标签:
0x01 :代码规划的要求
Q:这些规范都是官僚制度下产生的浪费大家的编程时间、影响人们开发效率, 浪费时间的东西。(反驳)
首先,我们需要明确编码规范的定义,编码规范同时包括了编码风格和其它规范(代码设计上的规范,如设计模式、程序设计、模块之间的逻辑关联等)。
编码风格,牵扯到“缩进、空格使用、注释、命名习惯”等多方面的因素,是依致特定编程语言制定的软件工程开发的“约定”,而相同的编码风格,可以使得软件开发过程中轻松浏览任意一段代码,充分保证不同的开发人员能够依据统一的编码格式轻松理解代码的逻辑层次,内在含义(比如匈牙利命名法)等,因此,简而言之,代码风格的规范会带来三个较为明显的好处:
![]() 代码更易维护:软件工程中程序的开发、维护和测试必然会由不同的开发人员处理,因此依据统一的代码风格,可以快速推断出代码的作用,变量的实际含义,甚至能准确定位到某一引入的包,有效提高代码的可维护性。
代码更易维护:软件工程中程序的开发、维护和测试必然会由不同的开发人员处理,因此依据统一的代码风格,可以快速推断出代码的作用,变量的实际含义,甚至能准确定位到某一引入的包,有效提高代码的可维护性。
![]() 保证代码集体所有制,避免交流壁垒:代码集体所有制,能够有效增大巴士因子(一个项目能承受多少个程序员被车撞了而不影响项目的正常进行),即不会因为少数深入理解代码、掌握大量信息的人暂时无法工作而使得项目停滞。
保证代码集体所有制,避免交流壁垒:代码集体所有制,能够有效增大巴士因子(一个项目能承受多少个程序员被车撞了而不影响项目的正常进行),即不会因为少数深入理解代码、掌握大量信息的人暂时无法工作而使得项目停滞。
![]() 消除长久的格式纷争:使得开发人员不必因为编码风格的不同而争吵,保证软件工程的开发效率。
消除长久的格式纷争:使得开发人员不必因为编码风格的不同而争吵,保证软件工程的开发效率。
代码设计上的规范,包含函数的设计规范,goto语句的跳转,错误处理等方面的问题,而缺乏一定的代码规范也将急剧增加代码可维护性。比如goto语句的大量滥用,“上帝”函数或“重复需求”函数的编写,也将导致软件工程开发效率的急剧降低,究其根源,软件开发并不是个人兴趣软件的开发,需要保证开发人员之间没有沟通壁垒,而统一的编码规范将规避这一问题。
Q:我是个艺术家,手艺人,我有自己的规范和原则。(反驳)
艺术家不等于滑稽家,就像在多数情况下有人说“画笔严重拘束了我们创造力,我要用手指涂鸦,这是我技能和创造力的体现”,可能常人也会诧异一般。对于开发人员,“自己的规范和原则”是编码过程中长期养成的习惯,因此怀有自负的心理是机器正常的。但在软件工程的团队协作中,编码风格并不影响本身思想的展示,思想、创造力、算法并不会因为编码风格的不同而受到影响;但编码风格的“特立独行“将导致其他开发人员无法理解你的代码,降低了整体的可维护性,就像艺术家因为他人无法理解作品的编码形式而受到影响。
Q:规范不能强求一律,应该允许很多例外。(反驳)
我们必须承认,对于一家公司的不同项目,拥有不同的编码规范是无可厚非的(比如对于C#这种强类型的语言,匈牙利命名法可能并非必需);但是编码规范对于某一项目而言不是最理想的,但对于大型公司而言,统一的编码风格能使得公司本身更容易对这一项目进行维护。因此,例外是可以存在的,比如,在某一项目中,我们需要遵守统一的编码规范,但特定的项目,可以扩展特定的项目规范和结构。
Q:我擅长制定编码规范,你们听我的就好了。(反驳/支持)
这种情况的需要分情况讨论:
![]() 我们必须承认,在大多数情况,统一制定的编码规范是较为理想的或是合理的,而这种抱怨的直接原因,可能就是“我认为这种编码规范近似与小学生制定的,严重降低了我的代码质量“这种傲慢自大的心理,因为代码风格虽说可能会在一定程度上降低你的积极性,但整体而言,程序较强的可读性会大大弥补这一损失。
我们必须承认,在大多数情况,统一制定的编码规范是较为理想的或是合理的,而这种抱怨的直接原因,可能就是“我认为这种编码规范近似与小学生制定的,严重降低了我的代码质量“这种傲慢自大的心理,因为代码风格虽说可能会在一定程度上降低你的积极性,但整体而言,程序较强的可读性会大大弥补这一损失。
![]() 在少部分情况,我们必须承认,荒谬的编码规范会组织一个优秀的程序员写出优秀的代码,这是,就需要你个人的努力去说法这一愚蠢的想法,但若是重新制定编码规范,对历史代码而言恐怕将会产生巨大的工作量。
在少部分情况,我们必须承认,荒谬的编码规范会组织一个优秀的程序员写出优秀的代码,这是,就需要你个人的努力去说法这一愚蠢的想法,但若是重新制定编码规范,对历史代码而言恐怕将会产生巨大的工作量。
0x02 :同伴代码复审情况
0x0204:std::getline()从VS2012到VS2013
while (getline(ex, formula) == NULL
&& getline(an, answer) == NULL) {
}
在Visual Studio 2012中编译通过而在2013版本中编译器提供了C1903的错误提示:"fatal error C1903: unable to recover from previous error(s); stopping compilation",而将“== NULL”删去后重新编译,程序编译通过且功能与此前VS2012编译的exe文件功能相同,这里我们翻阅MSDN提供的C++ Standard Library来查询std::getline()的实现过程。
