标签:
这章的内容比较多。按照小节序号来组织笔记的结构;再结合函数的示例带代码标注出来需要注意的地方。
下面的内容只是个人看书时思考内容的总结,并不能代替看书(毕竟APUE是一本大多数人公认的UNIX圣经)。
8.2 Process Identifiers
1.
unix system给系统分配进程pid采用的是delay reuse策略:即,刚用完被释放的pid不会马上分配给新的进程,目的是防止新进程错误使用与之前进程相同的ID(这块内容还没太懂,以后再看);但具体等多久不一定。
2.
有几个特殊的process,具备特殊的PID(就像总统的专车牌号一样,不能被分配,有特殊含义)
比如:pid 0 代表scheduler process (或者叫swapper);pid 1 代表init process,这个进程一直live着(后面还会提到,当某些child process没有parent process的时候,init就充当这些child process的parnet)
8.3 fork Function
1.
查了一下fork的解释:creates a child process that differs from the parent process only in tis PID and PPID
也就是说,除了fork()在原进程的基础上产生一个子进程,这个子进程有自己的pid,子进程的ppid就是调用fork()进程的pid,其余的绝大部分东西自子进程都是独立于父进程的。(在memory layout上,除了text segment是share的,其余像head、stack、data都是独立的,所以是绝大部分)
2.
还有一个Copy-on-wirte的技术(COW),为了的是降低fork的开销:
能不用从parent process里面copy过去的,就不copy过去;如果某个变量的值不变,就直接读好了;如果某个变量在parent和child中不一样了,再copy过去,来一份儿新的。
这样对于用户来说,根本不知道是不是copy一份新的;只知道不会变量冲突就好了。挺屌的。
3.
(可以通过youtube上的一个学习视频先有个全貌:https://www.youtube.com/watch?v=9seb8hddeK4)
再上一段APUE书上的代码:
1 #include "apue.h" 2 3 int globvar = 6; 4 char buf[] = "a write to stdout\n"; 5 6 int main(void) 7 { 8 int var; 9 pid_t pid; 10 11 var = 88; 12 if (write(STDOUT_FILENO, buf, sizeof(buf)-1)!=sizeof(buf)-1) 13 err_sys("write error"); 14 15 printf("before fork\n"); 16 17 if ((pid=fork()) < 0) 18 { 19 err_sys("fork error"); 20 } 21 else if ( pid==0 ) 22 { 23 globvar++; 24 var++; 25 } 26 else 27 { 28 sleep(2); 29 } 30 printf("pid = %ld, glob = %d, var = %d\n", (long)getpid(), globvar, var); 31 exit(0); 32 }
直接在终端输出结果

将输出重定向到文件的结果
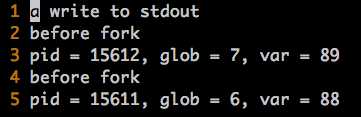
根据以上的代码和运行结果,重点关注一下调用fork()之后发生了什么事情:
总的来说,"花开两朵,各表一枝":
(1)第17行调用pid=fork()后
a. 对于原来的parent process来说返回的pid就是fork()产生的child process的pid(即,15612)
b. 对于fork()产生的child process来说,这个pid就是0(如果不是0,globalvar和var就不会自增1了)
(2)无论是parent还是child,都从调用fork()之后的代码段开始执行。
(3)parent和child之间各种变量(全局的,局部的)不会互相影响。
pid15606的parent process的两个变量保持不变;而pid15607的child process中的变量值都加1了。这就验证了之前说的,fork()产生的child process的各种memory data segment是独立的。
(4)为什么在terminal和file两种输出的结果不同呢?(这是个非常好的例子,可以说的细一些)
要想搞清楚为什么terminal和file两种输出结果不同,先要知道有一个buffer的概念(详情见APUE 5.3章节)
粗犷一些理解,bufffer就是读或写的缓冲区。为啥要有buffer这个东西呢?
