标签:
在线参考文档:http://mybatis.github.io/mybatis-3/zh/index.html
首先我们定义一个需求:根据id查询用户。
开发mybatis入门程序需要编写两个配置文件,全局配置文件(SqlMapperConfig.xml)和sql语句配置文件(xxxMapper.xml)。
a、全局配置文件(SqlMapConfig.xml)
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <environments default="development"> <environment id="development"> <!-- 使用jdbc事务管理--> <transactionManager type="JDBC" /> <!-- 数据源--> <!-- POOLED参数表示使用连接池,mybatis框架自带连接池 --> <dataSource type="POOLED"> <property name="driver" value="com.mysql.jdbc.Driver"/> <property name="url" value="jdbc:mysql://localhost:3306/mybatishelloworld?useUnicode=true&characterEncoding=UTF-8"/> <property name="username" value="root"/> <property name="password" value="root"/> </dataSource> </environment> </environments> <!-- 加载mapper.xml --> <mappers> <mapper resource="mapper/userMapper.xml"/> </mappers> </configuration>
如上,在sqlMapConfig.xml的configuration元素中编写配置信息,这里需要注意加载xxxMapper.xml 。
b、sql映射文件(userMapper.xml)
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="ff.ing.mapper.userMapper">
<!-- 根据id查询用户 -->
<select id="findUserById" parameterType="int" resultType="ff.ing.po.User">
SELECT * FROM user WHERE id = #{id}
</select>
</mapper>
如上,在userMapper.xml的mapper元素中编写sql语句,namespace属性定义了一个命名空间,select元素定义了一个select查询语句,id为语句的唯一标识,parameterType为输入映射类型,resultType为输出映射类型,#{}可理解为占位符,功能同预编译里的 ‘?‘。
在上面的userMapper.xml中的select语句有三个属性,id、parameterType和resultType,id为这个语句的唯一标识,parameterType为输入映射,resultType为输出映射。在这个语句中parameterType类型为int,resultType类型为一个pojo类型,所以我们需要创建这个pojo类型。代码如下:
public class User {
private int id;
private String username;// 用户姓名
private String sex;// 性别
private Date birthday;// 生日
private String address;// 地址
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public Date getBirthday() {
return birthday;
}
public void setBirthday(Date birthday) {
this.birthday = birthday;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
@Override
public String toString() {
return "User [id=" + id + ", username=" + username + ", sex=" + sex + ", birthday=" + birthday + ", address="
+ address + "]";
}
}
接下来编写测试代码。
public class FirstDemo {
private SqlSessionFactory sqlSessionFactory = null;
// 执行该类任何方法前调用这个方法
// 加载全局配置文件
@Before
public void init() throws IOException {
String config = "SqlMapConfig.xml";
InputStream inputStream = Resources.getResourceAsStream(config);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
}
// 根据id查询用户
@Test
public void findUserById() {
// 获取SqlSession对象
SqlSession sqlSession = sqlSessionFactory.openSession();
User user = null;
try {
// 执行SqlSession对象中的selectOne方法执行sql语句
// 参数1为sql语句唯一标识(namespace + id),参数2为输入映射
user = sqlSession.selectOne("ff.ing.mapper.userMapper.findUserById", 1);
} catch (Exception e) {
e.printStackTrace();
} finally {
sqlSession.close();
}
System.out.println(user);
}
}
测试结果