template<class _E, class _TYPE, class _A> inline
basic_istream<_E, _TYPE>& getline(
basic_istream<_E, _TYPE>& Istream,
basic_string<_E, _TYPE, _A>& Xstring,
const _E _D=_TYPE::newline( )
);
以上代码段摘自https://msdn.microsoft.com/en-us/library/3ah895zy(v=vs.110).aspx,我们可以看到VS2012中平台工具集仍使用V110,而具体的范例合并于string:getline()中,简述言之即为由input stream中返回一段字符串;
l At end-of-file, in which case the internal state flag of is is set to ios_base::eofbit.
l After the function extracts an element that compares equal to delim, in which case the element is neither put back nor appended to the controlled sequence.
l After the function extracts str.max_size elements, in which case the internal state flag of is is set to ios_base::failbit.
l Some other error other than those previously listed, in which case the internal state flag of is is set to ios_base::badbit
以上信息段摘自https://msdn.microsoft.com/en-us/library/2whx1zkx(v=vs.120).aspx,我们可以看到VS2013平台工具集使用V120,而在实现过程中调用ios_base::iostate的有效位实现更广范围的检查,而关于返回值的问题,“The istream returned by getline() is having its operator void*() method implicitly called, which returns whether the stream has run into an error. As such it‘s making more checks than a call to eof().“,stackoverflow上存在一段非常精炼的回答,即在发生NULL的类似错误时通过错误信息的置位来实现,与2012相比做出了更多的检查,而MSDN文档给出的范例也首次使用如下代码段来解释说明这一新特性:
while (getline(cin, str)) {
v1.push_back(str);
}
这里特别鸣谢涛神,http://home.cnblogs.com/u/-OwO-/,能帮忙调试C1903的error提示,并最终在自己“手残重载工程“的时候想到平台工具集的变化,并最终发现VS工具集API的优化措施(Version2012-2013的变化)
0x0208:整体函数代码初步审查简述
|
函数定义 |
功能理解 |
初步审查 |
|
int cal(int fr1, int nm1, int fr2, int nm2, char op) |
(fr1/nm1) {op} (fr2/nm2) = (lastfr/lastnm) |
|
|
int cal(int fr1, int nm1, int fr2, int nm2, char op) |
首先调用int_or_div函数将获取的answer字符串存储为(int_a + fr_a/nm_a)的形式(测试3),随后通过逐字符求解逆波兰表达式计算formula的值(测试4),并与此前的结果进行比较 |
|
|
void initial() |
初始化全局变量 |
|
|
int int_or_div (string element) |
解析数字字符串,并识别整数、真分数、带真分数分别返回1,2,3的值,而在识别失败时返回0(测试5) |
建议通过正则表达式解析,而不必逐字符串识别,导致if-else的高测试成本 |
|
int isnumber(string str) |
将数字字符串转换为数字(测试6) |
完全可以调用atoi()函数,不必手动实现 |
|
vector <string> mid_2_post (string formula) |
将中缀表达式转换为后缀表达式(测试7:优先级设置测试),同时添加"#"符号作为表达式的结尾,方便后续计算的终止(测试8) |
