标签:
Processor (CPU): the active part of the computer that does all the work (data manipulation and decision-making)
• Datapath: portion of the processor that contains hardware necessary to perform operations required by the processor (the brawn)
• Control: portion of the processor (also in hardware) that tells the datapath what needs to be done (the brain)
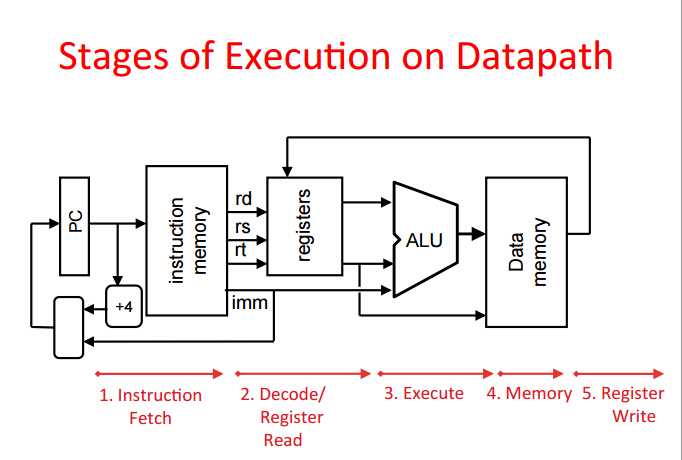
Five Stages of Instruction Execution
Stage 1: Instruction Fetch
the 32-bit instruction first be fetched from memory (the cache-memory hierarchy)
also, PC increment (PC = PC+4 to point to the next instruction)
Stage 2: Instruction Decode
read the opcode to determine instruction type and field lengths
read in data from all necessary registers
Stage 3: ALU
the read work of most instructions is done here:arithmetic (+,-,*,/), shifting, logic, comparisons
ps: in lw, sw, may do lw $t0, 40($t1), this addition in this stage
Stage 4: Memory Access
actually only the load and store instructions do anything during this stage, the other remain idle during this stage or skip it all together
as a result of the cache system, this stage is expected to be fast
Stage 5: Register Write
most instructions write the result of some computation into a register
some instructions don‘t write (branches, jumps) remain idle or skip it all together
Single Cycle Datapath
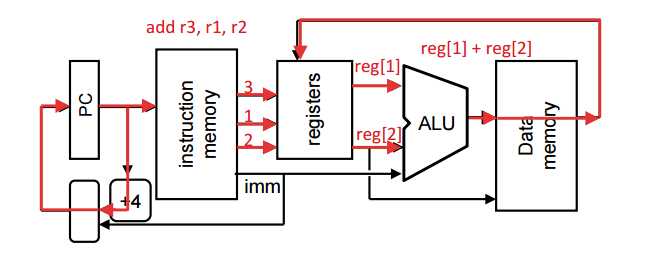
e.g
add $r3, $r1, $r2
– Stage 1: fetch this instruction, increment PC
– Stage 2: decode to determine it is an add, then read registers $r1 and $r2
– Stage 3: add the two values retrieved in Stage 2
– Stage 4: idle (nothing to write to memory)
– Stage 5: write result of Stage 3 into register $r3
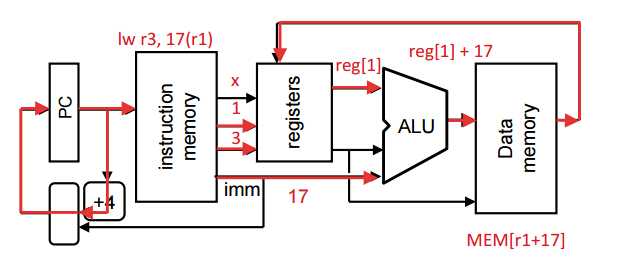
lw $r3,17($r1) # r3=Mem[r1+17]
– Stage 1: fetch this instruction, increment PC
– Stage 2: decode to determine it is a lw, then read register $r1
– Stage 3: add 17 to value in register $r1 (retrieved in Stage 2)
– Stage 4: read value from memory address computed in Stage 3
– Stage 5: write value read in Stage 4 into register $r3
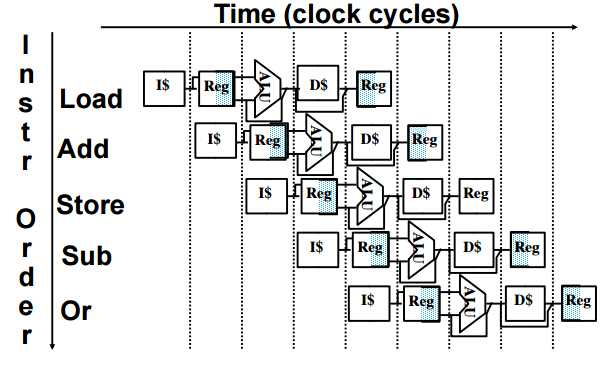
Pipelining increases throughput by overlapping execution of multiple instructions in different pipestages
标签:
原文地址:http://www.cnblogs.com/whuyt/p/4815901.html