标签:
在前文中,我们有看到,数据发送的过程,大体是发送者CUDT将要发送的数据放进它的CSndBuffer m_pSndBuffer,并将它自己添加进它的CSndQueue m_pSndQueue的CSndUList m_pSndUList的堆里,后面CSndQueue m_pSndQueue的worker线程会通过CSndUList::pop()从CSndUList m_pSndUList的堆顶CUDT中获取一个要发送的包来发送,包的获取主要是通过CUDT::packData()来完成,而这个函数正是UDT中包发送的执行中心。
这里就来看一下CUDT::packData()的定义(src/core.cpp):
int CUDT::packData(CPacket& packet, uint64_t& ts) {
int payload = 0;
bool probe = false;
uint64_t entertime;
CTimer::rdtsc(entertime);
if ((0 != m_ullTargetTime) && (entertime > m_ullTargetTime))
m_ullTimeDiff += entertime - m_ullTargetTime;
// Loss retransmission always has higher priority.
if ((packet.m_iSeqNo = m_pSndLossList->getLostSeq()) >= 0) {
// protect m_iSndLastDataAck from updating by ACK processing
CGuard ackguard(m_AckLock);
int offset = CSeqNo::seqoff(m_iSndLastDataAck, packet.m_iSeqNo);
if (offset < 0)
return 0;
int msglen;
payload = m_pSndBuffer->readData(&(packet.m_pcData), offset, packet.m_iMsgNo, msglen);
if (-1 == payload) {
int32_t seqpair[2];
seqpair[0] = packet.m_iSeqNo;
seqpair[1] = CSeqNo::incseq(seqpair[0], msglen);
sendCtrl(7, &packet.m_iMsgNo, seqpair, 8);
// only one msg drop request is necessary
m_pSndLossList->remove(seqpair[1]);
// skip all dropped packets
if (CSeqNo::seqcmp(m_iSndCurrSeqNo, CSeqNo::incseq(seqpair[1])) < 0)
m_iSndCurrSeqNo = CSeqNo::incseq(seqpair[1]);
return 0;
} else if (0 == payload)
return 0;
++m_iTraceRetrans;
++m_iRetransTotal;
} else {
// If no loss, pack a new packet.
// check congestion/flow window limit
int cwnd = (m_iFlowWindowSize < (int) m_dCongestionWindow) ? m_iFlowWindowSize : (int) m_dCongestionWindow;
if (cwnd >= CSeqNo::seqlen(m_iSndLastAck, CSeqNo::incseq(m_iSndCurrSeqNo))) {
if (0 != (payload = m_pSndBuffer->readData(&(packet.m_pcData), packet.m_iMsgNo))) {
m_iSndCurrSeqNo = CSeqNo::incseq(m_iSndCurrSeqNo);
m_pCC->setSndCurrSeqNo(m_iSndCurrSeqNo);
packet.m_iSeqNo = m_iSndCurrSeqNo;
// every 16 (0xF) packets, a packet pair is sent
if (0 == (packet.m_iSeqNo & 0xF))
probe = true;
} else {
m_ullTargetTime = 0;
m_ullTimeDiff = 0;
ts = 0;
return 0;
}
} else {
m_ullTargetTime = 0;
m_ullTimeDiff = 0;
ts = 0;
return 0;
}
}
packet.m_iTimeStamp = int(CTimer::getTime() - m_StartTime);
packet.m_iID = m_PeerID;
packet.setLength(payload);
m_pCC->onPktSent(&packet);
//m_pSndTimeWindow->onPktSent(packet.m_iTimeStamp);
++m_llTraceSent;
++m_llSentTotal;
if (probe) {
// sends out probing packet pair
ts = entertime;
probe = false;
} else {
#ifndef NO_BUSY_WAITING
ts = entertime + m_ullInterval;
#else
if (m_ullTimeDiff >= m_ullInterval) {
ts = entertime;
m_ullTimeDiff -= m_ullInterval;
} else {
ts = entertime + m_ullInterval - m_ullTimeDiff;
m_ullTimeDiff = 0;
}
#endif
}
m_ullTargetTime = ts;
return payload;
}
在这个函数中,处理了两大类packet的读取,一是丢失的packet,二是正常的顺序传输的包。来看一下这个函数具体的执行过程:
1. 读取当前的时间entertime。
2. 更新m_ullTimeDiff。在UDT中,包发送会有一个随着网络状况调整的一个发送周期,也就是m_ullInterval值。在每一次发送包时,都会根据m_ullInterval值计算下一次包发送的理想时间,并记录在m_ullTargetTime中。而m_ullTimeDiff则被用来记录当前的这次包发送想对于理想的发送时间的延滞值,这个值会被用于计算下一次包发送的理想时间。UDT正是通过这样的修正来尽可能使的包发送周期能够保持在m_ullInterval值附近。
3. 从丢失包列表m_pSndLossList中获取一个丢失的包的SeqNo,并赋值给packet.m_iSeqNo。这个丢失包列表中的包可能是来源于Timer,比如一个包超过了正常时间还没有得到响应,也有可能来源于发送端发回的NACK消息,后面会在来研究这个问题。
4. 前一步中获取的SeqNo大于等于0,这表明存在丢失了需要重传的包,则读取丢失的包的内容:
(1). 计算丢失的包的SeqNo与SndLastDataAck的差值offset。
(2). 检查前一步计算出来的offset值,若小于0,表明发送窗口已经滑过了,则直接返回,否则继续执行。
