标签:
测试表数据如下:
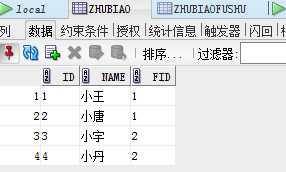
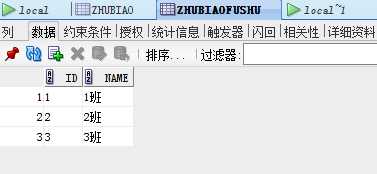
sql:
select * from zhubiaofushu where id in (select fid from zhubiao) select * from zhubiao t inner join zhubiaofushu t1 on t.fid= t1.id select t1.* from zhubiao t inner join zhubiaofushu t1 on t.fid= t1.id select distinct t1.* from zhubiao t inner join zhubiaofushu t1 on t.fid= t1.id order by t1.id asc
按以上顺序执行结果如下:

ID NAME -------------------- -------------------- 1 1班 2 2班 2 rows selected ID NAME FID ID NAME -------------------- -------------------- -------------------- -------------------- -------------------- 1 小王 1 1 1班 2 小唐 1 1 1班 3 小宇 2 2 2班 4 小丹 2 2 2班 4 rows selected ID NAME -------------------- -------------------- 1 1班 1 1班 2 2班 2 2班 4 rows selected ID NAME -------------------- -------------------- 1 1班 2 2班 2 rows selected
可以看到,第三条sql文执行结果中有重复数据,显然不是想要达到的效果。
所以,在多表连接时,如果只需要其中某一个表的列的值,可以优先考虑子查询。当使用联合查询时,需要使用distinct关键字,并注意排序,因为distinct貌似是默认降序排列的。
联合查询产生重复数据的原理:因为【zhubiao】中存在多对1的数据,生成的笛卡尔积中关于【zhubiaofushu】中有重复数据,所以,在此基础上的【t1.*】获取的数据重复
标签:
原文地址:http://www.cnblogs.com/jkgyu/p/4815725.html