到这里,一个mybatis入门程序就写完了。
附上项目目录结构

MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google code,并且改名为MyBatis,实质上Mybatis对ibatis进行一些改进。 目前mybatis在github上托管。git(分布式版本控制,当前比较流程)
MyBatis是一个优秀的持久层框架,它对jdbc的操作数据库的过程进行封装,使开发者只需要关注 SQL 本身,而不需要花费精力去处理例如注册驱动、创建connection、创建statement、手动设置参数、结果集检索等jdbc繁杂的过程代码。
Mybatis通过xml或注解的方式将要执行的各种statement(statement、preparedStatemnt、CallableStatement)配置起来,并通过java对象和statement中的sql进行映射生成最终执行的sql语句,最后由mybatis框架执行sql并将结果映射成java对象并返回。
a 数据库连接创建和关闭频繁,造成数据库资源浪费,影响系统效率。改进:使用数据库连接池。
b 代码中sql语句硬编码,如果需求变更需要修改sql,就必须修改java代码,必须重新编译,使系统不易维护。改进:将sql语句统一配置在文件中,修改sql语句时不需要修改java代码。
c dao层开发中通过preparedStatement向占位符设置参数存在硬编码(参数位置,参数),使系统不易维护。改进:将sql中的占位符和对应的参数类型配置在文件中,提供将参数自动注入到sql语句中的功能(输入映射)。
d dao层开发中遍历查询结果集存在硬编码(结果集列名硬编码)。改进:实现sql查询结果集向java对象的自动封装功能。(输出映射)
总结一下,用mybatis开发项目具有高灵活性,易于维护的优点,mybatis还支持主流数据库连接池,具有动态sql的特性,可以轻松的根据不同条件拼接sql,所以乐意用它。
mybatis适用于开发需求变更频繁的系统,比如互联网项目;传统jdbc开发方式或框架,如hibernate适用于需求固定,对象数据模型稳定的项目,比如企业OA系统。

a、全局配置文件
mybatis全局配置文件名字不固定,上边入门demo里使用SqlMapConfig.xml命名。它的有用是配置mybatis的运行环境,如数据源、事物等,以及加载sql映射配置文件。配置文件顶层结构如下:
configuration 配置
properties 属性
settings 设置
typeAliases 类型命名
typeHandlers 类型处理器
objectFactory 对象工厂
plugins 插件
environments 环境
environment 环境变量
transactionManager 事务管理器
dataSource 数据源
databaseIdProvider 数据库厂商标识
mappers 映射器
properties配置了一些可动态替换的参数,如数据库信息。
settings中包含很多子节点,定义了mybatis的行为。
typeAliases定义类的别名,作用是简化sql映射文件的编写。mybatis已经为常用java类型定义了别名。
typeHandlers作用是实现数据库数据类型和java类型间的转换,它支撑着mybatis的输入和输出映射。可自定义类型
objectFactory用于创建查询结果集映射的对象实例。
environments配置环境,有三个子节点,environment节点定义环境id,用于唯一标识该环境;transactionManager设置事物管理类型;dataSource配置数据源。
mappers定义需要加载的sql映射文件。
详细配置参考在线参考文档XML配置一节。
b、sql映射文件
sql映射文件同样没有固定命名,但建议使用xxxMapper.xml形式命名。它的作用配置映射的sql语句,达到省略jdbc代码,使开发人员能够专注sql语句本身。映射文件顶层结构如下:
cache – 给定命名空间的缓存配置。
cache-ref – 其他命名空间缓存配置的引用。
resultMap – 是最复杂也是最强大的元素,用来描述如何从数据库结果集中来加载对象。
sql – 可被其他语句引用的可重用语句块。
insert – 映射插入语句
update – 映射更新语句
delete – 映射删除语句
select – 映射查询语句
详细配置信息参考在线参考文档XML映射文件一节。
c 、SqlSessionFactoryBuilder、SqlSessionFactory与SqlSession
通过SqlSessionFactoryBuilder对象的build()方法加载全局配置文件创建SqlSessionFactory对象,通过SqlSessionFactory对象的openSession()方法创建SqlSession对象,SqlSession对象操作数据库(实际由Executor执行sql语句)。执行insert、update、delete、select后需要执行SqlSession对象中的commit()方法,最后不要忘了关闭SqlSession。
三个对象的API参考在线参考文档中的Java API一节。
d、输入映射、输出映射
输入映射
sql映射语句中通过配置parameterType属性定义输入映射(parameterMap已经弃用),可以是简单类型(int、byte、char、double……)也可以是对象(java内置对象或者自定义对象),用于支撑#{}和${}取值功能,当类型为对象时通过这个对象的getter函数获取值。
输出映射
sql映射语句中通过配置resultType或resultMap属性定义输出映射,一般是对象。
resultType:mybatis简单的将结果集封装成resultType属性里配置的对象,如果类型是自定义对象则要求属性名和结果集字段名一致,否则报错。
resultMap:mybatis通过配置resultMap将结果集字段映射成自定义名称,方便处理多表查询结果集字段冲突的情况和某些需求下的复杂查询(一对多,多对多)。
同样的,细节参考在线参考文档中XML映射文件一节下的参数和结果集
e、${}与#{}
#{}与${}都是mybatis中的取值表达式,但它们的区别还挺大。
