标签:
------Java培训、Android培训、iOS培训、.Net培训、期待与您交流! -------
正则表达式
正则表达式用于操作字符串数据。通过一些特定的符号来体现的。所以我们为了掌握正则表达式,必须要学习一些符号。
正则表达式可以简化对字符串的复杂操作。虽然简化了操作,但是阅读性差。
1、常见符号
说明:X表示字符X或者匹配的规则。
1、字符
x 字符 x
\\ 反斜线字符
\t 制表符 (‘\u0009‘)
\n 新行(换行)符 (‘\u000A‘)
\r 回车符 (‘\u000D‘)
\f 换页符 (‘\u000C‘)
\a 报警 (bell) 符 (‘\u0007‘)
2、字符类
[abc] a、b或 c(简单类)
[^abc] 任何字符,除了 a、b或 c(否定)
[a-zA-Z] a到 z或 A 到 Z,两头的字母包括在内(范围)
[a-d[m-p]] a到 d或 m 到 p:[a-dm-p](并集)
[a-z&&[def]] d、e或 f(交集)
[a-z&&[^bc]] a到 z,除了 b和 c:[ad-z](减去)
[a-z&&[^m-p]] a到 z,而非 m到 p:[a-lq-z](减去)
3、预定义字符类
. 任何字符(与行结束符可能匹配也可能不匹配)
\d 数字:[0-9]
\D 非数字: [^0-9]
\s 空白字符:[ \t\n\x0B\f\r]
\S 非空白字符:[^\s]
\w 单词字符:[a-zA-Z_0-9]
\W 非单词字符:[^\w]
4、边界匹配器
^ 行的开头
$ 行的结尾
\b 单词边界
\B 非单词边界
\A 输入的开头
\G 上一个匹配的结尾
\Z 输入的结尾,仅用于最后的结束符(如果有的话)
\z 输入的结尾
5、Greedy数量词
X? X,一次或一次也没有
X* X,零次或多次
X+ X,一次或多次
X{n} X,恰好 n次
X{n,} X,至少 n次
X{n,m} X,至少 n次,但是不超过 m 次
6、组和捕获
捕获组可以通过从左到右计算其开括号来编号。例如,在表达式 ((A)(B(C)))中,存在四个这样的组:
1 ((A)(B(C)))
2 \A
3 (B(C))
4 (C)
组零始终代表整个表达式。在替换中常用$匹配组的内容。
2、功能
正则表达式常见功能:匹配、切割、替换、获取
匹配其实使用的就是String类中的matches方法。
切割其实使用的就是String类中的split方法。
替换其实使用的就是String类中的replace方法。
获取将正则规则进行对象的封装。Pattern p = Pattern.compile("a*b");通过正则对象的matcher方法字符串相关联。获取要对字符串操作的匹配器对象Matcher。
演示匹配:
1 static void demo1() 2 { 3 String tel = "15800001111"; 4 //手机号的匹配规则,第一位是1,第二位是358,后面9位数字 5 String regex = "1[358]\\d{9}"; 6 boolean b = tel.matches(regex); 7 System.out.println(tel + ":" + b); 8 }
演示切割:
1 static void demo2() 2 { 3 String str = "zhangsan xiaoqiang zhaoliu"; 4 //匹配一个或者多个空格为 5 String[] names = str.split(" +"); 6 for(String name : names){ 7 System.out.println(name); 8 } 9 str = "zhangsan.xiaoqiang.zhaoliu"; 10 //以点为分隔符 11 names = str.split("\\."); 12 for(String name : names){ 13 System.out.println(name); 14 } 15 16 str = "zhangsanttttxiaoqiangmmmmmzhaoliu"; 17 //.表示任意字符,(.)表示一组,\\1+表示与第1组相同的出现1次以上 18 names = str.split("(.)\\1+"); 19 for(String name : names){ 20 System.out.println(name); 21 } 22 }
演示替换:
1 public static void demo5() 2 { 3 String str = "zhangsanttttxiaoqiangmmmmmzhaoliu"; 4 //与分隔一样,这里也是以一个字符替换叠词 5 str = str.replaceAll("(.)\\1+","$1"); 6 System.out.println(str); 7 8 //替换一个手机号码的中间四位为* 9 str = "15800001111"; 10 str = str.replaceAll("(\\d{3})(\\d{4})(\\d{4})","$1****$2"); 11 System.out.println(str); 12 }
演示获取:
1 static void demo6() 2 { 3 String str = "da jia hao,ming tian bu fang jia"; 4 //获取三个字母组成的单词的正则 5 String regex = "\\b[a-z]{3}\\b"; 6 //1. 将正则封装成对象 7 Pattern p = Pattern.compile(regex); 8 //2. 通过正则对象获取匹配器对象 9 Matcher m = p.matcher(str); 10 //查找:find(); 11 while(m.find()) 12 { 13 System.out.println(m.group());//获取匹配的子序列 14 System.out.println(m.start() + ":" + m.end()); 15 } 16 }
Pattern类为正则表达式的编译表示形式。指定为字符串的正则表达式必须首先被编译为此类的实例。然后,可将得到的模式用于创建Matcher对象,依照正则表达式,该对象可以与任意字符序列匹配。执行匹配所涉及的所有状态都驻留在匹配器中,所以多个匹配器可以共享同一模式。
下面通过一些小练习来熟悉一下正则表达式
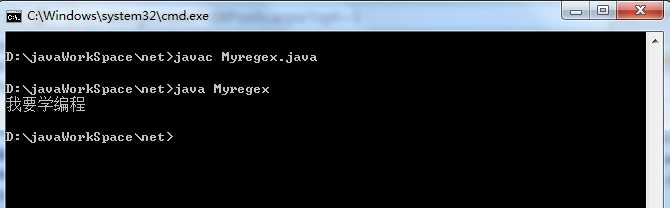
1 import java.util.*; 2 class Myregex 3 { 4 public static void main(String[] args) 5 { 6 exec01(); 7 } 8 /* 9 1. 治疗口吃:我我 ... 我我 ... 我我我我 ... 要要要要 ... 10 要要要要 ... 学学学学学 ...学学编编 ... 编编编编 .. 编 .. 编 ... 程程 ... 程程程 11 除去重复的字符。 12 */ 13 static void exec01() 14 { 15 String str="我我...我我...我我我我...要要要要..要要要要...学学学学学...学学编编.编编编编..编..编...程程...程程程"; 16 //1、去掉.,.比较特殊,在正则中代表任意字符所以要加转意符 17 str=str.replaceAll("\\.+",""); 18 //2、替换叠词; 19 str=str.replaceAll("(.)\\1+","$1"); 20 System.out.println(str); 21 } 22 }
结果为:
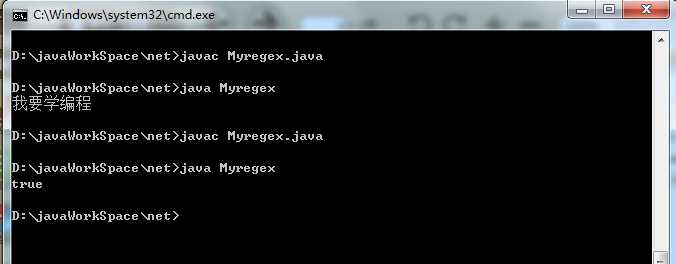
1 import java.util.*; 2 class Myregex 3 { 4 public static void main(String[] args) 5 { 6 exec02(); 7 } 8 /* 9 2、对邮件地址的校验 10 */ 11 static void exec02() 12 { 13 String mail = "abc1@sina.com"; 14 15 String regex = "[a-zA-Z0-9_]+@[a-zA-Z0-9]+(\\.[a-zA-Z]{1,3})+"; 16 //不精确的校验可以写为“\\w+@\\w+(\\.\\w)+”; 17 boolean b=mail.matches(regex); 18 System.out.println(b); 19 } 20 }
结果为真
正则表达式主要在于符号的熟悉,需要勤加练习,多练就能记住各个符号,就能熟能生巧,写出高效的正则表达式。
标签:
原文地址:http://www.cnblogs.com/dengzhenyu/p/4842804.html