标签:
该论文是一篇来自CMU 的CVPR2013文章,提出了一种基于稀疏编码的轮廓特征,简称HSC(Histogram of Sparse Code),并在目标检测中全面超越了HOG(Histogram of Gradient)本文介绍HSC的思路及其计算过程。
如图3所示,HSC方法种采用了疏编码原理来提取图像特征的方法,即根据学习得到的字典对图像块Patch进行重新编码。
算法主要包括了两部分,分别是字典学习和特征提取。
字典学习。
1. 类似于基于K-Means方法的字典学习,稀疏编码的字典学习室通过求解一个关于1范数的最优化问题。字典学习的步骤如下:
2. 初始化。假设字典的长度为M,图像小块的宽高大小为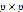 ,其中p可以去(3,5,7,…)。
,其中p可以去(3,5,7,…)。
3. 图像小块获取。收集关于某一类目标的图像,然后将他们切成正方形的小块,宽高大小为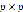 ,如图1所示。将图像小块按照图像灰度,先行后列的展成向量形式,于是图像小块的集合记为
,如图1所示。将图像小块按照图像灰度,先行后列的展成向量形式,于是图像小块的集合记为 。
。
4. 字典学习。根据集合 ,学习得到最优的字典
,学习得到最优的字典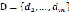 ,字典的行列为
,字典的行列为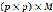 ,
,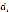 表示长度为
表示长度为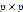 的列向量,通过求解以下方程得到:
的列向量,通过求解以下方程得到:
![]()
其中 ,
,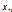 表示长度为
表示长度为 的列向量。此最优化问题可以通过现有的一些软件工具求解得到,如K-SVD方法,通过交替式的来求解最优D和X。论文中指定K为1。
的列向量。此最优化问题可以通过现有的一些软件工具求解得到,如K-SVD方法,通过交替式的来求解最优D和X。论文中指定K为1。
5. 输出字典D。如图2所示。


图1、图像小块获取

图2、学习得到的字典
特征提取
1. 学习到字典之后,可利用字典对指定的图像进行特征的提取。提取的过程如下:
2. 初始化,给定一张图像,提取指定位置的特征,如图1所示,提取狗的特征,将狗分成若干个小单元块,简称为Cell。
3. 单元块的稀疏编码。如图1所示,对每个cell,记为y,进行稀疏编码。即已知y和字典D,求解其最优的稀疏表达x: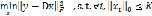 注意x的维度和y是不相等的,x的维度是M
注意x的维度和y是不相等的,x的维度是M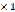 列向量,x是y的一个稀疏的表达,x的元素只有少数是非零的。
列向量,x是y的一个稀疏的表达,x的元素只有少数是非零的。
4. 平滑稀疏解x。对x中的每个元素,四邻域的双线性插值。
5. 计算x单元块的16邻域单元块的平均单元块,即相应元素相加然后除以16。
6. 归一化平均单元块x。归一化直方图的方法是二范数归一化,即
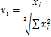
7. 将所有归一化后的平均单元块,按照先行后列的顺序展开成向量,所得到的向量即为对应的HSC特征直方图。
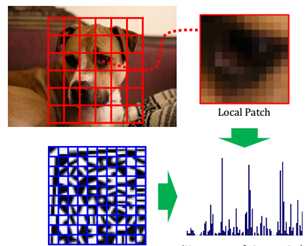
图3、HSC特征提取流程
图片有些不清晰,附上word版本:HSC特征提取cvpr2013.zip
标签:
原文地址:http://www.cnblogs.com/cv-pr/p/4845675.html