标签:
尾调用的概念非常简单,一句话就能说清楚,就是指某个函数的最后一步是调用另一个函数。
function f(x) {returng(x);}
上面代码中,函数f的最后一步是调用函数g,这就叫尾调用。
以下两种情况,都不属于尾调用。
// 情况一 functionf(x) {let y =g(x);return y;} // 情况二 functionf(x) {returng(x)+1;}
上面代码中,情况一是调用函数g之后,还有别的操作,所以不属于尾调用,即使语义完全一样。情况二也属于调用后还有操作,即使写在一行内。
尾调用不一定出现在函数尾部,只要是最后一步操作即可。
functionf(x) {if(x >0){returnm(x)}returnn(x);}
上面代码中,函数m和n都属于尾调用,因为它们都是函数f的最后一步操作。
尾调用之所以与其他调用不同,就在于它的特殊的调用位置。
我们知道,函数调用会在内存形成一个"调用记录",又称"调用帧"(call frame),保存调用位置和内部变量等信息。如果在函数A的内部调用函数B,那么在A的调用记录上方,还会形成一个B的调用记录。等到B运行结束,将结果返回到A,B的调用记录才会消失。如果函数B内部还调用函数C,那就还有一个C的调用记录栈,以此类推。所有的调用记录,就形成一个"调用栈"(call stack)。
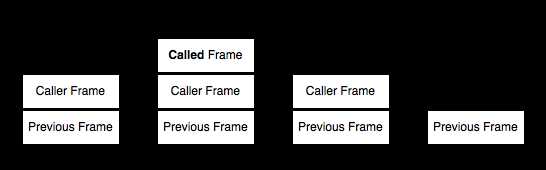
尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用记录,因为调用位置、内部变量等信息都不会再用到了,只要直接用内层函数的调用记录,取代外层函数的调用记录就可以了。
function f(){let m =1;let n =2;return g(m + n);}f(); // 等同于 function f() {return g(3);}f(); // 等同于 g(3);
上面代码中,如果函数g不是尾调用,函数f就需要保存内部变量m和n的值、g的调用位置等信息。但由于调用g之后,函数f就结束了,所以执行到最后一步,完全可以删除 f() 的调用记录,只保留 g(3) 的调用记录。
这就叫做"尾调用优化"(Tail call optimization),即只保留内层函数的调用记录。如果所有函数都是尾调用,那么完全可以做到每次执行时,调用记录只有一项,这将大大节省内存。这就是"尾调用优化"的意义。
函数调用自身,称为递归。如果尾调用自身,就称为尾递归。
递归非常耗费内存,因为需要同时保存成千上百个调用记录,很容易发生"栈溢出"错误(stack overflow)。但对于尾递归来说,由于只存在一个调用记录,所以永远不会发生"栈溢出"错误。
function factorial(n){ if(n ===1){ return1; } return n *factorial(n -1); } factorial(5) // 120 function factorial(n, total){ if(n ===1) return total; return factorial(n -1, n * total); } factorial(5,1) // 120
上面代码是一个阶乘函数,计算n的阶乘,最多需要保存n个调用记录,复杂度 O(n) 。
如果改写成尾递归,只保留一个调用记录,复杂度 O(1) 。
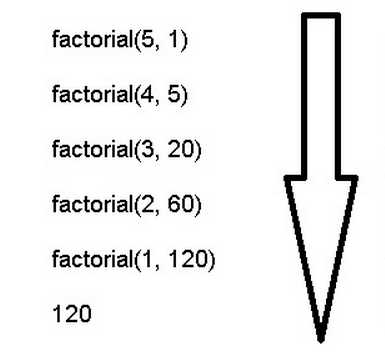
由此可见,"尾调用优化"对递归操作意义重大,所以一些函数式编程语言将其写入了语言规格。ES6也是如此,第一次明确规定,所有 ECMAScript 的实现,都必须部署"尾调用优化"。这就是说,在 ES6 中,只要使用尾递归,就不会发生栈溢出,相对节省内存。
尾递归的实现,往往需要改写递归函数,确保最后一步只调用自身。做到这一点的方法,就是把所有用到的内部变量改写成函数的参数。比如上面的例子,阶乘函数 factorial 需要用到一个中间变量 total ,那就把这个中间变量改写成函数的参数。这样做的缺点就是不太直观,第一眼很难看出来,为什么计算5的阶乘,需要传入两个参数5和1?
两个方法可以解决这个问题。方法一是在尾递归函数之外,再提供一个正常形式的函数。
function tailFactorial(n, total) { if(n ===1) return total; return tailFactorial(n -1, n * total); } function factorial(n) { return tailFactorial(n,1); } factorial(5) // 120
上面代码通过一个正常形式的阶乘函数 factorial ,调用尾递归函数 tailFactorial ,看起来就正常多了。
函数式编程有一个概念,叫做柯里化(currying),意思是将多参数的函数转换成单参数的形式。这里也可以使用柯里化。
function currying(fn, n) { return function(m){ return fn.call(this, m, n); }; } function tailFactorial(n, total) { if(n ===1) return total; return tailFactorial(n -1, n * total); } const factorial = currying(tailFactorial,1); factorial(5) // 120
上面代码通过柯里化,将尾递归函数 tailFactorial 变为只接受1个参数的 factorial 。
第二种方法就简单多了,就是采用ES6的函数默认值。
function factorial(n, total =1) {if(n ===1)return total;returnfactorial(n -1, n * total);}factorial(5) // 120
上面代码中,参数 total 有默认值1,所以调用时不用提供这个值。
总结一下,递归本质上是一种循环操作。纯粹的函数式编程语言没有循环操作命令,所有的循环都用递归实现,这就是为什么尾递归对这些语言极其重要。对于其他支持"尾调用优化"的语言(比如Lua,ES6),只需要知道循环可以用递归代替,而一旦使用递归,就最好使用尾递归。
Tail-call optimization is where you are able to avoid allocating a new stack frame for a function because the calling function will simply return the value that it gets from the called function. The most common use is tail-recursion, where a recursive function written to take advantage of tail-call optimization can use constant stack space.
Scheme is one of the few programming languages that guarantee in the spec that any implementation must provide this optimization (JavaScript will also, once ES6 is finalized), so here are two examples of the factorial function in Scheme:
(define(fact x)(if(= x 0)1(* x (fact (- x 1)))))(define(fact x)(define(fact-tail x accum)(if(= x 0) accum
(fact-tail (- x 1)(* x accum))))(fact-tail x 1))The first function is not tail recursive because when the recursive call is made, the function needs to keep track of the multiplication it needs to do with the result after the call returns. As such, the stack looks as follows:
(fact 3)(*3(fact 2))(*3(*2(fact 1)))(*3(*2(*1(fact 0))))(*3(*2(*11)))(*3(*21))(*32)6In contrast, the stack trace for the tail recursive factorial looks as follows:
(fact 3)(fact-tail 31)(fact-tail 23)(fact-tail 16)(fact-tail 06)6As you can see, we only need to keep track of the same amount of data for every call to fact-tail because we are simply returning the value we get right through to the top. This means that even if I were to call (fact 1000000), I need only the same amount of space as (fact 3). This is not the case with the non-tail-recursive fact, and as such large values may cause a stack overflow.
标签:
原文地址:http://www.cnblogs.com/abapscript/p/4820202.html