标签:
1) 链路状态路由选择协议
入门:假如你现在在下沙沿江第一次要去古荡附近的公司报到,你不知道具体的路该怎么走,那该怎么办呢?
我们知道你可以在手机(路由器router)里面下载一个导航,在输入目的地后,导航会在他的各个区的地图表(路由表)中选择最优的路径去规划线路。那么,导航要达到这个目的,首先它必须有下沙沿江相连的6号大街(直连链路direct link)信息,下沙路的有没有在造地铁、堵不堵车(链路状态link state),到闸弄口后怎么转弯(直连邻居的信息)、过了艮山东路是往体育场路还是环城北路走(下一跳的链路信息),直到目的地;把这些信息汇总后存储在地图数据库(链路状态数据库)中,才能够根据这些信息计算(SPF算法)并选择最优路径以最快的速度达到目的地。
简介:如果把距离矢量路由器所使用的信息比拟为路标提供的信息的话,那么链路状态路由选择协议就像是一张公路线路地图。链路状态路由协议的网络中每一台路由器都会有自己的、直连链路的、直连邻居的、链路状态的信息;这些信息从一台路由器到另一台路由器,每台路由器都会做一份信息拷贝而不改变信息内容;最终每台路由器都可以依据这些信息独立的计算各自的最优路径。
链路状态协议(最短路径优先协议)有以下几种:
建立步骤:
邻居:
在建立链路状态环境的过程中,路由器通过hello协议(hello protocol)建立邻接关系,并监视邻居(邻接关系)的存活情况。典型的hello数据包交换间隔为10S,典型的死亡周期是数据包交换间隔的4倍。
链路状态泛洪:
在建立邻接关系后,路由器开始发送LSA。通告被发给每个邻居,路由器保存接收到的LSA,并依次立刻向每个邻居转发。而对于距离矢量在发送路由更新之前必须运行算法并更新自身的路由表,甚至对于触发路由器也是如此,所以当拓扑发生改变时,链路状态路由协议收敛速度远远快于距离矢量协议。
序列号:
当拓扑中的所有路由器都收到所有的LSA后,泛洪扩散必须停止;为了解决这个问题,在路由器触发发送一个LSA的时候会生成一个序列号,在泛洪扩散过程中这个序列号不会发生改变,与LSA的其他信息一同被保存在路由器的拓扑数据库中,当路由器收到与数据库中已存在的LSA且序列号相同时,路由器将丢弃这些信息。而如果信息相同但是序列号更大,那么接收的信息和新序列号被保存到数据库中,并且泛洪扩散该LSA。综上所述,当所有路由器都收到LSA最新拷贝时,泛洪扩散将停止。
注:关于序列号空间的更多描述与计算方法请参考《TCP/IP路由技术(第一卷)》p121内容。
老化(aging):
LSA格式中包含一个用于通告年龄的字段。当LSA被创建时,路由器将该字段设置为0,并随着数据包的扩散,每台路由器中都会增加通告中的年龄段。
老化过程为泛洪扩散过程增加了一层可靠性,该协议为网络定义了一个最大年龄差距(MaxAgeDiff)。路由器有可能接收到一个LSA的多个拷贝,其中序列号相同,年龄不同,如果年龄的差距小于MaxAgeDiff,那么认为是由于网络的正常延时造成了年龄的差异,因此数据库保留原有的LSA,新收到的LSA不被扩散;如果年龄差距超过MaxAgeDiff,那么认为该网络发生异常,在这种情况下较新的LSA被记录下来并将数据包扩散出去。OSPF的MaxAgeDiff为15分钟。
若LSA驻留在数据库中,则LSA的年龄会不断增加。如果链路状态记录的年龄增加到某个最大的年龄值(MaxAge)----由特定的路由选择协议定义----那么一个带有Maxage值得LSA将被泛洪扩散到所有邻居,邻居随即从数据库中删除相关记录。