(3). 根据前面计算的offset值,通过m_pSndBuffer->readData()把数据读入packet中。packet的m_iMsgNo会被更新为packet的MsgNo,msglen也会在packet过期时被更新。
(4). m_pSndBuffer->readData()返回0,表明读取的packet的数据长度为0。这样的packet没有实际发送的必要,直接返回,无需进行后续的步骤。
(5). m_pSndBuffer->readData()返回-1,表明要读取的packet已经过期,同样没有发送这个数据包本身的必要。
但此时会发送一个DropMsgRequest给数据接收端。
然后将过期的packet从SndLossList中移除出去。
m_iSndCurrSeqNo的值为最近一次发送的packet的SeqNo,这里还会在必要的时候更新m_iSndCurrSeqNo,以跳过所有被丢弃的packets。必要指的是,m_iSndCurrSeqNo的值小于等于要丢弃的这个Msg的最后一个packet的SeqNo。这也就意味着,要丢弃的这个Msg直到过期被丢弃都没有发完。
这个地方有一点比较奇怪,简化来看,seqpair[0] == packet.m_iSeqNo,seqpair[1] == seqpair[0] + msglen,也就是说seqpair[1]的值为要被丢弃Msg的最后一个packet的SeqNo加1,但在判断是否要更新m_iSndCurrSeqNo时,却是拿m_iSndCurrSeqNo和(seqpair[1] + 1),也就是要被丢弃的Msg的最后一个packet的SeqNo加2在比较,而更新也是被设置为这个值。但实际上,将m_iSndCurrSeqNo设置为被丢弃Msg的最后一个packet的SeqNo已经可以跳过整个Msg的发送了,因为下次要用m_iSndCurrSeqNo来获得SeqNo,会先将这个值加1的。这个地方的逻辑疑似存在bug。
返回0,向调用者表明暂时没有数据要发送。
(6). m_pSndBuffer->readData()返回大于0的值,表明有一个丢失的包需要重新发送,则更新m_iTraceRetrans和m_iRetransTotal,这两个值分别表示一次trace重发的总次数,和此UDT Socket总的重发次数,两者的区别在于前者在被读取之后会被重置为0(CUDT::sample()),而后者则不会。此时需要继续执行后面的第6步。
5. 在第3步中读取的SeqNo小于0,表明没有丢失的packet。此时则:
(1). 根据m_iFlowWindowSize和m_dCongestionWindow的值计算cwnd发送窗口的大小。发送窗口大小取这两个值中较小的那个,默认情况下,前者为8192(来自于Handshke消息的m_iFlightFlagSize字段,而m_iFlightFlagSize则根据m_iRcvBufSize和m_iFlightFlagSize得出),后者为16(来自于CC的m_dCWndSize字段,在CUDTCC::init()中该值被初始化为16。)。
(2). 检查发送窗口是否已满。若已满,则将m_ullTargetTime和m_ullTimeDiff重置为0,将ts置为0,然后返回0,向调用者表明没有数据要发送。否则继续执行。
m_iSndLastAck的值为下一次Ack应该确认的packet的SeqNo,CSeqNo::seqlen()计算的是包含两个端点在内的区间的长度。此处对CSeqNo::seqlen()的调用被用来计算,下个packet发送之后,发送窗口中所有的packet的个数。
(3). 读取下一个需要发送的packet,并检查返回的payload值。若payload值为0,表明数据缓冲区中所有的数据都已经发送了,无需再进行实际的发送,则将m_ullTargetTime和m_ullTimeDiff重置为0,将ts置为0,返回0,向调用者表明没有数据要发送。否则继续执行。
(4). 主要是更新m_iSndCurrSeqNo,并设置packet的SeqNo字段。如果SeqNo为16的整数倍,还会设置probe为true。
6. 设置packet的m_iTimeStamp,m_iID,及数据长度。
7. 更新m_llTraceSent和m_llSentTotal,其中前者表示CUDT这次Trace的过程中发送的总的packet数量,这个值会在CUDT::sample()获取trace数据之后被重置为0,而后者则表示发送的总共的packet数量,不会在CUDT::sample()获取trace数据之后被重置。
8. 根据probe的值,更新ts值等。配 合CUDT::packData()的调用者CSndUList::pop()一起看,可知ts是理想中该CUDT下次发送数据的时间点。
probe设置为true,就是表明,当前的这个packet被发送结束之后立即发送下一个packet。即使probe的值不为true,也有可能要立即发送下一个packet,比如延滞时间已经超过了理想的发生周期。存在延滞时间,但该延滞时间又没有超出理想的发送周期的,则下个packet的发送时间具体本次packet的发送时间会小于理想的packet发送周期。
总之这里是希望能够保持packet以接近理想的速率发送。
9. 更新m_ullTargetTime为ts。ts这个下次发包的理想时间点还需要m_ullTargetTime进行记录。
10. 返回payload值,也就是读取的packet的大小。
这里顺便来看下CSeqNo的设计与实现。这个类被用来帮助进行与SeqNo有关的一些计算(src/common.h):
class CSeqNo {
public:
inline static int seqcmp(int32_t seq1, int32_t seq2) {
return (abs(seq1 - seq2) < m_iSeqNoTH) ? (seq1 - seq2) : (seq2 - seq1);
}
inline static int seqlen(int32_t seq1, int32_t seq2) {
return (seq1 <= seq2) ? (seq2 - seq1 + 1) : (seq2 - seq1 + m_iMaxSeqNo + 2);
}
inline static int seqoff(int32_t seq1, int32_t seq2) {
if (abs(seq1 - seq2) < m_iSeqNoTH)
return seq2 - seq1;
if (seq1 < seq2)
return seq2 - seq1 - m_iMaxSeqNo - 1;
return seq2 - seq1 + m_iMaxSeqNo + 1;
}
inline static int32_t incseq(int32_t seq) {
return (seq == m_iMaxSeqNo) ? 0 : seq + 1;
}
inline static int32_t decseq(int32_t seq) {
return (seq == 0) ? m_iMaxSeqNo : seq - 1;
}
inline static int32_t incseq(int32_t seq, int32_t inc) {
return (m_iMaxSeqNo - seq >= inc) ? seq + inc : seq - m_iMaxSeqNo + inc - 1;
}
public:
static const int32_t m_iSeqNoTH; // threshold for comparing seq. no.