书上的原文如下:“The goal of the buffering provided by the standard I/O library is to use the minimum number of read or write calls”
上面这段话引申出一个重要意思:设计buffer是为了降低cpu资源占用率。read和write(二者不涉及buffer,详情见APUE 3.7 3.8章节)每执行一次,就要请求占用CPU的资源。比如,要输出100行的文件内容(先别管输出到terminal还是file)可以采用三种不同的策略:
策略一:以字符为调用write单位,来一个字符,就请调用一次write,占用一次cpu资源;假设每行100个字符,全部输出完毕可能需要请求占用10000次cpu
策略二:以行为调用write单位,满一行就请求就调用一次write,占用一次cpu资源,总共占用100次cpu
策略三:以buffer为调用write的单位,来一次输出请求,先攒到buffer中,buffer满了再输出;假设buffer够大,那么所有输出只占用一次cpu资源。
显然,如果从cpu使用效率上考虑,策略三的cpu利用效率更高。
再精细一些,buffer的方式有哪些呢?
(1)Fully buffer。很直观,把buffer占满了就调用write输出出去,并清空buffer(清空buffer的动作叫fflush())。
(2)Line buffer。有时候需要与终端交互的,满一行就调用一次write输出到终端,并清空buffer(清空buffer的动作叫fflush())。
上面介绍了buffer的原因和方式,下面再回到上面的代码示例中,分析为什么terminal和file会得到两种不同的结果。有两个关键点:
a. 了解printf使用buffer的策略。
虽然write是不涉及到buffer的(即,一write就马上调用cpu执行输出动作),但是printf是涉及buffer策略的(即,不同情况下,请求cpu资源输出的策略是不同的)
(1)如果是terminal,printf的默认策略是执行line buffer;即如上面说的,满一行就输出出去(什么叫满一行?就是printf后面跟了一个‘\n’,提醒输出的内容满一行了)
(2)如果是file,printf的默认策略是fully buffer;即,即使在printf中遇上‘\n‘也不着急调用cpu资源去真正输出,而是憋着,一直憋到buffer满了,或者进程退出了,再真正输出到file中。
b. 了解调用fork的时候,parent process的buffer内容是copy给child process的。
(1)如果是terminal,由于line buffer策略,parent process调用printf("before fork\n")的时候,就已经把buffer内容给输出了,并且清空了buffer。因此,child process的buffer一开始就是空的,所以,也并没有再输出"before fork"了。
(2)如果是file, 由于fully buffer的策略,parent process调用printf("before fork\n")的时候,做的事情是把"before fork"给攒到buffer中了。这个时候再调用fork,parent process中的buffer内容也一起copy到child process中了。因此,在file中可以看到child process也输出了一次"before fork"。
再如果,把代码做如下修改(不要‘\n‘了)
printf("before fork");
那么无论是在terminal还是file结果都是一样的了,不解释为什么了。
8.4 vfork Function
这个函数感觉乱乱的,而且不太安全,以后用了再说吧。
8.5 exit Function 和 8.6 wait and waitpid Function
这两个函数放在一起,因为关系比较紧密。
1. 调用exit()发生了什么?wait是干啥的?
回顾一下Chapter 7 Process Environment的内容,从单个process角度来说,调用exit()后:
(1)执行atexit()注册的钩子函数
(2)执行standard I/O cleanup函数(比如把各种fopen给关上,buffer里面的内容都给fflush出去,清空buffer等)
在这里,如果从parent process和child process的角度来说,如果正常退出,exit()还告诉parent,child的退出状态。(如果是child process非正常退出呢?书中说“in the case of an abnormal termination, however, the kernel-not the process-generates a termination status to indicate the reason for the abnormal termination”,即kernel做了通知这个事情了)
但是光有child process的exit()动作还不够,在parent中,还得有wait(int& status)的动作才能够接受并把child发的退出状态存到status中。wait()起到的两个作用:
(1)阻塞parent进程
(2)只要有一个child process调用exit或者abnormal返回了,wait就不阻塞了,parent就该干啥干啥了。
(3)如果有多个child process怎么办?只要有某一个child process返回,wait就阻塞了
(4)如果想等待某个特定的child process完成了再往下进行怎么办?这个时候waitpid就派上用场了。其实waitpid是wait的进化版本,可以实现wait的全部功能,还可以定制各种wait的条件。
2. parent process中没有wait可能发生的状况,以及zombie mode的产生分析?
