标签:
在介绍Elasticsearch的用法之前先讲讲为什么要用它吧。首先学习搜索引擎,肯定不可避免的都听过lucene,solr和Elasticsearch都是基于它的。spinx文章很多,但是数据库的入侵性太强(插件模式)。Elasticsearch是当下最流行的分布式搜索引擎之一。solr也稍微玩过,文章也多。同时也希望能通过Elasticsearch进一步学习完善自己对于分布式的学习。更深入的同学可以考虑开始学习ELK(Elasticsearch, Logstash, Kibana)。
推荐:《Elasticsearch-definitive-guide》
看过这本书之后入门就成了很简单的事,书很浅显易懂,没什么特别难的地方。
其中有一个例子写的非常好,可以作为全局引导大家学习,摘抄一部分过来:
我们首先要做的是存储员工数据,每个文档代表一个员工。在Elasticsearch中存储数据的行为就叫做索引(indexing),不过在索引之前,我们需要明确数据应该存储在哪里。
在Elasticsearch中,文档归属于一种类型(type),而这些类型存在于索引(index)中,我们可以画一些简单的对比图来类比传统关系型数据库:
Relational DB -> Databases -> Tables -> Rows -> Columns Elasticsearch -> Indices -> Types -> Documents -> FieldsElasticsearch集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型(types)(表),每一个类型包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。
「索引」含义的区分
你可能已经注意到索引(index)这个词在Elasticsearch中有着不同的含义,所以有必要在此做一下区分:
- 索引(名词) 如上文所述,一个索引(index)就像是传统关系数据库中的数据库,它是相关文档存储的地方,index的复数是indices 或indexes。
- 索引(动词) 「索引一个文档」表示把一个文档存储到索引(名词)里,以便它可以被检索或者查询。这很像SQL中的
INSERT关键字,差别是,如果文档已经存在,新的文档将覆盖旧的文档。- 倒排索引 传统数据库为特定列增加一个索引,例如B-Tree索引来加速检索。Elasticsearch和Lucene使用一种叫做倒排索引(inverted index)的数据结构来达到相同目的。
默认情况下,文档中的所有字段都会被索引(拥有一个倒排索引),只有这样他们才是可被搜索的。
理解上面的索引介绍后,接下来就是很入门的开工工作了。安装Elasticsearch:

这个插件主要是用来管理索引数据和状态,文档中有详细说明,安装步骤也很简单,用命令行转bin目录下运行插件安装
完成后,打开http://localhost:9200/_plugin/head/就可以看到下面这个管理界面
这样子安装算告一段落了,可以开始写点代码做点实事了,我用的是NEST这个Client工具,大家可以根据自己的语言选择工具。
一般而言,我们用到搜索的功能都是全文索引,否则也没必要用搜索引擎了:
var node = new Uri("http://localhost:9200"); var settings = new ConnectionSettings( node, defaultIndex: "my-application" ); var client = new ElasticClient(settings); var person = new Person { Id = "2", Firstname = "中文测试一下 天才", Lastname = "哈哈 你是天才么?" }; var index = client.Index(person, i => i .Index("sample-index") .Type("sample-type") .Id("1-should-not-be-the-id") .Refresh() .Ttl("1m") ); //query_string只是其中一种最常用查询,Operator枚举的Or和And可以根据全文检索的业务要求使用,以下查询就是为了最简单的分页全文检索接口 var searchResults = client.Search<Person>(s => s .Index("sample-index") .Type("sample-type") .Query(q => q.QueryString(qs => qs.Query("天才").DefaultOperator(Operator.And))) .From(0) //分页页码 .Size(10) //分页尺寸 ); foreach (var item in searchResults.Documents) { Console.WriteLine("item:" + Newtonsoft.Json.JsonConvert.SerializeObject(item)); } Console.ReadLine();
运行结果:


以上只用到了QueryString,当然它的查询方法远不只这些,具体的查询方法我这里就不班门弄斧了。推荐去看文档。附上NEST的文档:http://nest.azurewebsites.net/nest/quick-start.html
Elasticsearch致力于隐藏分布式系统的复杂性。以下这些操作都是在底层自动完成的:
你可以看到以下默认的分片情况:
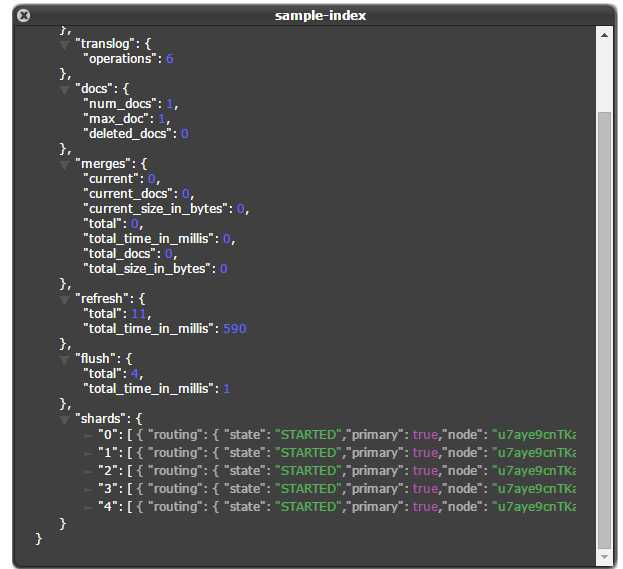
很明显以上分片都在同一个node上,而分片又组成了集群。其中node本身是有可能存在主分片和复制分片,而节点与节点之间又有可能通过分片联系。
还有一些很关键的集群模块,集群健康监控,Elasticsearch健康有三种状态:green、yellow或red。限制query执行时占用的JVM Heap sized等等。
对于分布式这块这里就不能再往下展开了,具体可学习文中提到的那本书,里面有详细介绍。而性能方面,由于现在公司的业务根本达不到这个数量级,暂时无法给出较好的对比。千百万级别,不管solr,还是ES都是OK的。上亿恐怕要斟酌和优化了。
标签:
原文地址:http://www.cnblogs.com/javen_lin/p/4845397.html