标签:
本系列文章会深入研究 Ceph 以及 Ceph 和 OpenStack 的集成:
(1)安装和部署
(2)Ceph 与 OpenStack 集成的实现
(3)TBD
为了深入学习 Ceph 以及 Ceph 和 OpenStack 的集成,搭建了如下的测试环境:
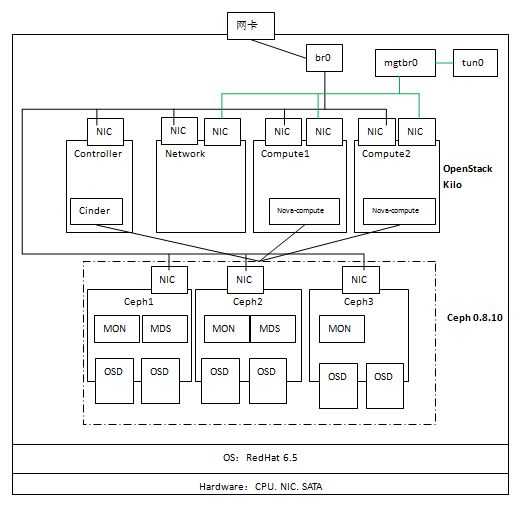
硬件环境:
软件环境:
从上图可见,该环境使用三个虚机作为Ceph节点,每个节点上增加两个虚拟磁盘 vda 和 vdb 作为 OSD 存储磁盘,每个节点上安装 MON,前两个节点上安装 MDS。三个节点使用物理网络进行通信。
(0)准备好三个节点 ceph{1,2,3}:安装操作系统、设置 NTP、配置 ceph1 可以通过 ssh 无密码访问其余节点(依次运行 ssh-keygen,ssh-copy-id ceph2,ssh-copy-id ceph3,修改 /etc/ssh/sshd_config 文件中的 PermitRootLogin yes 来使得 ssh 支持 root 用户)
| 节点名称 | IP 地址 | 部署进程 | 数据盘 |
| ceph1 | 192.168.1.194 | 1MON+1MDS+2OSD | /dev/vda, /dev/vdb |
| ceph2 | 192.168.1.195 | 1MON+1MDS+2OSD | /dev/vda, /dev/vdb |
| ceph3 | 192.168.1.218 | 1MON+1OSD | /dev/vda, /dev/vdb |
(1)在 ceph1 上安装 ceph-deploy,接下来会使用这个工具来部署 ceph 集群
(2)在ceph 上,运行 ceph-deploy install ceph{1,2,3} 命令在各节点上安装 ceph 软件。安装好后可以查看 ceph 版本:
root@ceph1:~# ceph -v ceph version 0.80.10 (ea6c958c38df1216bf95c927f143d8b13c4a9e70)
(3)在 ceph1 上执行以下命令创建 MON 集群
ceph-deploy new ceph{1,2,3} ceph-deploy mon create ceph{1,2,3} ceph-deploy mon create-initial
完成后查看 MON 集群状态:
root@ceph1:~# ceph mon_status {"name":"ceph1","rank":0,"state":"leader","election_epoch":16,"quorum":[0,1,2],"outside_quorum":[],"extra_probe_peers":[],"sync_provider":[],"monmap":{"epoch":1,"fsid":"4387471a-ae2b-47c4-b67e-9004860d0fd0","modified":"0.000000","created":"0.000000","mons":[{"rank":0,"name":"ceph1","addr":"192.168.1.194:6789\/0"},{"rank":1,"name":"ceph2","addr":"192.168.1.195:6789\/0"},{"rank":2,"name":"ceph3","addr":"192.168.1.218:6789\/0"}]}}
(4)在各节点上准备数据盘,只需要在 fdisk -l 命令输出中能看到数据盘即可,不需要做任何别的操作,然后在 ceph1 上执行如下命令添加 OSD
ceph-deploy --overwrite-conf osd prepare ceph1:/data/osd:/dev/vda ceph2:/data/osd:/dev/vda ceph3:/data/osd:/dev/vda ceph-deploy --overwrite-conf osd activate ceph1:/data/osd:/dev/vda ceph2:/data/osd:/dev/vda ceph3:/data/osd:/dev/vda ceph-deploy --overwrite-conf osd prepare ceph1:/data/osd2:/dev/vdb ceph2:/data/osd2:/dev/vdb ceph3:/data/osd2:/dev/vdb ceph-deploy --overwrite-conf osd activate ceph1:/data/osd2:/dev/vdb ceph2:/data/osd2:/dev/vdb ceph3:/data/osd2:/dev/vdb
完成后查看 OSD 状态:
root@ceph1:~# ceph osd tree # id weight type name up/down reweight -1 0.1399 root default -2 0.03998 host ceph1 3 0.01999 osd.3 up 1 6 0.01999 osd.6 up 1 -3 0.05997 host ceph2 4 0.01999 osd.4 up 1 7 0.01999 osd.7 up 1 -4 0.03998 host ceph3 5 0.01999 osd.5 up 1 8 0.01999 osd.8 up 1
(5)将 Admin key 复制到其余各个节点,然后安装 MDS 集群
ceph-deploy admin ceph1 ceph2 ceph3
eph-deploy mds create ceph1 ceph2
完成后可以使用 “ceph mds” 命令来操作 MDS 集群,比如查看状态:
root@ceph1:~# ceph mds stat e13: 1/1/1 up {0=ceph1=up:active}, 1 up:standby
看起来 MDS 集群是个 active/standby 模式的集群。
至此,Ceph 集群部署完成,可以使用 ceph 命令查看集群状态:
root@ceph1:~# ceph mds stat e13: 1/1/1 up {0=ceph1=up:active}, 1 up:standby root@ceph1:~# ceph -s cluster 4387471a-ae2b-47c4-b67e-9004860d0fd0 health HEALTH_OK monmap e1: 3 mons at {ceph1=192.168.1.194:6789/0,ceph2=192.168.1.195:6789/0,ceph3=192.168.1.218:6789/0}, election epoch 16, quorum 0,1,2 ceph1,ceph2,ceph3 mdsmap e13: 1/1/1 up {0=ceph1=up:active}, 1 up:standby osdmap e76: 10 osds: 7 up, 7 in
在这过程中,失败和反复是难免的,在任何时候,可以使用如下的命令将已有的配置擦除然后从头安装:
ceph-deploy purge ceph{1,2,3}
ceph-deploy purgedata ceph{1,2,3}
ceph-deploy forgetkeys
为方便起见,管理网络直接连接物理网卡;租户网络就比较麻烦一点,因为机器上只有一个物理网卡,幸亏所有的计算节点都在同一个物理服务器上,因此可以:
1. 在物理服务器上,创建一个虚拟网卡 tap0,再创建一个 linux bridge ‘mgtbr0’
tunctl -t tap0 -u root chmod 666 /dev/net/tun ifconfig tap0 0.0.0.0 promisc brctl addbr mgtbr0 brctl addif mgtbr0 tap0
2. 这是 mgtbr0 的配置脚本:
[root@rh65 ~]# cat /etc/sysconfig/network-scripts/ifcfg-mgtbr0 DEVICE=mgtbr0 TYPE=Ethernet ONBOOT=yes NM_CONTROLLED=no BOOTPROTO=static IPADDR=10.0.0.100 PREFIX=24 GATEWAY=10.0.0.1 DEFROUTE=yes IPV4_FAILURE_FATAL=yes IPV6INIT=no TYPE=Bridge
3. 在网络和各计算节点上,增加一块网卡,连接到物理服务器上的 bridge。
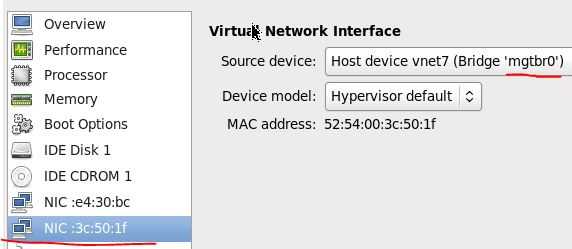
把所有的节点连接到管理和租户网络后,在物理服务器上看到的 linux bridge 是这样子:
bridge name bridge id STP enabled interfaces br0 8000.3440b5d905ee no eth1 #物理网卡 vnet0 #controller 节点 vnet1 #network 节点 vnet2 #compute1 节点 vnet3 #compute2 节点 vnet4 #ceph1 节点 vnet5 #ceph2 节点 vnet8 #ceph3 节点 br1 8000.000000000000 no mgtbr0 8000.f29e2c075ca6 no tap0 #虚拟网卡 vnet6 #network 节点 vnet7 #compute1 节点 vnet9 #compute2 节点
参考 Installation Guide for Ubuntu 14.04 (LTS) 完成配置,没感觉到 Kilo 版本和 Juno 版本太大的不同,除了 keystone 使用 Apache web server 替代了 Keystone WSGI Server 以外(注意不能同时启动 apache2 和 keystone 服务,两者有冲突,感觉 Kilo 版本中 Identity 部分改动很大,还是存在不少问题)。
本例中,OpenStack Cinder、Glance 和 Nova 分别会将卷、镜像和虚机镜像保存到 Ceph 分布式块设备(RBD)中。
(1)在 ceph 中创建三个 pool 分别给 Cinder,Glance 和 nova 使用
ceph osd pool create volumes 64 ceph osd pool create images 64 ceph osd pool create vms 64
(2)将 ceph 的配置文件传到 ceph client 节点 (glance-api, cinder-volume, nova-compute andcinder-backup)上:
ssh controller sudo tee /etc/ceph/ceph.conf </etc/ceph/ceph.conf ssh compute1 sudo tee /etc/ceph/ceph.conf </etc/ceph/ceph.conf ssh compute2 sudo tee /etc/ceph/ceph.conf </etc/ceph/ceph.conf
(3)在各节点上安装ceph 客户端
在 glance-api 节点,安装 librbd sudo apt-get install python-rbd 在 nova-compute 和 cinder-volume 节点安装 ceph-common: sudo apt-get install ceph-common
(4)配置 cinder 和 glance 用户访问 ceph 的权限
# cinder 用户会被 cinder 和 nova 使用,需要访问三个pool
ceph auth get-or-create client.cinder mon ‘allow r‘ osd ‘allow class-read object_prefix rbd_children, allow rwx pool=volumes, allow rwx pool=vms, allow rx pool=images‘