书上没有给出来相关的例子,还是参考的youtube上的那个fork()视频,找的例子(https://www.youtube.com/watch?v=9seb8hddeK4)
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <sys/types.h> 4 #include <sys/wait.h> 5 #include <unistd.h> 6 7 8 void doSomeWork(char *name) 9 { 10 const int NUM_TIMES = 2; 11 for ( int i = 0; i<NUM_TIMES; ++i ) 12 { 13 sleep(rand()%4); 14 printf("Done pass %d for %s\n",i, name); 15 } 16 } 17 18 int main(int argc, char *argv[]) 19 { 20 //signal(SIGCHLD, SIG_IGN); 21 printf("I am:%d\n",(int)getpid()); 22 23 pid_t pid = fork(); 24 srand((int)pid); 25 printf("fork return : %d\n", (int)pid); 26 if(pid==0) 27 { 28 printf("I am the child pid %d\n",(int)getpid()); 29 doSomeWork("Child"); 30 exit(42); 31 } 32 printf("I am the parent, waiting for child to end.\n"); 33 sleep(10); 34 int status = 0; 35 pid_t childpid = wait(&status); 36 printf("Parent knows child %d finished with status %d.\n", (int)childpid, status); 37 int childReturnValue = WEXITSTATUS(status); 38 printf("Return value was %d\n", childReturnValue); 39 sleep(10); 40 return 0; 41 }
在运行代码的时候,同时用ps -a查看进程的边变化情况:
代码运行结果:
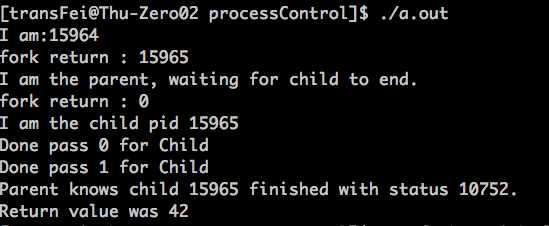
进程变化:
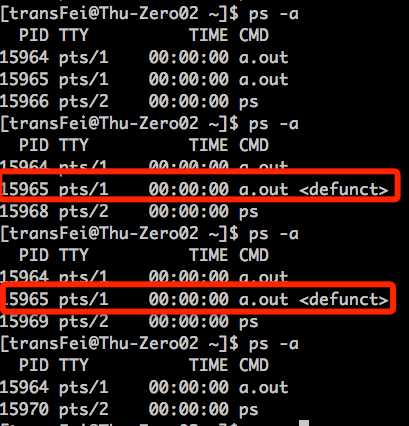
分析如下:
(1)child process再doSomeWork完成退出之后,parent还处于sleep(10)的过程中。这个时候,child就已经发出了exit(42)的动作,但是parent process还没有wait的动作;在这段时间内,child process就处于zombie mode,即僵尸进程。
(2)即使是zombie mode的进程,也并不是完全消失的,始终占用着PID资源(因为a.out<defunct>的PID15965一直存在)。直到parent process调用了wait,这才算是给child zombie process收尸了。
所谓的僵尸进程,说的就是上面这么个事情。
那么僵尸进程多了有什么坏处呢?虽然子进程在变成僵尸进程后只保存了minimum的资源,如PID号,内存资源什么的基本都不占了。但是一旦这种僵尸进程多了,占的PID就很客观了。我们知道,PID号是有限的,而且回顾上面提到的delay reuse策略,PID的编号其实也是不是想用多少就用多少的。即使系统硬件资源足够多,但是PID号都被僵尸进程占了,这个时候如果需要起一些新的process,由于众多的PID号都被站着茅坑不拉屎的僵尸进程占用了,那么真正需要PID资源的进程就被耽搁了。
3. 与僵尸进程相对,如果parent process先于child parent结束了会发生什么?