#{}表示一个占位符,它在取值时会自动进行java类型和jdbc类型的转换,这样开发人员不需要考虑参数类型在sql语句中书写的规则,比如:select * from user where name = #{user.name},在这里user.name是一个字符串,假设值为"jack",mybatis最终拼接好的sql会是这样,select * from user where name = ‘jack‘。
${}表示简单的sql拼接,并不会进行类型转换,比如上面的sql语句如果改用${}得这样写:select * from user where name = ‘${user.name}‘。
#{}相比于${}还有个非常大的优点——可以防止sql注入,因为#{}效果同jdbc预编译中的‘?‘符号,而${}只是简单的字符串拼接。
注意:当parameterType为String或者其它java内置对象时,使用#{_parameter}或${_parameter}获取值。
f、动态sql
mybatis动态sql特性支持根据不同条件动态的拼接sql,for each遍历parameterType中的集合类型以及重复使用sql片段等等。
根据不同条件动态拼接sql案例:
<select id="findUserList" parameterType="ff.domain.User" resultType="ff.domain.User">
SELECT id, username, birthday, sex FROM user
<where>
<if test="null != User>
<if test="null != User.username and ‘‘ != User.username">
and username like ‘%${User.username}%‘
</if>
<if test="null != User.sex and ‘‘ != User.sex">
and sex = #{User.sex}
</if>
<if>
</where>
</select>
mybatis会自动忽略where节点里的第一个and关键字。
将上面的sql映射用sql片段实现,如下:
<sql id="user_query_where">
<if test="null != User>
<if test="null != User.username and ‘‘ != User.username">
and username like ‘%${User.username}%‘
</if>
<if test="null != User.sex and ‘‘ != User.sex">
and sex = #{User.sex}
</if>
<if>
</sql>
<select id="findUserList" parameterType="ff.domain.User" resultType="ff.domain.User">
SELECT id, username, birthday, sex FROM user
<where>
<include refid="user_query_where"></include>
</where>
</select>
先在mapper.xml文件中定义sql片段,然后可以在sql映射语句中使用include元素引用。
for each元素用于遍历parameterType中的集合类型,这里不做演示。
同样的,动态sql特性其它功能以及使用细节参考在线参考文档动态sql一节。
g、主键返回
针对mysql数据库
定义一个需求:添加一个用户,并返回该用户的主键。
方法一:如果是自增主键,在执行插入用户的sql语句后使用LAST_INSERT_ID()函数获取最后插入记录的主键值
<insert id="insertUser" parameterType="ff.ing.po.User">
<!-- 插入后查询最后插入记录的id并封装进User实例,解决返回主键需求 -->
<selectKey keyProperty="id" order="AFTER" resultType="int">
SELECT LAST_INSERT_ID()
</selectKey>
INSERT INTO user(username,birthday,sex,address) VALUES(#{username},#{birthday},#{sex},#{address})
</insert>
通过<selectKey>元素可以定义一个insert映射语句的执行前后进行的一些额外操作,如在上面的语句中的selectKey元素将会首先执行,这是selectKey元素order属性的功劳,AFTER值定义这个selectKey元素中sql语句在insert语句执行后执行,keyProperty定义将查询结果封装到输入映射的哪一个属性中,resultType定义了查询结果的类型。这条语实现在执行insert语句后执行查询最后插入记录主键值语句,然后将查询结果封装到输入映射(ff.ing.po.User)的id属性中。
sqlSession.insert("ff.ing.mapper.userMapper.insertUser", userIn);
sqlSession.commit();
System.out.println(userIn.getId());
在测试中执行上面代码后,userIn中的id属性自动被设置成user表中最后插入的记录的主键值。
方法二:如果不是自增主键,可使用mysql内置的UUID()函数实现,在执行插入用户的sql语句前生成UUID并封装到输入映射,然后再执行插入语句
<insert id="insertUserByUUID" parameterType="ff.ing.po.User1">
<!-- 插入前先生成UUID,将UUID封装到输入映射中再执行插入语句 -->
<selectKey keyProperty="id" order="BEFORE" resultType="String">
SELECT UUID()
</selectKey>
INSERT INTO user1(id,username,birthday,sex,address) VALUES(#{id},#{username},#{birthday},#{sex},#{address})
</insert>
order属性值为BEFORE,使执行insert前先执行selectKey元素里生成UUID的sql语句并封装到输入映射中,然后再执行insert语句