static const int32_t m_iMaxSeqNo; // maximum sequence number used in UDT
};
连接发起端在执行CUDT::connect(const sockaddr* serv_addr)时,会计算一个随机的值作为m_iISN,也即是发送的首个数据packet的SeqNo,而在连接建立过程中,这个值会被同步给Peer端的Socket。
这里可以看到,UDT Packet的SeqNo是[0, 0x7FFFFFFF]区间中的一个值。每发送一个packet,m_iSndCurrSeqNo都会被递增。通过class CSeqNo可以看到这个递增的规则,即SeqNo超出0x7FFFFFFF时会被归0。也正是由于0是一个合法的SeqNo,在incseq(int32_t seq, int32_t inc)中,SeqNo超出最大值时的计算里能看到有额外的减1,在seqlen()里,SeqNo超出最大值时的计算里能看到加2。
由seqcmp()和seqoff()这两个函数可见,同一时刻同时有效的两个SeqNo seq1和seq2之间的距离不能超过m_iSeqNoTH 0x3FFFFFFF,若超过则表明一定有一个SeqNo越过了最大值0x7FFFFFFF,也即较小的那个值越过了最大值。
这里还可以再来看一下CSndBuffer::readData():
int CSndBuffer::readData(char** data, int32_t& msgno) {
// No data to read
if (m_pCurrBlock == m_pLastBlock)
return 0;
*data = m_pCurrBlock->m_pcData;
int readlen = m_pCurrBlock->m_iLength;
msgno = m_pCurrBlock->m_iMsgNo;
m_pCurrBlock = m_pCurrBlock->m_pNext;
return readlen;
}
int CSndBuffer::readData(char** data, const int offset, int32_t& msgno, int& msglen) {
CGuard bufferguard(m_BufLock);
Block* p = m_pFirstBlock;
for (int i = 0; i < offset; ++i)
p = p->m_pNext;
if ((p->m_iTTL >= 0) && ((CTimer::getTime() - p->m_OriginTime) / 1000 > (uint64_t) p->m_iTTL)) {
msgno = p->m_iMsgNo & 0x1FFFFFFF;
msglen = 1;
p = p->m_pNext;
bool move = false;
while (msgno == (p->m_iMsgNo & 0x1FFFFFFF)) {
if (p == m_pCurrBlock)
move = true;
p = p->m_pNext;
if (move)
m_pCurrBlock = p;
msglen++;
}
return -1;
}
*data = p->m_pcData;
int readlen = p->m_iLength;
msgno = p->m_iMsgNo;
return readlen;
}
CSndBuffer::readData(char** data, int32_t& msgno)读取当前的Block。基本上就是读取Block,然后将指向当前Block的指针m_pCurrBlock向后移一个Block。
而CSndBuffer::readData(char** data, const int offset, int32_t& msgno, int& msglen)则是读取距未响应的Block中最旧一块Block offset个单位的Block。在这个函数中,首先是移动到要读取的目标Block,如果要读取的Block已过期,则使m_pCurrBlock跳过该packet所属的Msg的所有Packet,然后返回-1退出。目标Block没有过期,则读取Block后返回数据长度。
总结在CUDT::packData()中对发送过程的控制。
丢失的包具有最高的发送优先级,这也是发送可靠性的保障方法。所有丢失的packet都会被放进SndLossList,这个List中的包可能来源于超时未得到响应,也可能来源于消息接收端发回的NACK。
对于正常的顺序packet发送的控制主要在于两个方面,一是发送窗口的大小,也就是某个时刻已经发送但未得到相应的packet的最大个数,这一点主要由m_dCongestionWindow和m_iFlowWindowSize来表示;二是控制两个包发送的时间间隔,也就是包的发送速率,这一点则主要用m_ullInterval来表示。所有的发送控制机制主要通过影响这几个变量来控制发送过程。
接着就来看一下UDT中数据发送的可靠性保障。
先来看一下CSndLossList这个数据结构。这个Class的定义如下(src/list.h):
class CSndLossList {
public:
CSndLossList(int size = 1024);
~CSndLossList();
// Functionality:
// Insert a seq. no. into the sender loss list.