把上面的代码做一下改造:
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <sys/types.h> 4 #include <sys/wait.h> 5 #include <unistd.h> 6 7 8 void doSomeWork(char *name) 9 { 10 const int NUM_TIMES = 4; 11 for ( int i = 0; i<NUM_TIMES; ++i ) 12 { 13 sleep(rand()%4); 14 printf("Current parent process pid : %ld\n", (long)getppid()); 15 printf("Done pass %d for %s\n",i, name); 16 } 17 } 18 19 int main(int argc, char *argv[]) 20 { 21 //signal(SIGCHLD, SIG_IGN); 22 printf("I am:%d\n",(int)getpid()); 23 24 pid_t pid = fork(); 25 srand((int)pid); 26 printf("fork return : %d\n", (int)pid); 27 if(pid==0) 28 { 29 printf("I am the child pid %d\n",(int)getpid()); 30 doSomeWork("Child"); 31 exit(42); 32 } 33 printf("I am the parent, waiting for child to end.\n"); 34 sleep(4); 35 return 0; 36 }
其运行结果如下:
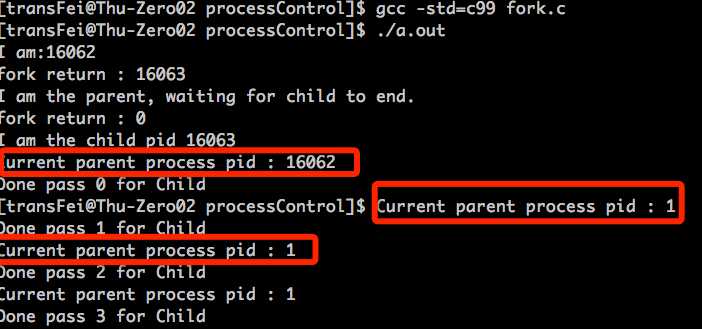
可以看到,如果parent先于child结束了,此时前面提到的init process PID 1就成为了这些child process的parent。
这里的机制是在一个process要结束之前,kernel会检查这个要结束的process是哪些进程的parent,然后把这些child parent的parent改为init process。
8.9 Race Conditions
如果是Multiprocess涉及到shared data并且final outcome依赖于这些processes执行的先后顺序,就产生了race conditions。比如,fork()就是产生Race Conditions的典型原因。因为一旦fork之后,没法预测parent还是child先执行,因此就容易出问题。
看书上的一段代码:
1 #include "apue.h" 2 3 4 static void charatatime(char *); 5 6 int main(void) 7 { 8 pid_t pid; 9 10 // TELL_WAIT(); 11 12 if ( (pid=fork()) < 0 ) 13 { 14 err_sys("fork error"); 15 } 16 else if ( pid==0 ) 17 { 18 // WAIT_PARENT(); 19 charatatime("output from child cccccccccccccccccccccccccccccccccccc\n"); 20 } 21 else{ 22 charatatime("output from parent pppppppppppppppppppppppppppppppppppp\n"); 23 // TELL_CHILD(pid); 24 } 25 exit(0); 26 } 27 28 static void charatatime(char *str) 29 { 30 char *ptr; 31 int c; 32 setbuf(stdout, NULL); // set unbuffered 33 for ( ptr = str; (c = *ptr++)!=0; ) 34 putc(c, stdout); 35 }
代码运行结果:
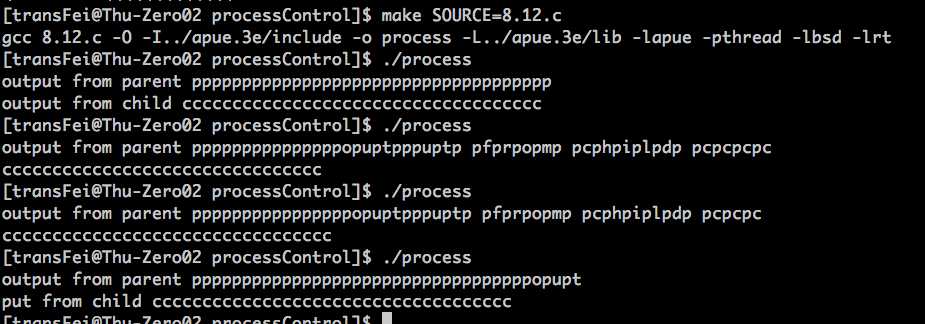
parent和child每执行一次putc就相当于争夺一次stdout的占领全。具体是parent process和child process获得占领权,这要看kernel的资源分配策略。多试验几次,就会发产生了资源竞争的情况,即parent和child的输出混在了一起。
8.10 exec Function