sqlSession.insert("ff.ing.mapper.userMapper.insertUserByUUID", userIn);
sqlSession.commit();
System.out.println(userIn.getId());
测试中执行上面代码后,userIn的id属性值为UUID()产生的32数列
首先定义一个需求:根据id查询用户信息
不管是原始dao开发方式或者mapper代理开发方式都需要先编写全局配置文件和sql映射文件,这里同hello world一致。
原始dao开发方式
第一步写接口。
public interface UserDao {
public User findUserById(int id) throws Exception;
}
第二步写实现类
public class UserDaoImp implements UserDao{
private SqlSessionFactory sqlSessionFactory = null;
public UserDaoImp(SqlSessionFactory sqlSessionFactory) {
this.sqlSessionFactory = sqlSessionFactory;
}
@Override
public User findUserById(int id) throws Exception {
SqlSession sqlSession = sqlSessionFactory.openSession();
User user = sqlSession.selectOne("ff.ing.mapper.userMapper.findUserById", 1);
sqlSession.close();
return user;
}
}
因为SqlSession类是线程不安全的,所以将其定义在方法体内
第三步测试
@Test
public void testFindUserById() throws Exception {
User user = new UserDaoImp(sqlSessionFactory).findUserById(1);
System.out.println(user);
}
测试结果

mapper代理开发方式
开发规范:
a. sql映射文件中mapper元素namespace属性值为mapper接口的全限定名。
b. sql映射文件中sql语句元素的id属性值为mapper接口里的方法名,resultType属性值或resultMap元素type属性值为方法返回类型,parameterType属性值为方法参数类型。
第一步修改userMapper.xml文件,使其符合开发规范
由于规范a,我们将sql映射文件中mapper元素namespace属性值改成ff.ing.mapper.Usermapper
第二步根据userMapper.xml创建接口
public interface UserMapper {
public User findUserById(int id) throws Exception;
}
第三步测试
@Test
public void testFindUserById() throws Exception {
SqlSession sqlSession = sqlSessionFactory.openSession();
// 获取代理对象,实质是mybatis帮我们创建接口实现类
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
User user = userMapper.findUserById(1);
sqlSession.close();
System.out.println(user);
}
测试结果

可以看出,mybatis的mapper开发方式省略了重复的SqlSession执行sql语句操作过程,同时还避免因传统dao开发方式中dao实现类输入映射的硬编码问题,提高了可维护性(在传统dao开发方式中,如果输入映射类型变了,就必须同时修改sql映射文件里的parameterType属性值和dao层实现类代码,而用mapper代理开发方式只需要修改sql映射文件里的parameterType属性值)
注:在写博客过程中忘了修改userMapper.xml中mapper元素的namespace,遇到这样的报错

原因是规范a规定userMapper.xml中mapper元素的namespace属性值为接口全限定名(未修改时是userMapper),而创建接口时定义接口名为UserMapper,mybatis找不到名为userMapper的接口所以报错。
mybatis提供一套简化开发的规范(包括mapper代理开发规范),这一节记录如何简化开发。同样的,定义一个需求:根据id查询用户信息。
第一步简化sql映射文件配置。在全局配置文件中定义别名可以避免书写类的全限定名,这里使用扫描包方式定义别名
<!-- 定义别名 --> <typeAliases> <!-- 扫描包方式定义别名,每个类的类名就是其别名,mybatis会自动将类名当作别名并映射类的全限定名。配置后在输入、输出映射里可以使用别名替换类的全限定名 --> <package name="ff.ing.po"/> </typeAliases>
第二步全局配置文件mappers元素里改用扫描包的方式替换配置子mapper元素方式,这样避免配置每个mapper的重复操作。
注意:这里有个规范,要求mapper.xml文件与其对应的mapper.java接口同名且在同一个包中
<!-- 加载mapper.xml --> <mappers> <!-- 使用扫描包方式加载mapper,mybatis会自动加载这个包下所有mapper文件 --> <package name="ff.ing.mapper"/> </mappers>
到这里简化开发的配置文件修改工作已经完成,不过还可以作一个小改进,用配置文件替换全局配置中数据源属性值,增加一些灵活性。
在config源文件夹中创建db.properties配置文件,配置内容如下:
# 数据源配置 jdbc.driver=com.mysql.jdbc.Driver jdbc.url=jdbc:mysql://localhost:3306/mybatishelloworld?useUnicode=true&characterEncoding=UTF-8 jdbc.username=root jdbc.password=root
接着在全局配置文件中添加properties配置
<!-- 加载数据库配置文件 --> <properties resource="db.properties"></properties>
然后修改全局配置文件的environments子元素environment的子元素dataSource里的属性值。
<!-- 数据库连接池-->
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</dataSource>
现在全局配置文件修改完成,下面是修改后的全局配置文件。
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- 加载数据源配置文件 -->
<properties resource="db.properties"></properties>
<!-- 定义别名 -->
<typeAliases>
<!-- 扫描包方式定义别名,别名就是类名。配置后在输入、输出映射里可以使用别名替换类的全限定名 -->
<package name="ff.ing.po"/>
</typeAliases>
<environments default="development">
<environment id="development">
<!-- 使用jdbc事务管理-->
<transactionManager type="JDBC" />
<!-- 数据库连接池-->
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</dataSource>
</environment>
</environments>
<!-- 加载mapper.xml -->
<mappers>
<!-- 使用扫描包方式加载mapper,mybatis会自动加载这个包下所有mapper文件 -->
<package name="ff.ing.mapper"/>
</mappers>
</configuration>
第三步修改sql映射文件,使用别名替换类全限定名,下面是修改后的文件。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="ff.ing.mapper.UserMapper">
<!-- 根据id查询用户 -->
<select id="findUserById" parameterType="int" resultType="User">
SELECT * FROM user WHERE id = #{id}
</select>
</mapper>
到这里,简化开发大功告成。
定一个需求:查询订单关联查询订单明细和用户名、用户性别
数据模型说明:orders表中存储用户订单信息,orderdetail表中存储订单明细信息,user表中存储用户信息,user表和orders表一对多关系,orders表和orderdetail表一对多关系。
先把sql语句写出来:
SELECT
orders.*, user.username,
user.sex,
orderdetail.id orderdetail_id,
orderdetail.items_num,
orderdetail.items_id
FROM
orders,
orderdetail,
user
WHERE
orders.user_id = user.id
AND orders.id = orderdetail.orders_id;
使用resultType开发
创建Order对象,然后创建OrderQuery对象继承Order对象,然后添加查询结果集中其它字段,确保OrderQuery对象属性与结果集字段名一一对应。
public class OrderQuery extends Order {
// 用户信息
private String username;
private String sex;
// 订单明细信息
private int orderdetail_id;
private int items_id;
private int items_num;
配置sql映射文件
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="ff.ing.mapper.OrderMapper"> <!-- 一对多查询, 查询订单信息关联查询订单明细和用户名、用户性别 --> <select id="findOrderOrderdetailUser" resultType="OrderQuery"> SELECT orders.*, user.username, user.sex, orderdetail.id orderdetail_id, orderdetail.items_num, orderdetail.items_id FROM orders, orderdetail, user WHERE orders.user_id = user.id AND orders.id = orderdetail.orders_id; </select> </mapper>
根据sql映射文件创建mapper接口,创建测试类进行测试
使用resultMap开发
在Order类中关联User、OrderDetail
public class Order {
private int id;
private int user_id;
private String number;
private Date createtime;
private String note;
// 关联用户
private User user;
// 关联订单明细
private List<OrderDetail> orderDetails;
配置sql映射文件