// Parameters:
// 0) [in] seqno1: sequence number starts.
// 1) [in] seqno2: sequence number ends.
// Returned value:
// number of packets that are not in the list previously.
int insert(int32_t seqno1, int32_t seqno2);
// Functionality:
// Remove ALL the seq. no. that are not greater than the parameter.
// Parameters:
// 0) [in] seqno: sequence number.
// Returned value:
// None.
void remove(int32_t seqno);
// Functionality:
// Read the loss length.
// Parameters:
// None.
// Returned value:
// The length of the list.
int getLossLength();
// Functionality:
// Read the first (smallest) loss seq. no. in the list and remove it.
// Parameters:
// None.
// Returned value:
// The seq. no. or -1 if the list is empty.
int32_t getLostSeq();
private:
int32_t* m_piData1; // sequence number starts
int32_t* m_piData2; // seqnence number ends
int* m_piNext; // next node in the list
int m_iHead; // first node
int m_iLength; // loss length
int m_iSize; // size of the static array
int m_iLastInsertPos; // position of last insert node
pthread_mutex_t m_ListLock; // used to synchronize list operation
private:
CSndLossList(const CSndLossList&);
CSndLossList& operator=(const CSndLossList&);
};
这是一个不可复制容器。提供的接口不是很多,配合注释,都没有太多难以理解的地方。这是一个用数组实现的链表。接着来看这个class的构造和析构(src/list.cpp):
CSndLossList::CSndLossList(int size)
: m_piData1(NULL),
m_piData2(NULL),
m_piNext(NULL),
m_iHead(-1),
m_iLength(0),
m_iSize(size),
m_iLastInsertPos(-1),
m_ListLock() {
m_piData1 = new int32_t[m_iSize];
m_piData2 = new int32_t[m_iSize];
m_piNext = new int[m_iSize];
// -1 means there is no data in the node
for (int i = 0; i < size; ++i) {
m_piData1[i] = -1;
m_piData2[i] = -1;
}
// sender list needs mutex protection
#ifndef WIN32
pthread_mutex_init(&m_ListLock, 0);
#else
m_ListLock = CreateMutex(NULL, false, NULL);
#endif
}
CSndLossList::~CSndLossList() {
delete[] m_piData1;
delete[] m_piData2;
delete[] m_piNext;
#ifndef WIN32
pthread_mutex_destroy(&m_ListLock);
#else
CloseHandle(m_ListLock);
#endif
}
CUDT::connect()中创建CSndLossList时,size值为m_iFlowWindowSize * 2,也即8192 × 2 == 16384。如果不用数组,而用常规一点的方法来实现的话,链表的节点定义可能是这样的:
struct Node {
int32_t m_iStart;
int32_t m_iEnd;
Node *m_pNext;
};
然后来看这个class最关键的函数之一CSndLossList::insert()的定义:
int CSndLossList::insert(int32_t seqno1, int32_t seqno2) {
CGuard listguard(m_ListLock);
if (0 == m_iLength) {
// insert data into an empty list
m_iHead = 0;
m_piData1[m_iHead] = seqno1;
if (seqno2 != seqno1)
m_piData2[m_iHead] = seqno2;
m_piNext[m_iHead] = -1;
m_iLastInsertPos = m_iHead;
m_iLength += CSeqNo::seqlen(seqno1, seqno2);
return m_iLength;
}
// otherwise find the position where the data can be inserted
int origlen = m_iLength;
int offset = CSeqNo::seqoff(m_piData1[m_iHead], seqno1);
int loc = (m_iHead + offset + m_iSize) % m_iSize;
if (offset < 0) {
// Insert data prior to the head pointer
m_piData1[loc] = seqno1;
if (seqno2 != seqno1)
m_piData2[loc] = seqno2;
// new node becomes head
m_piNext[loc] = m_iHead;
m_iHead = loc;
m_iLastInsertPos = loc;
m_iLength += CSeqNo::seqlen(seqno1, seqno2);
} else if (offset > 0) {
if (seqno1 == m_piData1[loc]) {
m_iLastInsertPos = loc;
// first seqno is equivlent, compare the second
if (-1 == m_piData2[loc]) {
if (seqno2 != seqno1) {
m_iLength += CSeqNo::seqlen(seqno1, seqno2) - 1;