当LSA的年龄达到maxage时,链路状态刷新计时器(LSRefeshTime)将定期的确认LSA并且在达到最大年龄之前将计时器复位。
OSPF定义的MaxAge为1个小时,LSRefeshTime为30分钟。
链路状态数据库:
一台路由器中所有有效的LSA都被存放在它的链路状态数据库中,正确的LSA将可以描述一个OSPF区域网络拓扑的结构。
SPF算法:
E.W.Dijkstra原稿对SPF算法的解释:
构造一棵树【a】,使n个节点之间的总长最小(树是一个在每两个节点之间仅有一条路径的图)。
在我们给出的构造过程中,分枝被分成3个集合:
I. 被明确分配给构造中的树的分枝(它们将在子树中);
I I.这个分枝的隔壁分枝被添加到集合I;
I I I.剩余分枝(抛弃或不考虑);
节点被分成两个集合:
被集合I中的分枝连接的点;
剩余的节点(集合I I中有且仅有一个分枝将指向这些节点中的每一个节点)。
下面我们开始构造树,首先选择任意一个节点作为集合A中仅有的成员,并将所有拿到这个节点做端点的分枝放入集合I I中。开始集合I是空的。然后我们重复执行下面两步。
步骤1:集合I I中最短的分枝被移出并加入集合I。结果,一个节点被从集合B传送到集合A。
步骤2:考虑从这个节点(刚才被传送到集合A中的节点)通向集合B中节点的分枝。如果构建中的分枝长于集合I I中相应的分枝,呢么分枝被丢弃;否则,用它替代I I中相应的分枝,并且丢弃后者。
接着我们回到第一步并重复此过程直到集合I I和集合B为空。集合I中的分枝形成所要求的树。
配合路由器的算法,上述分为3个集合:I、I I、I I I;
路由器SPF算法的步骤:
步骤1:路由器初始化树数据库,将自己作为树的根,表明路由器作为它自己的邻居代价为0;
步骤2:在链路状态数据库中,所有描述通向根路由器邻居链路的三元组(路由器ID、邻居ID、代价)被添加进候选对象数据库中;
步骤3:计算从根到每条链路的代价,候选对象数据库中代价最小的链路被移到树数据库中,如果有多条链路离根最短代价相同,则选择其中一条;
步骤4:检查添加到树数据库中的邻居ID。除了邻居ID已经存在树数据库中的三元组之外,链路状态数据库中的描述路由邻居的三元组被添加到候选对象数据库中;
步骤5:如果候选对象数据库还有剩余表项,回到第3步。如果候选数据库为空,那么终止算法。在算法终止时,在树数据库中,每个单一邻居ID表项将表示1台路由器,到此最短路径树构造完毕。
图1.4.5
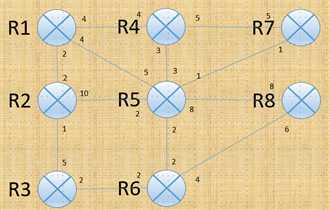
注:链路代价是按照出站接口方向计算的,并且在一个网络内所有接口的代价不一定也没必要完全相同;
表1.4.6:按照图1.4.5所示网络整理的链路状态数据库
|
路由器ID |
邻居ID |
代价 |
|
R1 |
R2 |
2 |
|
R1 |
R4 |
4 |
|
R1 |
R5 |
4 |
|
R2 |
R1 |
2 |
|
R2 |
R5 |
10 |
|
R2 |
R3 |
1 |
|
R3 |
R2 |
5 |
|
R3 |
R6 |
2 |
|
R4 |
R1 |
4 |
|
R4 |
R5 |
3 |
|
R4 |
R7 |
5 |
|
R5 |
R1 |
5 |
|
R5 |
R2 |
2 |
|
R5 |
R4 |
3 |
|
R5 |
R6 |
2 |
|
R5 |
R7 |
1 |
|
R5 |
R8 |
8 |
|
R6 |
R3 |
2 |
|
R6 |
R5 |
2 |
|
R6 |
R8 |
4 |
|
R7 |
R4 |
