标签:
每日一练,每日一博。
Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
1.确定目标网站:豆瓣电影 http://movie.douban.com/top250
2.创建Scrapy项目: scrapy startproject doubanmovie
3.配置settings.py文件
BOT_NAME = ‘doubanmovie‘ SPIDER_MODULES = [‘doubanmovie.spiders‘] NEWSPIDER_MODULE = ‘doubanmovie.spiders‘ USER_AGENT = ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5‘ FEED_URI = u‘file:///G:/program/doubanmovie/douban.csv‘ #将抓取的数据存放到douban.csv文件中 FEED_FORMAT = ‘CSV‘
3.定义数据items.py:
from scrapy import Item,Field class DoubanmovieItem(Item): # define the fields for your item here like: # name = scrapy.Field() title = Field() #标题--电影名 movieInfo = Field() #电影信息 star = Field() #电影评分 quote = Field() #名句
4.创建爬虫doubanspider.py:
import scrapy from scrapy.spiders import CrawlSpider from scrapy.http import Request from scrapy.selector import Selector from doubanmovie.items import DoubanmovieItem class Douban(CrawlSpider): name = "douban" redis_key = ‘douban:start_urls‘ start_urls = [‘http://movie.douban.com/top250‘] url = ‘http://movie.douban.com/top250‘ def parse(self,response): # print response.body item = DoubanmovieItem() selector = Selector(response) Movies = selector.xpath(‘//div[@class="info"]‘) for eachMoive in Movies: title = eachMoive.xpath(‘div[@class="hd"]/a/span/text()‘).extract() fullTitle = ‘‘ for each in title: fullTitle += each movieInfo = eachMoive.xpath(‘div[@class="bd"]/p/text()‘).extract() star = eachMoive.xpath(‘div[@class="bd"]/div[@class="star"]/span/em/text()‘).extract()[0] quote = eachMoive.xpath(‘div[@class="bd"]/p[@class="quote"]/span/text()‘).extract() #quote可能为空,因此需要先进行判断 if quote: quote = quote[0] else: quote = ‘‘ item[‘title‘] = fullTitle item[‘movieInfo‘] = ‘;‘.join(movieInfo) item[‘star‘] = star item[‘quote‘] = quote yield item nextLink = selector.xpath(‘//span[@class="next"]/link/@href‘).extract() #第10页是最后一页,没有下一页的链接 if nextLink: nextLink = nextLink[0] print nextLink yield Request(self.url + nextLink,callback=self.parse)
5.爬取结果:如果出现编码问题,在excel文件中选择“utf-8”的编码保存文件即可
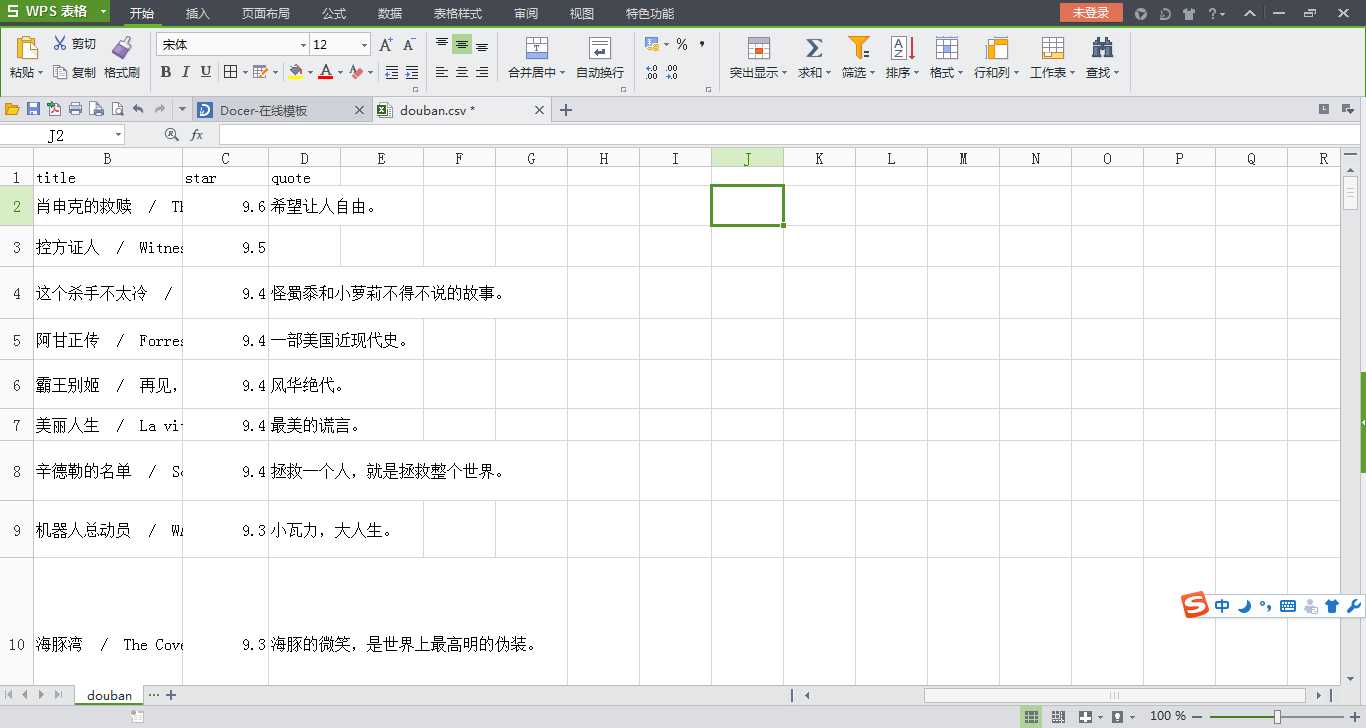
标签:
原文地址:http://www.cnblogs.com/alarm1673/p/4815036.html