m_piData2[loc] = seqno2;
}
} else if (CSeqNo::seqcmp(seqno2, m_piData2[loc]) > 0) {
// new seq pair is longer than old pair, e.g., insert [3, 7] to [3, 5], becomes [3, 7]
m_iLength += CSeqNo::seqlen(m_piData2[loc], seqno2) - 1;
m_piData2[loc] = seqno2;
} else
// Do nothing if it is already there
return 0;
} else {
// searching the prior node
int i;
if ((-1 != m_iLastInsertPos) && (CSeqNo::seqcmp(m_piData1[m_iLastInsertPos], seqno1) < 0))
i = m_iLastInsertPos;
else
i = m_iHead;
while ((-1 != m_piNext[i]) && (CSeqNo::seqcmp(m_piData1[m_piNext[i]], seqno1) < 0))
i = m_piNext[i];
if ((-1 == m_piData2[i]) || (CSeqNo::seqcmp(m_piData2[i], seqno1) < 0)) {
m_iLastInsertPos = loc;
// no overlap, create new node
m_piData1[loc] = seqno1;
if (seqno2 != seqno1)
m_piData2[loc] = seqno2;
m_piNext[loc] = m_piNext[i];
m_piNext[i] = loc;
m_iLength += CSeqNo::seqlen(seqno1, seqno2);
} else {
m_iLastInsertPos = i;
// overlap, coalesce with prior node, insert(3, 7) to [2, 5], ... becomes [2, 7]
if (CSeqNo::seqcmp(m_piData2[i], seqno2) < 0) {
m_iLength += CSeqNo::seqlen(m_piData2[i], seqno2) - 1;
m_piData2[i] = seqno2;
loc = i;
} else
return 0;
}
}
} else {
m_iLastInsertPos = m_iHead;
// insert to head node
if (seqno2 != seqno1) {
if (-1 == m_piData2[loc]) {
m_iLength += CSeqNo::seqlen(seqno1, seqno2) - 1;
m_piData2[loc] = seqno2;
} else if (CSeqNo::seqcmp(seqno2, m_piData2[loc]) > 0) {
m_iLength += CSeqNo::seqlen(m_piData2[loc], seqno2) - 1;
m_piData2[loc] = seqno2;
} else
return 0;
} else
return 0;
}
// coalesce with next node. E.g., [3, 7], ..., [6, 9] becomes [3, 9]
while ((-1 != m_piNext[loc]) && (-1 != m_piData2[loc])) {
int i = m_piNext[loc];
if (CSeqNo::seqcmp(m_piData1[i], CSeqNo::incseq(m_piData2[loc])) <= 0) {
// coalesce if there is overlap
if (-1 != m_piData2[i]) {
if (CSeqNo::seqcmp(m_piData2[i], m_piData2[loc]) > 0) {
if (CSeqNo::seqcmp(m_piData2[loc], m_piData1[i]) >= 0)
m_iLength -= CSeqNo::seqlen(m_piData1[i], m_piData2[loc]);
m_piData2[loc] = m_piData2[i];
} else
m_iLength -= CSeqNo::seqlen(m_piData1[i], m_piData2[i]);
} else {
if (m_piData1[i] == CSeqNo::incseq(m_piData2[loc]))
m_piData2[loc] = m_piData1[i];
else
m_iLength--;
}
m_piData1[i] = -1;
m_piData2[i] = -1;
m_piNext[loc] = m_piNext[i];
} else
break;
}
return m_iLength - origlen;
}
1. 这个函数首先处理了最简单的向空链表中插入元素的case。
这种情况下,m_iHead被赋予0值。m_piData1[m_iHead]会被赋值为要插入的这段丢失packet范围的起始SeqNo。
如果起始SeqNo和结束SeqNo的值不同,m_piData2[m_iHead]还会被赋值为结束SeqNo;如果相同,则m_piData2[m_iHead]将仍然保持构造函数中初始化的-1,以表示这段丢失packet范围只有一个元素。
m_piNext[m_iHead]被赋值为-1以表示这是链表中的最后一个元素。m_iLastInsertPos用来记录上一次插入的位置,这里会被赋值为m_iHead。m_iLength表示CSndLossList中记录的丢失packet的总格数,这里会被设置为这段packet的长度。然后返回m_iLength。
可见m_iHead指向链表的头部。m_piData1,m_piData2和m_piNext这三个数组中相同位置的元素共同表示一个链表节点,它们分别表示一个丢失packet范围的起始SeqNo,结束SeqNo和该节点在链表中next节点的位置。
2. 链表中已经有元素了,则将m_iLength保存在origlen中。计算要插入的这段丢失packet的起始SeqNo与链表中原有的头节点的起始SeqNo字段的差值offset。然后计算要插入的这段丢失packet范围的的可能的位置loc,这个可能的位置主要由这段丢失packet范围的起始SeqNo与链表中原有的头节点的起始SeqNo字段的差值决定。
由loc的计算方法可见,数组中的空间是被循环利用的。比如要插入的节点是向CSndLossList中插入的第二个节点,则此时m_iHead仍然为0,而要插入的这个丢失packet范围的起始位置小于原有的头节点的起始SeqNo字段,则新插入的节点将被绕回到数组的尾部。
3. 处理offset小于0的情况。这表示插入的这个丢失packet范围的起始位置小于原有的头节点的起始SeqNo字段值,此时则会在loc位置插入一个新的节点以描述这段丢失packet范围。更新m_iHead和m_iLastInsertPos指向新插入的这个节点。并更新m_iLength以体现新加入的这个丢失packet范围。
