标签:
首先我们通过一个Storm和Hadoop的对比来了解Storm中的基本概念。

接下来我们再来具体看一下这些概念。
下面这个图描述了以上几个角色之间的关系。
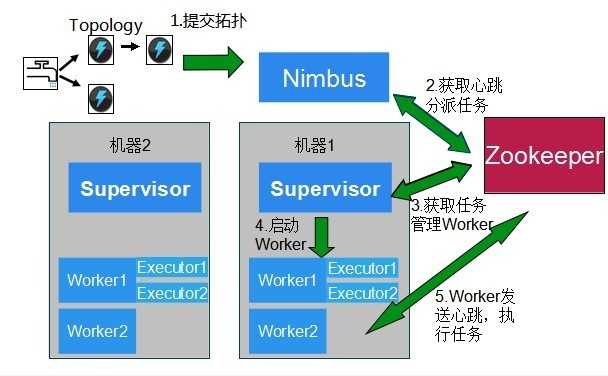
图1.2 Storm角色间关系
Hadoop是实现了MapReduce的思想,将数据切片计算来处理大量的离线数据。Hadoop处理的数据必须是已经存放在hdfs上或者类似hbase的数据库中,所以Hadoop实现的时候是通过移动计算到这些存放数据的机器上来提高效率的;而Storm不同,Storm是一个流计算框架,处理的数据是实时消息队列中的,所以需要我们写好一个topology逻辑放在那,接收进来的数据来处理,所以是通过移动数据平均分配到机器资源来获得高效率。
Hadoop的优点是处理数据量大(瓶颈是硬盘和namenode,网络等),分析灵活,可以通过实现dsl,mdx等拼接Hadoop命令或者直接使用hive,pig等来灵活分析数据。适应对大量维度进行组合分析。其缺点就是慢:每次执行前要分发jar包,Hadoop每次map数据超出阙值后会将数据写入本地文件系统,然后在reduce的时候再读进来。
Storm的优点是全内存计算,因为内存寻址速度是硬盘的百万倍以上,所以Storm的速度相比较Hadoop非常快(瓶颈是内存,cpu)。其缺点就是不够灵活:必须要先写好topology结构来等数据进来分析。
Storm 关注的是数据多次处理一次写入,而 Hadoop 关注的是数据一次写入,多次查询使用。Storm系统运行起来后是持续不断的,而Hadoop往往只是在业务需要时调用数据。
标签:
原文地址:http://www.cnblogs.com/xia520pi/p/4816507.html