|
|
int newdiv(int range) |
生成非零除数(测试9) |
|
|
char newop() |
生成随机运算符 |
switch-case结构无实现必要,可直接初始化final类型的数组,然后直接通过下标访问 |
|
int priority (string op1, string op2) |
运算符优先级比较 |
switch-case结构无实现必要,直接构建二维数组,且数组值正负表示比较结果 |
|
void reduc(int fra, int nmt, int exe_or_ans) |
完善(lastfr/lastnm)的取值(设置一定参数方便后续修改),如分母为0(测试10),分母为负值(测试11),对非最简分数的化简(测试12);同时通过exe_or_ans的参数实现取值的更改(测试13) |
switch-case结构略有些滥用,导致代码可读性略差,且case内部分代码重复冗杂; |
|
void newformula(int num, int range) |
创建表达式,形如{Number}{Op}{Number}{Op}…,并在除数为0时生成新除数,由于同时的括号生成保证了运算符必定从左到右运算,因此不必考虑A/(B-B)的生成(测试14) |
查重的检查并未出现在程序中,因此,这里程序的正确性存在一定的疑问 |
|
vector <string> split(string str, string spl) |
以spl为“分割符”将目标字符串str分割,存储于vertor<string>中返回 |
完全可以调用strtok()函数实现所需功能 |
|
int main() |
对读取输入并通过if-else结构解析,同时调用此前定义的函数实现表达式生成和判断功能 |
存在部分笔误,具体情况将进一步详细说明;功能略有欠缺 |
*关于具体的测试和代码复审将在0x020c进行进一步的详解
0x020c:General层次代码复审
![]() [N] Does the code work? Does it perform its intended function, the logic is correct etc
[N] Does the code work? Does it perform its intended function, the logic is correct etc
首先,从功能实现的角度,存在五方面的问题
ü “使用 -r 参数控制题目中数值(自然数、真分数和真分数分母)的范围,该参数可以设置为1或其他自然数。该参数必须给定,否则程序报错并给出帮助信息“,首先,程序在功能上允许参数残缺,即MyApp.exe –r 10或MyApp.exe –n 10均能正确生成,与需求不符,但这里很可能是个人对需求有着不同层次的理解,而且更改非常简单,只需删除”case 3“的代码块,因此,代码工作可以判定为”正常“,若修改,则只需对main()函数的中的switch-case结构进行删减即可
ü “程序一次运行生成的题目不能重复“,功能上未进行查重的检测工作,导致会生成重复表达式,与功能需求相违背,这里补充说明一处笔误:
if (args[1] == "-n") {
} else if (args[1] == "r") { /*should be -r*/
}
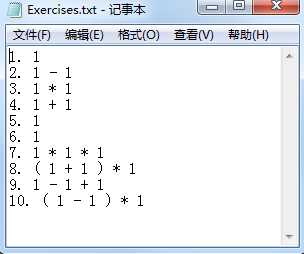
图 1 :输入”Arithmetic1.exe –n 10 –r 2”时重复表达式的输出
ü “参数输入时可以交换-r和-n的输入顺序,而程序能保持正常运行“,而程序在交换-r和-n顺序后无法正常运行

图 2 :输入顺序为"-R -N"时判定为无效输入

图 3 :输入顺序为"-N -R"时判定为正常输入
ü “生成的题目中计算过程不能产生负数“,而显然在如下样例中”Arithmetic1.exe –n 10 –r 10“中,出现了负数,但在最终运算上结果正确,因此表达式支持负数运算是功能扩展,但生成题目与需求不符
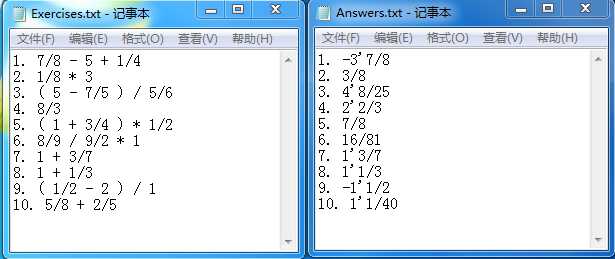
图 4 :输入”Arithmetic1.exe –n 10 –r 10”时负数的出现
ü 在main()函数中可以发现,程序将number限定在[1,9999]区间,将range限定在[1,100]区间,因此对于range参数和number参数在极大和极小情况的输入下程序会打印错误信息:“Invalid exercise number“或”Invalid range number“等提示信息,而对于”2.3“”$TEAMORL^”等错误输入也能准确判定,因此,程序的鲁棒性符合要求
ü 程序的运算符与需求不符,应输入输出Unicode编码为’\u00D7’和’\u00F7’的字符,而将其替换为’*’’/’运算符,因此,在执行”Arithmetic1.exe –e exercises.txt –a answer.txt”会返回错误信息(exercises.txt文件中符号为’\u00D7’时)
![]() [N+] Is all the code easily understood?