向单向链表的头部插入元素总是比较简单。由此我们也看到,这个链表是以节点的起始SeqNo字段值的升序排列的有序链表。
但这个地方貌似没有处理新插入的这个丢失packet范围与原有头节点表示的丢失packet范围存在交叉的情况?没错,是没有处理,这种情况会在处理完所有的插入情况之后再统一来做。
4. 处理offset大于0的情况。这又分为两种情况:
(1). seqno1 == m_piData1[loc],表明新节点的目标插入位置中原有节点保存的丢失Packet范围的起始SeqNo与要插入的这个丢失Packets范围的起始SeqNo相同。则此时会首先更新m_iLastInsertPos为loc,还需要处理这样的几种case,
case 1:原有的范围中只有一个元素,要插入的这个范围有多个元素。
case 2:原有的范围中有多个元素,要插入的这个范围有一个元素。
case 3:原有的范围和要插入的范围都只有一个元素。
case 4:原有的范围和要插入的范围中都有多个元素,但新插入的范围完全包含原有的范围。
case 5:原有的范围和要插入的范围中都有多个元素,但原有的范围完全包含新插入的范围。
case 6:原有的范围和要插入的范围中都有多个元素,且完全相同。
这些case包含的packet范围的相对关系可以用下图来简单表示:

代码的具体写法不同,这些case中的一些可能会以不同的方式被合并成一个处理,而有些case则不需要对原有的链表进行任何的调整。
if block中处理的是case1和case3,else-if block中处理的是case 4,else block中处理的是case 2,case 5和case 6。其中case 3,case 2,case 5和case 6都不需要对链表做出调整。
以此来看,在第一个if block的内部,应该再加一个else block来直接返回0会比较好一点。
那段代码的一种等价实现形式:
if (seqno2 != seqno1) {
if (-1 == m_piData2[loc]) {
m_iLength += CSeqNo::seqlen(seqno1, seqno2) - 1;
m_piData2[loc] = seqno2;
} else if (CSeqNo::seqcmp(seqno2, m_piData2[loc]) > 0) {
// new seq pair is longer than old pair, e.g., insert [3, 7] to [3, 5], becomes [3, 7]
m_iLength += CSeqNo::seqlen(m_piData2[loc], seqno2) - 1;
m_piData2[loc] = seqno2;
} else {
return 0;
}
} else {
// Do nothing if it is already there
return 0;
}
(2). seqno1与m_piData1[loc]不相等。这其实主要有两种可能,一是loc位置已经有了其它的节点,但该节点所表示的范围的起始SeqNo与要插入的这个范围的起始SeqNo不同;二是loc位置还没有被插入节点。但第一种可能应该是不会出现的,因而这里实际要处理的也就是loc位置还没有节点插入的情况。
对于这种情况,节点的插入位置完全不是问题,关键的问题是调整链表中一些节点的关系。可以看到这里的处理过程:
查找新插入节点前面的那个节点。该查找过程的开始位置由m_piData1[m_iLastInsertPos]与seqno1的相对大小决定,如果前者较小,则从m_iLastInsertPos开始,否则,从m_iHead开始。这大概主要是想要利用空间局部性原理来提高查找的效率。然后就是通过一个循环找到新插入节点前面的那个节点。
找到的这前面的节点所表示的丢失packet范围与要插入的节点所要表示的范围之间的关系又有这样的几种case:
case 1:前面的节点表示的范围只有一个packet。
case 2:前面的节点表示的范围含有多个packet,但它的结束SeqNo仍然小于要插入的范围的起始SeqNo。
case 3:前面的节点表示的范围含有多个packet,但它的结束SeqNo大于等于要插入的范围的起始SeqNo。
前两个case表明两个范围不相交,而case 3则表明两个范围是相交的。对于前两个case,则在前面的那个节点之后插入一个节点,链表中节点的连接关系做适当的调整即可。对于case 3,则需要将插入的这个范围合并入前面的那个节点。如果前面的那个节点包含的范围完全覆盖了要插入的范围,则什麽都不做,如果不是则需要对结束SeqNo字段做一些调整。
5. offset值等于0,表明要插入的这个范围的起始SeqNo与Head节点表示的范围的起始SeqNo相同,这个过程则与offset大于0时,seqno1 == m_piData1[loc]中的处理基本一致。
6. 从插入新节点的位置开始,合并链表中与新插入的这个丢失packet范围相交,或被包含或紧紧相邻的节点。
7. 返回新加入CSndLossList的丢失packet的总个数。
有这个函数的整个执行过程不难看出,头节点中将包含最老的丢失packets。
看完了插入,自然不能不再来看一下CSndLossList::remove():
void CSndLossList::remove(int32_t seqno) {
CGuard listguard(m_ListLock);
if (0 == m_iLength)
return;
// Remove all from the head pointer to a node with a larger seq. no. or the list is empty
int offset = CSeqNo::seqoff(m_piData1[m_iHead], seqno);
int loc = (m_iHead + offset + m_iSize) % m_iSize;
if (0 == offset) {
// It is the head. Remove the head and point to the next node
loc = (loc + 1) % m_iSize;
if (-1 == m_piData2[m_iHead])
loc = m_piNext[m_iHead];
else {
m_piData1[loc] = CSeqNo::incseq(seqno);
if (CSeqNo::seqcmp(m_piData2[m_iHead], CSeqNo::incseq(seqno)) > 0)
m_piData2[loc] = m_piData2[m_iHead];
m_piData2[m_iHead] = -1;
m_piNext[loc] = m_piNext[m_iHead];
}
m_piData1[m_iHead] = -1;
if (m_iLastInsertPos == m_iHead)
m_iLastInsertPos = -1;
m_iHead = loc;
m_iLength--;
} else if (offset > 0) {
int h = m_iHead;
if (seqno == m_piData1[loc]) {
// target node is not empty, remove part/all of the seqno in the node.
