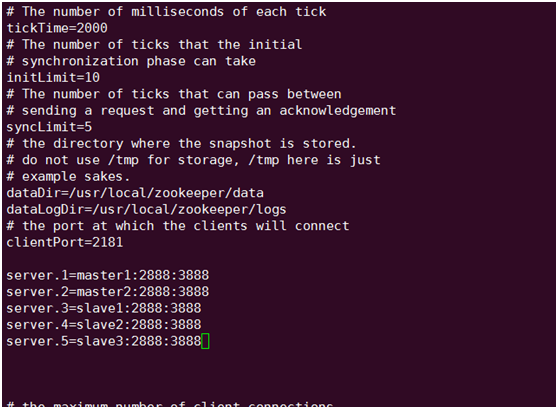
在/usr/local/zookeeoer 目录下建立 data和logs目录(注意:在以后拷贝到其它机器上在其它机器上也得建立这二个目录)
在server.1的data目录下编写一个叫 myid的文件命令为:vi myid 里面写上1
在server.2的data目录下编写一个叫 myid的文件命令为:vi myid 里面写上2
在server.3的data目录下编写一个叫 myid的文件命令为:vi myid 里面写上3
在server.4的data目录下编写一个叫 myid的文件命令为:vi myid 里面写上4
在server.5的data目录下编写一个叫 myid的文件命令为:vi myid 里面写上5。
将配置好的zookeeper拷贝到其它四台机器上(注:修改每台机器上的myid)
scp -r /usr/local/zookeeper IP:/usr/local/
进入zookeeper的bin目录启动zkServer.sh start 启动之后 输入命令:jps 查看控制台是否有QuorumPeerMain进程存在。成功后启动另外四台机器
测试zookeeper是否有报错现象进入zookeeper的bin目录输入zkCli.sh 看下是否报错现象.如果正常进行下一步安装.
配置hadoop
解压hadoop-2.2.0.tar.gz 进入hadoop解压的etc/hadoop/目录编辑六个文件分别是:core-site.xml, hadoop-env.sh, hdfs-site.xml , mapred-site.xml, yarn-site.xml, slaves
首先修改core-site.xml 配置如下:

配置解释:
fs.defaultFs:指定hdfs的nameservice为ns1,是NameNode的URI。hdfs://主机名:端口
hadoop.tmp.dir:这里的路径默认是NameNode、DataNode、JournalNode等存放数据的公共目录。用户也可以自己单独指定这三类节点的目录
ha.zookeeper.quorum:这里是ZooKeeper集群的地址和端口。注意,数量一定是奇数,且不少于三个节点。
配置hadoop-env.sh (只需要指定jdk的安装路径即可)

配置hdfs-site.xml 

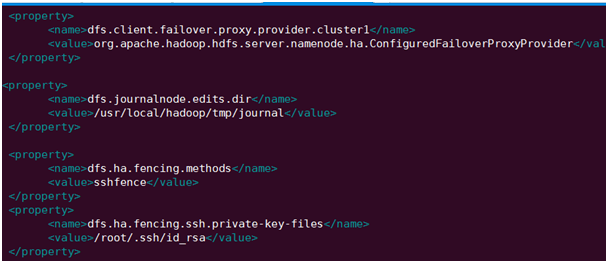

配置解释:
dfs.namenode.name.dir :
指定namenode名称空间的存储地址。
dfs.namenode.data.dir:
指定datanode数据存储地址
dfs.replication:
指定数据冗余份数。
dfs.nameservices:
指定hdfs的nameservice为cluster1,需要和core-site.xml中的保持一致。
dfs.ha.namenodes.cluster1:
cluster1下面有两个NameNode,分别是master1,master2.
dfs.namenode.rpc-address.cluster1.master1:
maste1的RPC通信地址.
dfs.namenode.http-address.cluster1.master1:
master1的http通信地址
dfs.namenode.rpc-address.cluster1.master2:
maste1的RPC通信地址
dfs.namenode.http-address.cluster1.master2:
master1的http通信地址
dfs.namenode.shared.edits.dir:
指定NameNode的元数据在JournalNode上的存放位置
dfs.ha.automatic-failover.enabled.cluster1:
指定支持高可用自动切换机制
dfs.client.failover.proxy.provider.cluster1:
配置失败自动切换实现方式
dfs.journalnode.edits.dir:
指定NameNode的元数据在JournalNode上的存放位置
dfs.ha.fencing.methods:
配置隔离机制
dfs.ha.fencing.ssh.private-key-files:
使用隔离机制时需要ssh免密码登陆
ha.failover-controller.cli-check.rpc-timeout.ms:
手动运行的FC功能(从CLI)等待健康检查、服务状态的超时时间。
ipc.client.connect.timeout:
SSH连接超时,毫秒,仅适用于内建的sshfence fencer
dfs.image.transfer.bandwidthPerSec:
Image文件传输时可以使用的最大带宽,秒字节。0表示没有限制。HA方式使用不到,可不关注
dfs.web.ugi:
Web服务器使用的用户名。如果将这个参数设置为超级用户的名称,则所有Web客户就可以看到所有的信息
4.配置mapred-site.xml
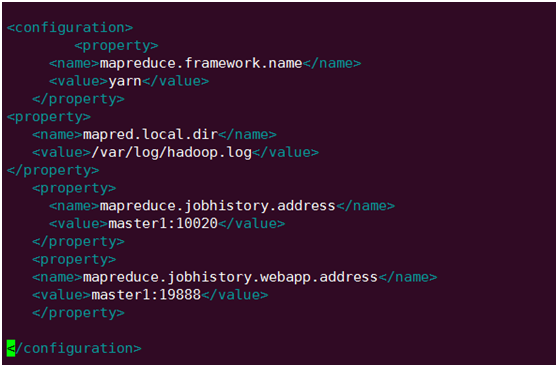
配置解释:
mapreduce.framework.name:mapreduce:
建立在指定yarn之上
mapred.local.dir:
MR 的中介数据文件存放目录
mapreduce.jobhistory.address:
配置 MapReduce JobHistory Server 地址,默认端口10020
mapreduce.jobhistory.webapp.address:
配置 MapReduce JobHistory Server web ui 地址,默认端口19888
5.配置yarn-site.xml