[N+] Is all the code easily understood?
虽然程序本身嵌套了大量switch-case结构和if-else结构导致代码本身冗杂,但由于各部分函数的命名比较清晰,所以能较快分辨各函数功能,并最终推测和验证出各函数的功能,但这里摘取一部分代码片段:
case ‘+‘:
case ‘-‘:
switch (c2) {
case ‘+‘: return 2;//highter
case ‘-‘:return 2;
case ‘*‘: return 0;//lower
case ‘/‘: return 0;
case ‘(‘: return 0;
case ‘)‘: return 2;
case ‘#‘: return 2;
default: return -1;//cannot be compared
}
这里完全可以构建一个二维数组来实现如下图的比较功能,但函数名int priority (string op1, string op2)可以较为清晰理解出这是运算符的优先级的比较函数,因此,如果删除类似的switch结构,重构类似上图的冗长代码,封装可能的功能模块,会使得程序的可读性进一步增强
![]() [Y] Does it conform to your agreed coding conventions? These will usually cover location of braces, variable and function names, line length, indentations, formatting, and comments
[Y] Does it conform to your agreed coding conventions? These will usually cover location of braces, variable and function names, line length, indentations, formatting, and comments
程序本身的代码风格相对较好,整体使用TAB缩进,函数名命名和程序内变量命名符合一定规律,但仍有一定的“二义性“,建议使用匈牙利命名法方便阅读,同时全局变量前加入”global_“标识符作为提示可能会使得程序的代码风格有着进一步的提升
![]() [Y] Is there any redundant or duplicate code?
[Y] Is there any redundant or duplicate code?
程序本身存在冗杂和重复的代码片段,
int number = isnumber(args[2]);
if (number <= 0 || number > 9999) {
cout << "Invalid exercise number." << endl;
}
int range = isnumber(args[4]);
if (range <= 0 || range > 100) {
cout << "Invalid range number." << endl;
}
在输入数据的特判中,此代码段重复出现至少4次,强烈建议将封装为void InputJudgement(string range, string number)函数统一进行,同时,程序主体的代码段同样出现类似问你,也可封装为void ProgramRun()函数使得main函数内不至于存在大量大量的if-else结构快,且长达120行
![]() [Y] Is the code as modular as possible?
[Y] Is the code as modular as possible?
除去刚才提及的“redundant or duplicate code“外,程序本身的模块化程序较好,首先声明,这里所说的”模块化“是指程序各部分的功能划分清晰而很少存在交叉重复的功能;但程序本身通过全局变量的反复初始化实现答案的计算和存储,而缺少确定的数据结构来存储分数,使得程序本身的扩展性大大降低,而单文件的方式还是有欠考虑,需要重构,可以参考如下的数据结构
typedef struct _factor{
long denominator;
long numerator;
}factor;
![]() [N] Is there any commented out code?
[N] Is there any commented out code?
不存在与调试相关的代码,但个人倾向于保留调试相关代码并做出如下结构的定义,这在后期的输出检查中将极其方便地观察到各部分的运行状况
#define DEBUG 0
if (DEBUG) {
}
![]() [Y] Do loops have a set length and correct termination conditions?
[Y] Do loops have a set length and correct termination conditions?
循环设置的长度和条件都能够吻合,且符合程序本身的逻辑
![]() [Y] Can any of the code be replaced with library functions?
[Y] Can any of the code be replaced with library functions?