int temp = loc;
loc = (loc + 1) % m_iSize;
if (-1 == m_piData2[temp])
m_iHead = m_piNext[temp];
else {
// remove part, e.g., [3, 7] becomes [], [4, 7] after remove(3)
m_piData1[loc] = CSeqNo::incseq(seqno);
if (CSeqNo::seqcmp(m_piData2[temp], m_piData1[loc]) > 0)
m_piData2[loc] = m_piData2[temp];
m_iHead = loc;
m_piNext[loc] = m_piNext[temp];
m_piNext[temp] = loc;
m_piData2[temp] = -1;
}
} else {
// target node is empty, check prior node
int i = m_iHead;
while ((-1 != m_piNext[i]) && (CSeqNo::seqcmp(m_piData1[m_piNext[i]], seqno) < 0))
i = m_piNext[i];
loc = (loc + 1) % m_iSize;
if (-1 == m_piData2[i])
m_iHead = m_piNext[i];
else if (CSeqNo::seqcmp(m_piData2[i], seqno) > 0) {
// remove part/all seqno in the prior node
m_piData1[loc] = CSeqNo::incseq(seqno);
if (CSeqNo::seqcmp(m_piData2[i], m_piData1[loc]) > 0)
m_piData2[loc] = m_piData2[i];
m_piData2[i] = seqno;
m_piNext[loc] = m_piNext[i];
m_piNext[i] = loc;
m_iHead = loc;
} else
m_iHead = m_piNext[i];
}
// Remove all nodes prior to the new head
while (h != m_iHead) {
if (m_piData2[h] != -1) {
m_iLength -= CSeqNo::seqlen(m_piData1[h], m_piData2[h]);
m_piData2[h] = -1;
} else
m_iLength--;
m_piData1[h] = -1;
if (m_iLastInsertPos == h)
m_iLastInsertPos = -1;
h = m_piNext[h];
}
}
}
先来回忆下CSndLossList的类定义中,对于这个函数的语义的说明:移除所有不大于参数值的SeqNo。这个函数的主要执行过程如下:
1. 检查m_iLength是否为0,若为0,说明CSndLossList还没有加入任何SeqNo,则直接返回,否则继续执行。
2. 计算头节点所表示的丢失packet范围的起始SeqNo与参数seqno的offset,及可能以seqno作为起始SeqNo字段的节点的位置loc。
根据这个函数的语义,我们知道,其实是不需要处理offset小于的case的。如我们前面所了解的,头节点所表示的SeqNo范围是CSndLossList中SeqNo值最小的一个范围,而如果seqno小于这个范围的起始SeqNo的话,则说明不大于seqno的所有SeqNo都已经不存在了。
3. 处理offset == 0的情况。offset == 0,表明seqno是包含于头节点所表示的范围,而且还是这个范围的起始SeqNo。此时又主要分两种情况来处理:
(1). 头节点表示的这个范围只有一个SeqNo。
(2). 头节点表示的范围包含多个SeqNo。
对于情况(1),则头节点将向后滑动一个节点,原来头节点的存放位置会被复位。对于情况(2),为了保证两个节点的相对位置等于节点所表示的丢失packet范围的起始SeqNo的差值这样的一种节点间关系依然成立,需要将头节点保存的位置后移一个位置。对于情况(2),还会再分为两种情况来处理,一是原来的头节点中只包含2个SeqNo,则在移除seqno后只剩下了一个,此时要保持m_piData2[loc]为-1,若包含3个及以上SeqNo的,则要复制原来的头节点的结束SeqNo到新的位置。
其它就是适当地更新m_iLastInsertPos,m_iHead和m_iLength了。这里似乎补一个
m_piNext[m_iHead] = -1;
要更好一点。
4. 处理offset大于0的情况。对于这种情况,比较麻烦的是找到seqno具体包含在哪个节点中。处理过程大致为:
(1). 检查一下,seqno与m_piData1[loc]是否相等,若相等,则要找的节点已经是找到了,且seqno为目标节点表示的丢失packet范围的起始seqno。此时则会再分为两种情况来处理,一是目标节点中只包含一个SeqNo,则使链表头指向目标节点的下一个节点。