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="ff.ing.mapper.OrderMapper"> <!-- 订单关联订单明细和用户名、用户性别 --> <!-- resultMap作用的将结果集的字段名映射到pojo --> <!-- type定义将结果集映射到哪个pojo id是resultMap的唯一标识 --> <resultMap type="Order" id="orderOrderdetailUser"> <!-- id配置结果集中主键的映射,result是非主键映射。 column是结果集字段,property定义将结果集字段映射到Order中哪个属性 --> <id column="id" property="id"/> <result column="user_id" property="user_id"/> <result column="number" property="number"/> <result column="createtime" property="createtime"/> <result column="note" property="note"/> <!-- 关联User --> <!-- association将关联信息映射到某个pojo。 property定义将关联信息映射到Order哪个属性,javaType定义这个属性是什么类型 --> <association property="user" javaType="User"> <result column="sex" property="sex"/> <result column="username" property="username"/> </association> <!-- 关联Orderdetial --> <!-- Order中关联了Orderdetail集合,所有用collection --> <!-- property定义将关联信息映射到Order哪个属性,ofType定义这个属性是什么类型 --> <collection property="orderDetails" ofType="OrderDetail"> <id column="orderdetail_id" property="id"/> <result column="items_num" property="items_num"/> <result column="items_id" property="items_id"/> </collection> </resultMap> <!-- 一对多查询, 查询订单信息关联查询订单明细和用户名、用户性别,使用resultType --> <select id="findOrderOrderdetailUser" resultType="OrderQuery"> SELECT orders.*, user.username, user.sex, orderdetail.id orderdetail_id, orderdetail.items_num, orderdetail.items_id FROM orders, orderdetail, user WHERE orders.user_id = user.id AND orders.id = orderdetail.orders_id; </select> <!-- 一对多查询, 查询订单信息关联查询订单明细和用户名、用户性别,使用resultMap --> <select id="findOrderOrderdetailUserByResultMap" resultMap="orderOrderdetailUser"> SELECT orders.*, user.username, user.sex, orderdetail.id orderdetail_id, orderdetail.items_num, orderdetail.items_id FROM orders, orderdetail, user WHERE orders.user_id = user.id AND orders.id = orderdetail.orders_id; </select> </mapper>
接着同样的根据sql映射文件写mapper接口,写测试类测试
从上面我们可以看出,使用resultType开发复杂查询需要创建新的pojo对象,而使用resultMap只需要修改原有的pojo对象。resultType要求结果集字段名和输出映射属性名一致,但是在复杂查询中经常存在结果集字段冲突的情况,这时候无法使用resultType,而resultMap的映射特性正好能够解决这个问题。
在进行数据查询时,为了提高数据库性能,尽量使用单表查询,因为单表查询比多表关联查询速度要快。如果单表查询就能满足需求,一开始先查询单表,当需要关联查询时再关联查询,当需要关联查询再关联查询这样的按需查询特性叫做延迟加载。
先定义一个需求:查询订单关联查询用户id、username,一开始只查询订单信息,当需要查询用户信息时通过调用Order类的getUser()方法想数据库发送sql。
mybatis中通过resultMap实现延迟加载功能。在配置resultMap之前先要先配置全局配置文件,开启延迟加载。开启延迟加载需要在全局配置的settings元素中配置如下两个参数:

<!-- mybatis行为参数配置 --> <settings> <!-- 开启延迟加载 --> <setting name="lazyLoadingEnabled" value="true"/> <!-- 设置按需加载 --> <setting name="aggressiveLazyLoading" value="false"/> </settings>
接着在sql映射文件中配置resultMap
<resultMap type="Order" id="orderUser">
<id column="id" property="id"/>
<result column="user_id" property="user_id"/>
<result column="number" property="number"/>
<result column="createtime" property="createtime"/>
<result column="note" property="note"/>
<!--
property: 将关联查询的信息设置到order哪个属性
select: 延迟加载执行的sql的id,这里是查询User语句
column:查询User的sql语句中#{id}的参数值
-->
<association property="user" column="user_id" select="ff.ing.mapper.UserMapper.findUserById"></association>