ü int int_or_div (string element),函数解析数字字符串,并识别整数、真分数、带真分数分别返回1,2,3的值,而在识别失败时返回0,但由于函数本身实现时是逐字符串读入,嵌套了大量的if-else结构导致测试成本较高,且本身效率并不高,建议调用#include<boost/regex.hpp> ,即使用C++的Boost库,从而精简代码,清晰功能
ü vector <string> split(string str, string spl),函数以spl为“分割符”将目标字符串str分割,存储于vertor<string>中返回,完全可以调用strtok()函数实现所需功能{char *strtok(char s[], const char *delim)}
ü int isnumber(string str),将数字字符串转换为数字,完全可以调用atoi()函数,不必手动实现
ü void reduc(int fra, int nmt, int exe_or_ans)中存在分子分母的化简功能,采用了“for (int i = 2; fra >= i; ++i) “的暴力求解方法,这里建议修改成标准的辗转相除法这种O(log)级的函数,模板如下图:
void gcd (int m, int n)
{
if (m == 0 || n == 0)
return (m ? m : n);
else
gcd(m % n, n % m);
}
![]() [Y] Can any logging or debugging code be removed?
[Y] Can any logging or debugging code be removed?
可以
0x0210:Security\Documentation\Test层次代码复审
![]() [Y] Are all data inputs checked (for the correct type, length, format, and range) and encoded?
[Y] Are all data inputs checked (for the correct type, length, format, and range) and encoded?
此次所有的输入检查都进行了很好的检查,因为所有的限制条件都通过逐字符的方式进行检查,因此输入的判断上处理得非常全面,具体的特判说明详见0x0208~0x020c的说明
![]() [N] Where third-party utilities are used, are returning errors being caught?
[N] Where third-party utilities are used, are returning errors being caught?
未使用第三方库,而程序中并未主动通过异常机制处理,而是通过参数的错误直接返回并终止程序,因此,检查相对较为完善,鲁棒性较强
![]() [Y] Are invalid parameter values handled?
[Y] Are invalid parameter values handled?
![]() [Y] Do comments exist and describe the intent of the code?
[Y] Do comments exist and describe the intent of the code?
提供了精炼的README,说明在输入上经过了慎重的考虑,经过验证与文档吻合,但部分功能仍偏离需求
![]() [N] Are all functions commented?
[N] Are all functions commented?
并没有有启发性的注释,总注释篇幅不超过10行,因此程序的理解上相对较差,但由于函数命名清晰因此导致程序可读性不差
![]() [N] Is any unusual behavior or edge-case handling described?
[N] Is any unusual behavior or edge-case handling described?
仅在代码中体现,注释中并没有进一步描述
![]() [N] Are data structures and units of measurement explained?
[N] Are data structures and units of measurement explained?
无,但各函数的功能划分清晰
![]() [N] Is there any incomplete code? If so, should it be removed or flagged with a suitable marker like ‘TODO’?
[N] Is there any incomplete code? If so, should it be removed or flagged with a suitable marker like ‘TODO’?
无,但部分可以用库函数处理的地方需要重构完善
![]() [Y] Is the code testable? i.e. don’t add too many or hide dependencies, unable to initialize objects, test frameworks can use methods etc.
[Y] Is the code testable? i.e. don’t add too many or hide dependencies, unable to initialize objects, test frameworks can use methods etc.
函数功能本身测试较为容易,具体的功能测试也陈列在0x0208的表格中,整体思路较为清晰
![]() [Y-] Do tests exist and are they comprehensive? i.e. has at least your agreed on code coverage.
[Y-] Do tests exist and are they comprehensive? i.e. has at least your agreed on code coverage.
从README的文档中可以看出,进行了整体输入输出的测试,但具体的单元测试并没有发现
![]() [N] Do unit tests actually test that the code is performing the intended functionality?
[N] Do unit tests actually test that the code is performing the intended functionality?
![]() [N] Are arrays checked for ‘out-of-bound’ errors?
[N] Are arrays checked for ‘out-of-bound’ errors?
在数组使用前,一定获取其本身的长度来进行限制,因此,可以在一定程度上避免OutOfBound的越界错误
0x03 :结对编程代码选取
考虑到编程语言的熟练程度,和模块化的程序,因此,最终编程决定放弃C++语言编写的此程序,而将它其中的一些想法提炼出来用以重构,而选取面向对象的C#编程语言实现结对编程项目;从此次同伴的代码复审结果分析,编程伙伴的异常状况的讨论非常全面,在构造输入时几乎特判了全部异常情况,在测试方面非常适合,因此最终在讨论整体的框架后,采取开发—测试的最基础的结对编程方式,由我完成基本模块的编写后,并完成一定的单元测试后,采用黑盒、白盒测试叠加的方式进行测试,同时,在后期XML文件的读入和参数设定上由他设计,预留一部分接口来保证程序正确性。
标签:
原文地址:http://www.cnblogs.com/panacea/p/4850385.html