(看书之前可以看看这个youtube上的视频,对exec有个全貌认识:https://www.youtube.com/watch?v=mj2VjcOXXs4)
先看一下exec的描述:“When a process calls one of the exec functions, that process is completely replaced by the new program, and the new program starts executing at its main function. The process ID does not change across an exec, because a new process is not created; exec merely replaces the current process——its text, data, heap, and stack segments——with a brand-new program from disk”。
上面这个描述有点儿长,但实在说的很全面,一下子就让人明白exec与fork的区别了:
(1)fork的主体是从parent process执行copy的动作进而产生child process;而exec则是完全产生一个新的program,来代替原来的program,而且PID是不变的。
(2)调用fork()之后,parent和child都从fork()之后的代码段开始执行;而exec则是完全从头开始,即从main处开始执行。
exec只是一个统称,其实共有类型的exec可以供使用,根据后面加上不同的字母来区别:
(1)l:代表参数是以list形式提供的,即以逗号分隔各个变量,最后一个变量要是(char *)0
(2)v:代表参数是以vector形式提供的,argv[]这种形式的
(3)e:以e结尾代表定制传入的environ变量,最后多一个char *const envp[]参数;如果不以e结尾,就一股脑都把之前的environ给传进去了,最后不用有这个参数了
(4)p:代表传入filename,并且用PATH环境变量搜寻执行文件
上代码,看例子:
1 #include "apue.h" 2 #include <sys/wait.h> 3 #include <stdlib.h> 4 5 char *env_init[] = {"USER=unknown","PATH=/tmp",NULL}; 6 7 int main(void) 8 { 9 pid_t pid; 10 if ( (pid=fork()) < 0 ) 11 { 12 err_sys("fork error"); 13 } 14 else if ( pid==0 ) 15 { 16 if ( execle("./echoall", "echoall", "myarg1", "MY ARG2", (char *)0, env_init) < 0 ) 17 err_sys("execle error"); 18 } 19 20 if ( waitpid(pid, NULL, 0)<0 ) 21 err_sys("waitpid error"); 22 if ( (pid=fork()) < 0 ) 23 err_sys("fork error"); 24 else if ( pid==0 ) 25 { 26 /* 27 char *path = getenv("PATH"); 28 strcat(path,":."); 29 printf("current process‘s PATH : %s\n", path); 30 */ 31 if ( execlp("echoall","echoall","only 1 arg", (char *)0) < 0 ) 32 err_sys("execlp error"); 33 } 34 exit(0); 35 }
执行结果如下:
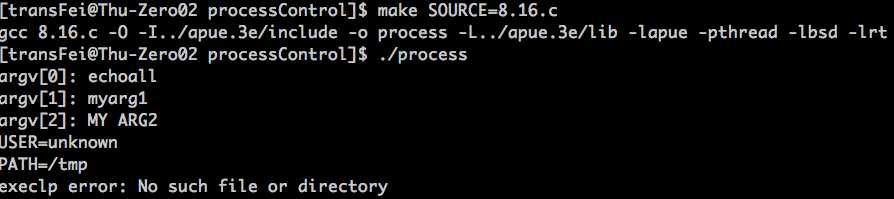
为什么提示No such file or directory呢?原因需要execlp执行的文件echoall并没有在环境变量PATH中找到。
echoall这个executable文件是在当前路径下,因此把当前路径加入到PATH中。
对代码做一下修改,把27 28 29三行代码的注释给消掉,再运行。
得到如下的结果:
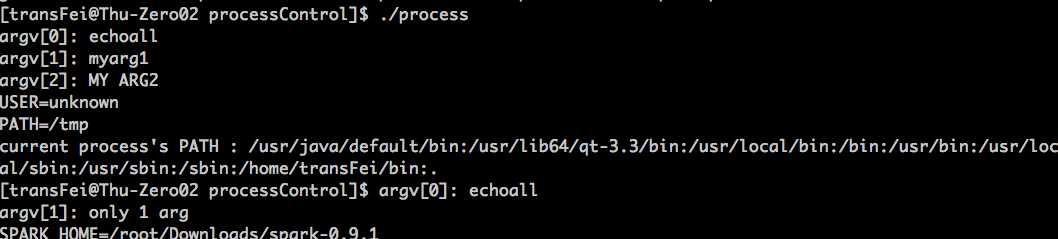
这里就看出来了在把当前路径加入到PATH中后,第二个child process中的execlp就可以正确执行了。
8.13 system Function
用于在C code中执行command-line string的。
