一般来说,总共只有两种基本的数据访问途径:全扫描或者索引扫描。全扫描过程中,多个块被读入到一个IO运算中。索引扫描首先扫描索引叶子块以取得特定的行ID,然后利用这些行ID来访问父表取得实际的数据。
全扫描访问方法:当对一个对象进行扫描时,与改对象相关的所有数据块都必须取出并进行处理,以确定块中所包含的数据行是否是你的查询所需要的,Oracle必须将整个数据块读取到内存中以取得这个块中所存储的数据行的数据。当一个查询需要返回表中绝大多数的数据行时,选择使用全扫描的可能性当然也是最高的。
如何进行全扫描工作:
如果对于一个查询返回少数的数据行时,也会选择全表扫描。
创建两个测试表:
Eg:
create table t1 as
select trunc((rownum-1)/100) id,
rpad(rownum,100) t_pad
from dba_source
where rownum <= 10000;
create index t1_idx1 on t1(id);
exec dbms_stats.gather_table_stats(user,‘t1‘,method_opt=>‘FOR ALL COLUMNS SIZE 1‘,cascade=>TRUE);
create table t2 as
select mod(rownum,100) id,
rpad(rownum,100) t_pad
from dba_source
where rownum <= 10000;
create index t2_idx1 on t2(id);
exec dbms_stats.gather_table_stats(user,‘t2‘,method_opt=>‘FOR ALL COLUMNS SIZE 1‘,cascade=>TRUE);
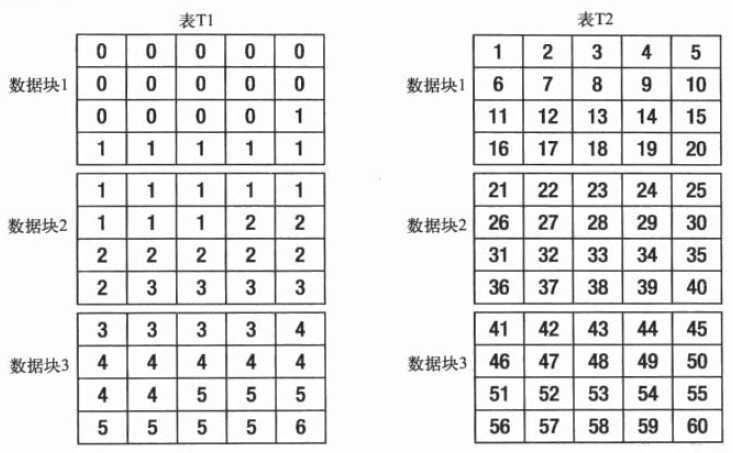
对于t1,t2都有10000行数据,两个表中的id列对于0-99的每个值都有100行,因此,从数据内容的角度来说,这2张表示一样的。但是对于t1,id列是通过trunc((rownum-1)/100)来计算的。而t2id列是通过MOD(rownum,100)计算。下图展示了数据块的存储情况。
运行聚合函数:
select count(*) ct from t1 where id = 1 ;
select count(*) ct from t2 where id = 1 ;
假设我们要找 id = 1 的值, 我们知道是100行, 而全表有10000行, 选择比是 100/10000 = 1%, 我们知道, 这个选择比很小, 优化器应该使用索引来得到数据, 因为我们已经在id列创建了索引, 但是此时, 我们应该了解一下数据是如何存储的, 如果数据时顺序存储的, 大多数的 id=1的行在物理上仅存储于几个数据块中, 如本例中t1那样, 那么这个结论是对的.(使用索引)
为什么优化器没有为这两个查询选择同样的解释计划呢 ? 这是因为在这两张表中数据的存储方式不同, 对于表 t1 的查询 oracle 仅需要访问很少的几个数据块来取得查询所需的 100行数据, 因此, 索引就是最具吸引力的选择, 但是, 由于表 t2 的数据行在物理上零散存储在该表的所有数据块中, 对于它的查询就需要读取几乎所有数据块来获取同样的 100 行数据. 优化器计算出使用索引来读取表中的每一个数据块的时间可能比直接使用全表扫描读取所有数据块要长.
全扫描访问方法:(1)如何选择全扫描操作,布布扣,bubuko.com
原文地址:http://www.cnblogs.com/HeiSe2014/p/3834977.html