</resultMap>
然后写sql映射语句
<select id="findOrderUser" resultMap="orderUser"> SELECT * FROM orders WHERE id = 3 </select>
这个延迟加载demo由两条语句组成,查询订单:SELECT * FROM orders WHERE id = 3 和 查询用户:SELECT * FROM user WHERE id = #{id}。当不需要查询User时,只执行SELECT * FROM orders;当需要查询User时,再执行SELECT * FROM user WHERE id = #{id},并把查询Order获得到的结果集中的user_id当作参数传入,获得这句sql的结果集最后由输出映射自动封装成新的结果集。
接着在OrderMapper接口中添加findOrderUser方法,然后编写测试方法。
public Order findOrderUser() throws Exception;
@Test
public void testFindOrderUser() throws Exception {
SqlSession sqlSession = sqlSessionFactory.openSession();
OrderMapper orderMapper = sqlSession.getMapper(OrderMapper.class);
Order order = orderMapper.findOrderUser();
order.getUser();
sqlSession.close();
}
最后测试,这部分测试需要日志信息的支持,下一节再测试。
注意:mybatis延迟加载特性依赖于cglib,而cglib依赖asm,所以要导入cglib和asm两个jar包
首先导入log4j的jar包和commons-logging

然后在config目录下配置log4j配置文件log4j.properties
# Global logging configuration\uff0c\u5efa\u8bae\u5f00\u53d1\u73af\u5883\u4e2d\u8981\u7528debug log4j.rootLogger=DEBUG, stdout # Console output... log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n
log4j.rootLogger指定日志输出级别为debug,输出方式是控制台, log4j.appender.stdout指定在控制台输出方式的实现类和其它一些参数
log4j有多种日志级别,分为OFF、FATAL、ERROR、WARN、INFO、DEBUG、TRACE、ALL或者您定义的级别。Log4j建议只使用四个级别,优先级从高到低分别是ERROR、WARN、INFO、DEBUG。通过在这里定义的级别,您可以控制到应用程序中相应级别的日志信息的开关。比如在这里定义了INFO级别,则应用程序中所有DEBUG级别的日志信息将不被打印出来。程序会打印高于或等于所设置级别的日志,设置的日志等级越高,打印出来的日志就越少。如果设置级别为INFO,则优先级高于等于INFO级别(如:INFO、WARN、ERROR)的日志信息将可以被输出,小于该级别的如DEBUG将不会被输出。
现在我们对延迟加载demo进行测试,在测试方法中order.getUser()这一行添加断点,run as debug,然后我们在控制台会看到,当代码没有执行order.getUser()时只会执行SELECT * FROM orders WHERE id = 3语句,当执行order.getUser()时,才执行SELECT * FROM user WHERE id = #{id}语句。
a、缓存的意义:将用户经常查询的数据放在缓存(内存)中,当用户查询这些数据时从缓存中查询而不用从磁盘中(数据库数据文件)查询,从而提高查询效率,解决高并发系统的性能问题。
b、java的传统三层架构中存在三类缓存:控制层缓存,业务层缓存和持久层缓存。如下图

c、mybatis实现持久层缓存,提供了一级缓存和二级缓存。
一级缓存与二级缓存示意图如下
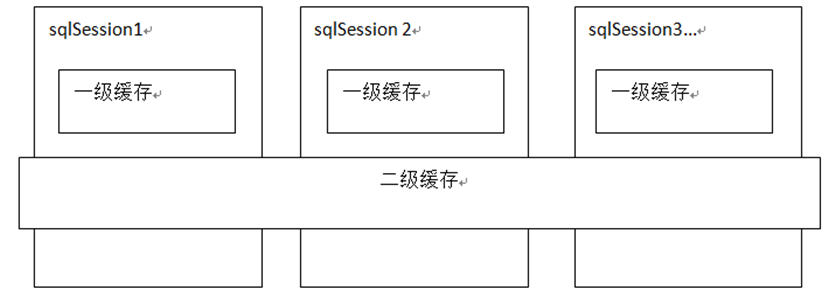
mybatis的一级缓存是一个SqlSession级别的缓存,SqlSession智能访问自己的一级缓存数据,二级缓存是跨SqlSession的Mapper级别缓存,不同SqlSession可以共享。
一级缓存
原理图如下:
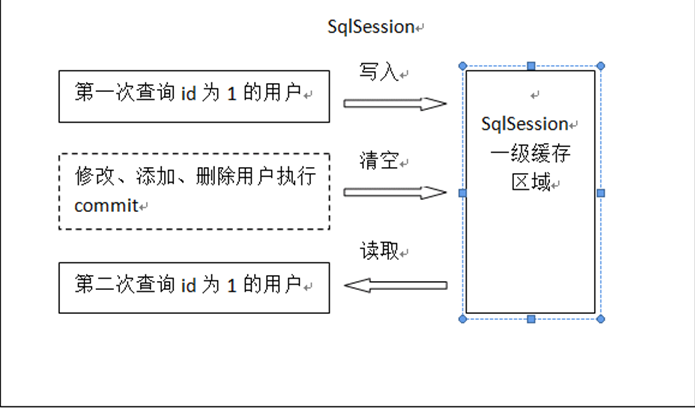
mybatis默认支持一级缓存,不需要配置,每次查询都先从缓存中查询数据,没有取到数据再从数据库中查询。第一次发出一个查询sql,mybatis在缓存中找不到数据,于是到数据库中查询数据,并将sql返回结果集写入一级缓存,数据结构为Map<key, value>,key = hashcode + sql + sql输入映射和输出映射,value = 结果集。当同一个SqlSession再次发出相同sql时从缓存中取数据,不会到数据库中查询数据,当有commit操作时清空这个一级缓存中所有数据,此时再发送查询sql又会到数据库中查询,因为缓存为空。
接下来对一级缓存特性进行测试。
public void testCacheLevel1() throws Exception{
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
User user1 = userMapper.findUserById(1);
User user2 = userMapper.findUserById(1);
System.out.println(user1);
System.out.println(user2);
sqlSession.close();
}
通过console输出的日志信息可以看到sql语句只执行一次,第二次查询时并没有发送sql从数据库中查询。
DEBUG [main] - Opening JDBC Connection
DEBUG [main] - Created connection 20064246.