# glance 用户只会被 Glance 使用,只需要访问 images 这个 pool ceph auth get-or-create client.glance mon ‘allow r‘ osd ‘allow class-read object_prefix rbd_children, allow rwx pool=images‘
(5)将 client.cinder 和 client.glance 的 keystring 文件拷贝到各节点并设置访问权限
ceph auth get-or-create client.glance | ssh controller sudo tee /etc/ceph/ceph.client.glance.keyring
ssh controller sudo chown glance:glance /etc/ceph/ceph.client.glance.keyring
ceph auth get-or-create client.cinder | ssh controller sudo tee /etc/ceph/ceph.client.cinder.keyring
ssh controller sudo chown cinder:cinder /etc/ceph/ceph.client.cinder.keyring
ceph auth get-or-create client.cinder | ssh compute1 sudo tee /etc/ceph/ceph.client.cinder.keyring
ceph auth get-or-create client.cinder | ssh compute2 sudo tee /etc/ceph/ceph.client.cinder.keyring
(6)在 compute1 和 compute2 节点上做 libvirt 配置
ceph auth get-key client.cinder | ssh compute1 tee client.cinder.key
cat > secret.xml <<EOF
<secret ephemeral=‘no‘ private=‘no‘>
<uuid>e21a123a-31f8-425a-86db-7204c33a6161</uuid>
<usage type=‘ceph‘>
<name>client.cinder secret</name>
</usage>
</secret>
EOF
sudo virsh secret-define --file secret.xml
sudo virsh secret-set-value --secret e21a123a-31f8-425a-86db-7204c33a6161 --base64 $(cat client.cinder.key) && rm client.cinder.key secret.xml
在 /etc/glance/glance-api.conf 文件中做如下修改: [DEFAULT] ... show_image_direct_url = True ... [glance_store] stores=glance.store.rbd.Store default_store = rbd rbd_store_pool = images rbd_store_user = glance rbd_store_ceph_conf = /etc/ceph/ceph.conf rbd_store_chunk_size = 8
修改 /etc/cinder/cinder.conf: [DEFAULT] ... #volume_group = cinder-volumes volume_driver = cinder.volume.drivers.rbd.RBDDriver rbd_pool = volumes rbd_ceph_conf = /etc/ceph/ceph.conf rbd_flatten_volume_from_snapshot = false rbd_max_clone_depth = 5 rbd_store_chunk_size = 4 rados_connect_timeout = -1 glance_api_version = 2 rbd_user = cinder rbd_secret_uuid = e21a123a-31f8-425a-86db-7204c33a6161 ...
在每个计算节点上的 /etc/nova/nova.conf 文件中做如下修改: [libvirt] images_type = rbd images_rbd_pool = vms images_rbd_ceph_conf = /etc/ceph/ceph.conf rbd_user = cinder rbd_secret_uuid = e21a123a-31f8-425a-86db-7204c33a6161 disk_cachemodes="network=writeback" hw_disk_discard = unmap
inject_password = false
inject_key = false
inject_partition = -2
live_migration_flag="VIR_MIGRATE_UNDEFINE_SOURCE,VIR_MIGRATE_PEER2PEER,VIR_MIGRATE_LIVE,VIR_MIGRATE_PERSIST_DEST,VIR_MIGRATE_TUNNELLED"
至此,环境安装和配置完成,通过 cinder,glance 和 nova 命令创建的卷、镜像和虚机的镜像都会被保存在 Ceph 的 RBD 中。接下来的文章会深入分析其中的原理和实现。
参考文档:
http://docs.ceph.com/docs/master/rbd/rbd-openstack/
理解 OpenStack & Ceph (1):Ceph + OpenStack 集群部署和配置
标签:
原文地址:http://www.cnblogs.com/sammyliu/p/4804037.html