“It is convenient to execute a command string from within a program”
8.14 Process Accounting
有人说Process Accounting是一种方言,就不看了。
8.16 Process Scheduling
1. 可以通过nice value来改变进程的优先级。顾名思义,nice value越大优先级越低,因为越nice越可以等别的process嘛;反之亦然。
2. int nice(int incr) 在原来的nice value基础上,增加incr这么多值(注意incr也可以是负的)
3. nice value是有范围的,超出最大值自动截取为最大值;小于最小值自动截取为最小值
4. nice function影响的只是当前的process,并不会影响到其他进程
下面上一段APUE书上的代码:
#include "apue.h" #include <errno.h> #include <sys/time.h> #if defined(MACOS) #include <sys/syslimits.h> #elif defined(SOLARIS) #include <limits.h> #elif defined(BSD) #include <sys/param.h> #endif unsigned long long count; struct timeval end; void checktime(char *str) { struct timeval tv; gettimeofday(&tv, NULL); if ( tv.tv_sec >= end.tv_sec && tv.tv_usec>=end.tv_usec ) { printf("%s count = %lld\n", str, count); exit(0); } } int main(int argc, char *argv[]) { pid_t pid; char *s; int nzero, ret; int adj = 0; setbuf(stdout,NULL); #if defined(NZERO) nzero = NZERO; #elif defined(_SC_NZERO) nzero = sysconf(_SC_NZERO); #else #error NZERO undefined #endif printf("NZERO = %d\n", nzero); if (argc == 2) adj = strtol(argv[1], NULL, 10); gettimeofday(&end, NULL); end.tv_sec += 10; // run for 10 seconds if ( (pid=fork()) < 0 ) { err_sys("fork failed"); } else if ( pid==0 ) { s = "chlid"; printf("current nice value in child is %d, adjusting by %d\n", nice(0)+nzero, adj); errno = 0; if ( (ret = nice(adj))==-1 && errno!=0 ) err_sys("child set scheduling priority"); printf("now child nice value is %d\n", ret+nzero); } else { s = "parent"; nice(-15); printf("current nice value in parent is %d\n", nzero-15); } for (;;) { if ( ++count == 0 ) { err_quit("%s counter wrap",s); } checktime(s); } }
上面代码的功能就是产生一个parent process再fork出来一个child process;然后parent和child在10秒的时间内,不断轮询,直到到10秒的时间限制。parent和child是并行的两个process,轮询是需要占用cpu资源的,是被kernel调度决定谁占用cpu的资源的。这里再用一个count来记录parent和child各自获得了轮询的次数是多少。手工提高parent的优先级(即降低nice value),并手工降低child的优先级(即提高nice value)。
然而,程序的运行结果却是下面的:
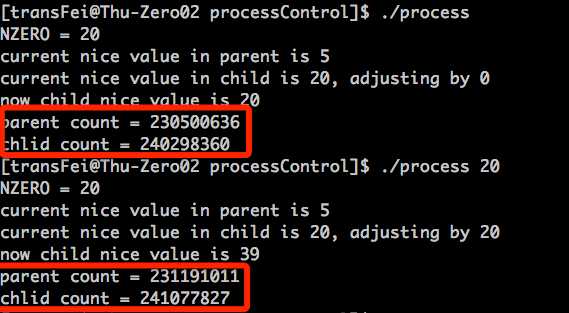
我们得到的结果却是,改不改nice value,对于parent和child获得轮询的次数没有啥影响。这是为啥呢?