DEBUG [main] - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@13227f6]
DEBUG [main] - ==> Preparing: SELECT * FROM user WHERE id = ?
DEBUG [main] - ==> Parameters: 1(Integer)
DEBUG [main] - <== Total: 1
User [id=1, username=王五, sex=2, birthday=null, address=null]
User [id=1, username=王五, sex=2, birthday=null, address=null]
二级缓存
原理图如下:

二级缓存是Mapper级别的缓存,以Mapper的命名空间为单位创建缓存空间,供相同命名空间下的SqlSession访问,不同命名空间下的SqlSession无法共享同一个二级缓存空间,空间的数据结构也是Map<key, value>(二级缓存有多个缓存空间,一级缓存只有一个缓存空间)。每次查询前先确认是否开启二级缓存,如果开启从二级缓存空间中查询数据,如果未开启会先从一级缓存中查询数据,没有查到匹配数据再从数据库中查询。
二级缓存配置
在全局配置文件SqlMapConfig.xml中加入
<setting name="cacheEnabled" value="true"/>

接着在Mapper映射文件中添加一行:<cache />,表示此Mapper开启二级缓存。(位于mapper元素内,最前面)
二级缓存需要将输出映射的pojo实现序列化,如果映射中还有pojo也要实现序列化,否则会抛出异常。
对二级缓存进行测试
@Test
public void testCacheLevel2() throws Exception {
SqlSession sqlSession1 = sqlSessionFactory.openSession();
SqlSession sqlSession2 = sqlSessionFactory.openSession();
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
User user1 = userMapper1.findUserById(1);
sqlSession1.close();
User user2 = userMapper2.findUserById(1);
sqlSession2.close();
System.out.println(user1);
System.out.println(user2);
}
从console输出的日志信息中可以看到,多了一行cache hit ration,说明正在从二级缓存中查询数据,同时可以看到sql只执行一次
DEBUG [main] - Cache Hit Ratio [ff.ing.mapper.UserMapper]: 0.0
DEBUG [main] - Opening JDBC Connection
DEBUG [main] - Created connection 2282736.
DEBUG [main] - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@22d4f0]
DEBUG [main] - ==> Preparing: SELECT * FROM user WHERE id = ?
DEBUG [main] - ==> Parameters: 1(Integer)
DEBUG [main] - <== Total: 1
DEBUG [main] - Resetting autocommit to true on JDBC Connection [com.mysql.jdbc.JDBC4Connection@22d4f0]
DEBUG [main] - Closing JDBC Connection [com.mysql.jdbc.JDBC4Connection@22d4f0]
DEBUG [main] - Returned connection 2282736 to pool.
DEBUG [main] - Cache Hit Ratio [ff.ing.mapper.UserMapper]: 0.5
User [id=1, username=王五, sex=2, birthday=null, address=null]
User [id=1, username=王五, sex=2, birthday=null, address=null]
二级缓存的禁用与刷新
对于变化频率高的sql需要禁用二级缓存:在sql映射语句中添加属性userCache=‘false‘,可以禁用当前sql语句的二级缓存,userCache属性默认值为true。
如果SqlSession执行commit操作会刷新二级缓存(清空),在sql映射语句中添加属性flushCache可以设置是否刷新缓存,默认值为true。
<cache>元素有许多配置,详细配置参考在线手册XML映射文件下cache一节
标签:
原文地址:http://my.oschina.net/u/1476426/blog/508512