配置解释:
yarn.resourcemanager.hostname:
开启故障自动切换至master
yarn.resourcemanager.address:
ResourceManager 对客户端暴露的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等
yarn.resourcemanager.scheduler.address:
ResourceManager 对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等。
yarn.resourcemanager.webapp.address:
ResourceManager对外web ui地址。用户可通过该地址在浏览器中查看集群各类信息。
yarn.resourcemanager.resource-tracker.address :
ResourceManager 对NodeManager暴露的地址.。NodeManager通过该地址向RM汇报心跳,领取任务等
yarn.nodemanager.aux-services:
NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序
配置slaves
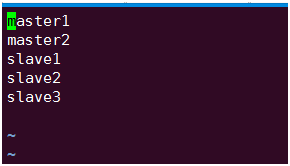
7.启动hadoop集群
1. 首先五台机器启动zookeeper zkServer.sh start启动journalnode 在master1,master2,slave1,slave2,slave3 的sbin目录中 hadoop-daemon.sh start journalnode。
2.格式化zookeeper在master1上即可命令: hdfs zkfc -formatZK
3.对master1主节点进行HDFS格式化bin/hadoop namenode –format,看是否报错。。如果没有报错进行下一步,启动主节点的namenode命令是:sbin/hadoop-daemon.sh start namenode.
4.对master2主节点进行HDFS格式化bin/hadoop namenode -bootstrapStandby,看是否报错。。如果没有报错进行下一步,启动主节点的namenode命令是:sbin/hadoop-daemon.sh start namenode
5.在master1和master2启动zkfc:
sbin/hadoop-daemon.sh start zkfc
我们的master1、master2有一个节点就会变为active状态.
6.启动datanode :在master1上执行sbin/hadoop-daemon.sh start datanode
7.启动yarn 在master1,master2上sbin/start-yarn.sh
8.检查是否启动成功在控制台上jps 看下进程是否正确主节点

备用节点进程显示如下:

在访问50070端口和8088端口是否能够访问,正常的话hadoop集群算是成功了.
8.配置hive
配置hive
解压hive包进入hive目录的conf下面修改hive-default.xml.template, hive-env.sh.template 为hvie-site.xml和hive-env.sh
编辑hive-site.xml(最好是自己vi一个hive-site.xml因为默认配置文件里面的配置都是系统配置的)
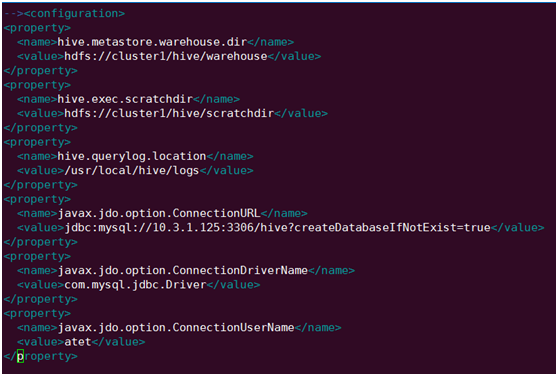

配置解释:
hive.metastore.warehouse.dir:
(HDFS上的)数据目录默认值是/user/hive/warehouse
hive.exec.scratchdir:
(HDFS上的)临时文件目录,默认值是/tmp/hive-${user.name}
hive.querylog.location:
Hive 实时查询日志所在的目录,如果该值为空,将不创建实时的查询日志。
javax.jdo.option.ConnectionURL:
元数据库的连接 URL。
javax.jdo.option.ConnectionDriverName:
JDBC驱动
javax.jdo.option.ConnectionUserName:
用户名
javax.jdo.option.ConnectionPassword:
密码
hive.metastore.authorization.storage.checks:
属性被设置成true时,Hive将会阻止没有权限的用户进行表删除操作
3.编辑hive-env.sh (指定hadoop安装目录)

4.加载mysql驱动到hive的lib目录中
5.在10.1.3.125上安装mysql数据库建立database 为hive的数据库设置alter database hive character set latin1; 改变hive元数据库的字符集.当前连接的用户远程连接权限.
6.启动hive 进入hive安装bin目录./hive 启动如果不报错的话进去
标签:
原文地址:http://my.oschina.net/u/559635/blog/506209