又重新看了看书,发现了如下的话:“We run this on a uniprocessor Linux system to show how the scheduler shares the CPU among processes with different nice values”
似乎就是这个原因了,这段代码要想看出来结果的前提是uniprocessor,即单核CPU。
由于我的测试环境是一个12核的Server,而且是很闲的Server,自然不会有啥区别了。不过也算增强了一些认识吧。
8.17 Process Time
这里涉及到Unix系统的各种时间的概念:
1. Calendar time:人能看懂的时间,从1970.1.1 00:00开始到现在的时间,以秒为单位。(这个时间跟后面要提到的无关)
2. Process time:CPU执行某个进程的时间,也叫CPU time。process time的计量单位是clock ticks,一般来说,每秒产生的clock ticks有50 60 100不等,这个数值越高CPU的性能越高。
要想得到某台计算机的CPU每秒产生多少clock ticks的最靠谱的方式就调用函数:
clock_t t = sysconf(_SC_CLK_TCK);
(网上还有一种说法是用CLOCKS_PER_SEC来获得,这个方法不靠谱,因为这个宏就是一个固定值等于1000000)
在统计Process time的时候,要考虑下面三种时间:
1. Clock time 2. User CPU time 3. System CPU time
这三种时间都是啥意思呢?我在stackoverflow上搜到了这么一个答案(http://stackoverflow.com/questions/7335920/what-specifically-are-wall-clock-time-user-cpu-time-and-system-cpu-time-in-uni)
Wall-clock time is the time that a clock on the wall (or a stopwatch in hand) would measure as having elapsed between the start of the process and ‘now‘.
The user-cpu time and system-cpu time are pretty much as you said - the amount of time spent in user code and the amount of time spent in kernel code.
The wall-clock time is not the number of seconds that the process has spent on the CPU; it is the elapsed time, including time spent waiting for its turn on the CPU (while other processes get to run).
介绍完Unix系统时间的概念之后,怎么获得一个进程的上述几种时间呢?
在<sys/times.h>这个lib里面有个结构体和一个函数:
结构体:
struct tms{
clock_t tms_utime; // user cpu time
clock_t tms_stime; // system cpu time
clock_t tms_cutime; // user cpu time, terminated children
clock_t tms_cstime; // system cpu time, terminated children
}
函数:
clock_t times( struct tms *buf )
这样cpu time和system time在结构体中都有了,另外提到的clock time呢?这个clock time就作为times()函数的返回值回来了。这下就妥了,三种时间都可以统计了。
这里有一个坑,需要注意,无论是tms结构体中的值,还是times()函数返回来的值都是某种绝对值。因此,如果要获得某个进程的的上述三种时间,就得在执行开始的时候调用一次times()获得三种时间;再在执行结束的时候调用一次times()获得三种时间。取对应部分的差值,就是最终进程执行的三种时间。
注意,只要是clock_t的都是wall clock time,如果要想换算成人看得懂的时间,必须除以sysconf(_SC_CLK_TCK)才能转换成以秒为单位的时间。
最后上APUE书上的一段代码:
#include "apue.h" #include <sys/times.h> static void pr_times(clock_t, struct tms *, struct tms *); static void do_cmd(char *); int main(int argc, char *argv[]) { int i; setbuf(stdout, NULL); for (i = 1; i < argc; i++) do_cmd(argv[i]); /* once for each command-line arg */ exit(0); } static void do_cmd(char *cmd) /* execute and time the "cmd" */ { struct tms tmsstart, tmsend; clock_t start, end; int status; printf("\ncommand: %s\n", cmd); if ((start = times(&tmsstart)) == -1) /* starting values */ err_sys("times error"); if ((status = system(cmd)) < 0) /* execute command */ err_sys("system() error"); if ((end = times(&tmsend)) == -1) /* ending values */ err_sys("times error"); pr_times(end-start, &tmsstart, &tmsend); pr_exit(status); } static void pr_times(clock_t real, struct tms *tmsstart, struct tms *tmsend) { static long clktck = 0; if (clktck == 0) /* fetch clock ticks per second first time */ if ((clktck = sysconf(_SC_CLK_TCK)) < 0) err_sys("sysconf error"); printf(" real: %7.2f\n", real / (double) clktck); printf(" user: %7.2f\n", (tmsend->tms_utime - tmsstart->tms_utime) / (double) clktck); printf(" sys: %7.2f\n", (tmsend->tms_stime - tmsstart->tms_stime) / (double) clktck); printf(" child user: %7.2f\n", (tmsend->tms_cutime - tmsstart->tms_cutime) / (double) clktck); printf(" child sys: %7.2f\n", (tmsend->tms_cstime - tmsstart->tms_cstime) / (double) clktck); }
代码执行结果如下:
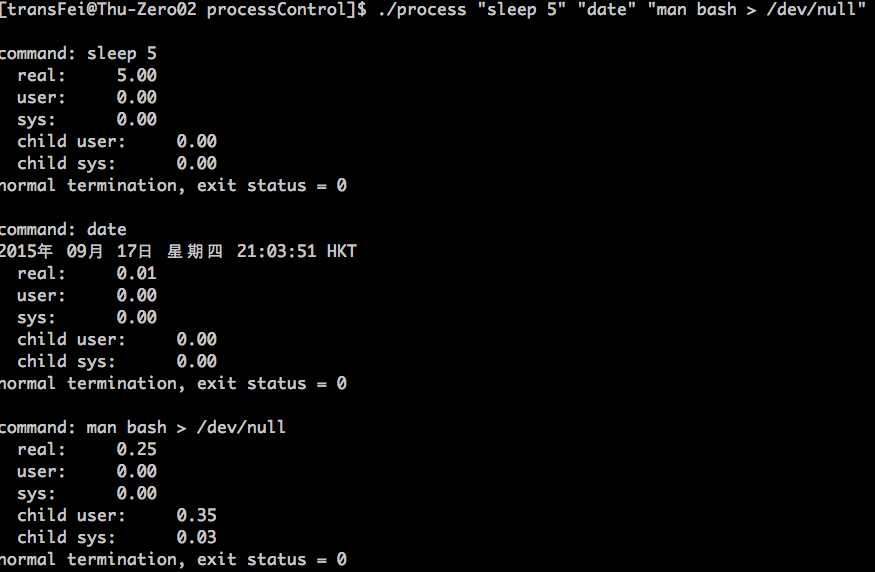
逐个进程分析:
1. 第一个命令是在子进程中执行“sleep 5”:进程总耗时是5秒,其中无论是parent或者是child的user time、system time都由于时间太短,没有被测出来。
2. 第二个命令式执行“date”:与第一个命令类似,这里的耗时0.01秒可能是进程等着的时间,真正执行上了,还是很短,无论是parent还是child都没有被记录下来。
3. 第三个命令是在child中执行“man bash > /dev/null”:奇怪的现象再次出现了,为什么process real time还小于child user time了?
这跟书上的结果是不同的,而且很奇怪:real < user + system了?这不合逻辑啊?
核心的原因是,书上的示例代码运行环境可能是单核系统,而自己的代码运行在server上,是multiprocessor的系统。因此这里面可能就会有多线程的隐形优化在里面。
就以上面的命令来说:man bash > /dev/null
这个man bash产生的文件大小是有360K的,我猜测执行这么‘大’一个文件的重定向,而且在我使用的server是12核的情况下,应该会有多线程的优化在里面。具体来说,比如有2个线程同时干这个事情,一个thread的user time是0.17,另一个thread的user time是0.18,但是在提交给user time的时候,就变成了0.17+0.18=0.35,即tms结构体中获得的user time。所以,还是符合逻辑的,real time依然大于user time,只不过由于多线程的隐形优化,就跟APUE书上的结果不同了。因此,遇到了与书上结果不一样了,就是学习知识的好机会了。
上面的参考了下面三个网页的内容(三篇内容结合在一起,就解释的很全面了):
http://yuanfarn.blogspot.jp/2012/08/linux-time.html
http://blog.csdn.net/nevasun/article/details/7004355
http://unix.stackexchange.com/questions/40694/why-real-time-can-be-lower-than-user-time
【APUE】Chapter8 Process Control
标签:
原文地址:http://www.cnblogs.com/xbf9xbf/p/4814746.html