二是目标节点中包含多个SeqNo,则需要将seqno排除在目标节点范围之外新建一个节点,将新节点保存在目标节点后面相邻的位置,若目标节点中包含2个节点,则需要设置新节点的结束SeqNo字段为-1,若大于等于3,则复制此字段的值,然后将原来的目标节点改造为只包含seqno的节点,并使它指向新建的这个节点。总之就是将原来的一个节点拆分成了两个节点,一个节点只包含seqno,另一个则包含原来的目标节点中其余的SeqNo。
(2). seqno与m_piData1[loc]不相等的情况,则需要先找到起始SeqNo字段小于seqno的SeqNo值最大的那个节点。这又可以分为3种case来处理,
case 1:找到的节点只包含一个SeqNo,此时则使链表头指向找到的节点的next节点。
case 2:找到的节点包含多个SeqNo,且seqno小于找到的节点的结束SeqNo字段,此时则需要将找到的节点裂为链表中的两个节点,一个包含的范围为[原节点的起始SeqNo,seqno],另一个包含的范围为[seqno + 1, 原节点的结束SeqNo]。同时链表头应该指向后者。
case 3:找到的节点包含多个SeqNo,且seqno大于等于找到的节点的结束SeqNo字段,此时则同样使链表头指向找到的节点的next节点。
5. 移除新找到的头节点之前所有的节点。适当地更新m_iLength等。
这个地方移除的操作看起来好罗嗦。必须要计算出offset值,而不是简单的用比较符号,是由SeqNo的递增规则决定的。但对于offset大于等于0的情况,则可以使用统一的过程来处理:找到起始SeqNo字段不大于seqno的 SeqNo值最大的那个节点,然后根据seqno与这个节点描述的范围的4种关系,即seqno等于找到的节点的起始SeqNo值,seqno大于起始SeqNo值但小于结束SeqNo值,seqno等于结束SeqNo值,seqno大于结束SeqNo值,及找到的节点所描述的范围的大小,来分类处理即可。
还有我们前面在CUDT::packData()中看到的CSndLossList::getLostSeq():
int32_t CSndLossList::getLostSeq() {
if (0 == m_iLength)
return -1;
CGuard listguard(m_ListLock);
if (0 == m_iLength)
return -1;
if (m_iLastInsertPos == m_iHead)
m_iLastInsertPos = -1;
// return the first loss seq. no.
int32_t seqno = m_piData1[m_iHead];
// head moves to the next node
if (-1 == m_piData2[m_iHead]) {
//[3, -1] becomes [], and head moves to next node in the list
m_piData1[m_iHead] = -1;
m_iHead = m_piNext[m_iHead];
} else {
// shift to next node, e.g., [3, 7] becomes [], [4, 7]
int loc = (m_iHead + 1) % m_iSize;
m_piData1[loc] = CSeqNo::incseq(seqno);
if (CSeqNo::seqcmp(m_piData2[m_iHead], m_piData1[loc]) > 0)
m_piData2[loc] = m_piData2[m_iHead];
m_piData1[m_iHead] = -1;
m_piData2[m_iHead] = -1;
m_piNext[loc] = m_piNext[m_iHead];
m_iHead = loc;
}
m_iLength--;
return seqno;
}
这个函数读取首个丢失packet的SeqNo。
这个函数会取链表头节点中最小的SeqNo,返回给调用者,然后将这个SeqNo从链表头节点中移除。移除的时候又可以分为2种情况:1. 头节点描述的packet范围只包含一个SeqNo,2. 包含多个SeqNo。
对于情况1,则将链表头节点向后移动一个节点,然后移除原来的头节点。对于情况2,则将原来的头节点分裂为两个节点,一个只包含首个丢失packet的SeqNo,另一个包含原来头节点中其余的SeqNo,令链表头节点指向后一个节点,并移除前一个节点。
可见,通过CSndLossList::getLostSeq()返回给调用者的Packet是会被从CSndLossList中移除出去的。
最后可以再来看一下,经过了这些操作的蹂躏之后,这个链表可能的样子。比如有4段丢失的packet,其SeqNo范围及被插入的顺序为[8, 9],[3, 5],[12,12],[15, 19],假设缓冲区大小为20,则看起来可能为:
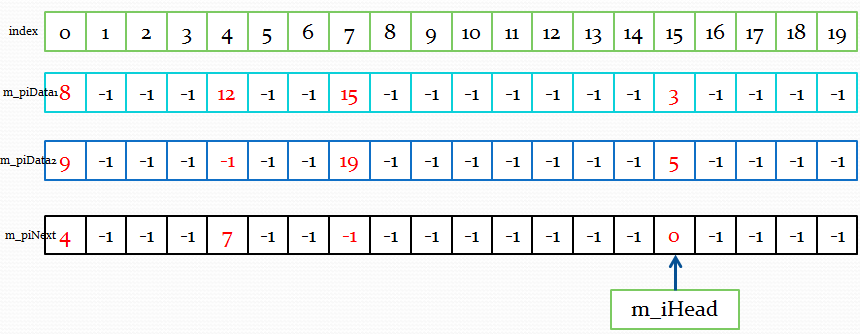
UDT中,丢失packet列表大体如此。
接着来看一下UDT中的ACK机制。
再来看一下UDT中的超时重传机制
然后是NACK。
这里来看一下发送窗口及发送速率的控制方法。
接收端的反馈
拥塞控制
Done。
标签:
原文地址:http://my.oschina.net/wolfcs/blog/508259