5 |
|
R7 |
R5 |
1 |
|
R8 |
R5 |
8 |
|
R8 |
R6 |
6 |
表1.4.7:对表1.4.6的数据库进行SPF算法
|
候选对象 |
到根代价 |
树数据库 |
描述 |
|
|
|
R1,R1,0 |
路由器R1把自己作为树的根 |
|
R1 R2 2 R1 R4 4 R1 R5 4 |
2 4 4 |
R1,R1,0 |
到所有R1邻居的链路被添加到候选对象列表 |
|
R1 R4 4 R1 R5 4 R2 R5 10 R2 R3 1 |
4 4 12 3 |
R1 R1 0 R1 R2 2
|
R1 R2 2是所有候选列表中代价最小的链路被添加到树中,所有R2邻居除了已在树中的都被添加到候选列表,R1 R5 4到R5的代价比R2 R5 10小,所以在候选列表中丢弃R2 R5 10 |
|
R1 R4 4 R1 R5 4 R3 R6 2 |
4 4 5 |
R1 R1 0 R1 R2 2 R2 R3 1 |
R2 R3 1在候选列表中是最小的,被添加进树中,所以R3的邻居除了已在树中的都将变为候选对象 |
|
R1 R5 4 R3 R6 2 R4 R5 3 R4 R7 5 |
4 5 7 9 |
R1 R1 0 R1 R2 2 R2 R3 1 R1 R4 4 |
R1 R4 4和R1 R5 4离R1的代价都为4,R3 R6 2代价为5;R1 R4 4被添加到树中,并且它的邻居成为候选对象;候选列表中从R1出发R4 R5 3因代价更高而被丢弃 |
|
R3 R6 2 R4 R7 5 R5 R6 2 R5 R7 1 R5 R8 8 |
5 9 6 5 12 |
R1 R1 0 R1 R2 2 R2 R3 1 R1 R4 4 R1 R5 4 |
R1 R5 1被添加到树种,所有不在树中的R5邻居都被添加进候选列表。到R7的代价最高链路被丢弃。 |
|
R5 R6 2 R5 R7 1 R5 R8 8 R6 R8 4 |
6 5 12 9 |
R1 R1 0 R1 R2 2 R2 R3 1 R1 R4 4 R1 R5 4 R3 R6 2 |
R3 R6 2被添加进树种并且它的邻居被添加进候选列表。由于从R1触发R5 R7 1代价相同(5),所以使用R5 R7 1替代,到R7代价更高的被丢弃 |
|
R6 R8 4 |
9 |
R1 R1 0 R1 R2 2 R2 R3 1 R1 R4 4 R1 R5 4 R3 R6 2 R5 R7 1 |
R5 R7 1被添加到树种。R7所有邻居都在树中,所以没有对象被添加进候选列表中 |
|
|
|
R1 R1 0 R1 R2 2 R2 R3 1 R1 R4 4 R1 R5 4 R3 R6 2 R5 R7 1 R6 R8 4 |
R6 R8 4是候选列表中代价最小的链路,所以被添加到树中,候选列表不再有候选对象,所以算法终止。最短路径树构造完毕。 |
区域:
一个区域是构成一个网络的路由器的一个子集。将网络划分为区域是针对链路状态协议的3个不理影响所采取的措施:
当一个网络被划分为多个区域时,在一个区域内的路由器仅需要在本区域扩散LSA,因而只需要维护本区域的链路状态数据库。数据库越小,相应的需要内存越小,运行SPF算法需要的CPU周期也越小。如果拓扑改变频繁,引起的扩散也将被限制在不稳定区域。
区域边界路由器:连接两个区域的路由器,它属于所连接的两个区域,而且必须为每个区域维护各自的拓扑数据库。
标签:
原文地址:http://www.cnblogs.com/commanderzhu/p/4824889.html