标签:
1.大数据对分布式存储的需求
2.大规模分布式存储系统的挑战
大规模分布式存储中小概率事件变为常态,如何高效的处理这些小概率事件是分布式系统工程中的巨大挑战。
3.典型的分布式存储系统
HDFS:http://www.cnblogs.com/wxquare/p/4846438.html
ceph:http://docs.ceph.com/docs/v0.80.5/
4.分布式系统重要功能设计要点剖析
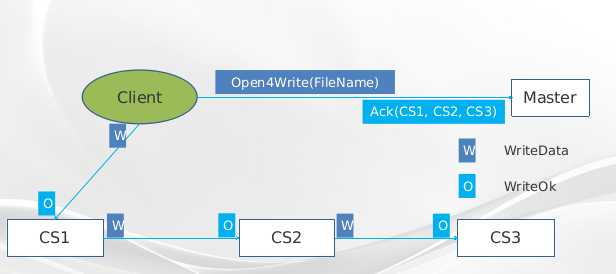
第一步client进程在Master上打开文件写,在请求中传输文件名作为参数,在返回结果中会包含数据写入位置信息;第?步,client端以链式传输的方式将数据写入到多个CS中,顾名思义,数据会在一个传输链条上被传递。首先client将数据传输给CS1,CS1将数据传输给CS2,以此类推,直到最后一个CS收到数据,并返回给前一个链条节点CS,最终数据写入成功的返回传递给client端,表明数据已经写入成功,这样就完成了一次数据写入操作。从写入流程上来看,这写入过程中,每个数据经过的结点都只消耗了一份网络带宽,可以充分利用网络资源;对于有大量数据写入的应用,例如数据导入作业可以达到更高的流量。但从数据写入的返回消息上来看,返回链路相对较长,会给数据写入的latency有较大影响。
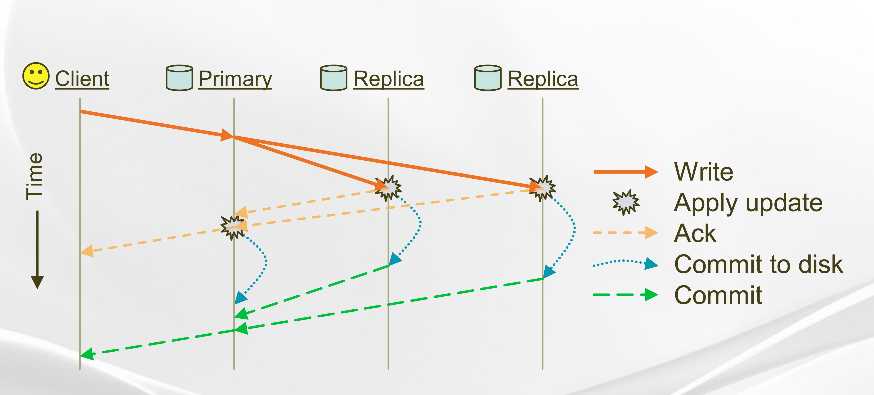
链式写入模式比较适合于数据流量大,但是不注重latency的业务;上图所示的主从模式,比较适合于数据写入频繁要求低延迟的业务。 在此图中省略了文件打开流程的描述,并且数据接收的对应的CS会分成两种,一种为Primary,作为写操作的协调者和接收者,另一种Replica只作为数据的接收者。client数据会首先发送给Primary,Primary将数据接收并转发给另外两台Replica,并等待所有的拷贝都已经合并入内存cache后,由Primary 返回client一个确认消息,此时数据并没有确认写入成功;等所有数据从内存中刷入到物理磁盘后,Replica将刷入磁盘成功的消息发送给Primary,并且Primary也写入成功后将最终数据写入成功的确认消息返回给client。 从上面的写入过程分析,Primary的网络流量是两份数据流量,在极限情况下也只能利用网络流量的一半,所以若果是数据导入的大流量业务不适合。单从数据写入成功的确认过程来看,写入3个副本的情况下只需要两跳即可到达Client,这样网络延迟相对减小,对应写入的latency降低。
2. IO QOS (服务质量)
问题:当多个用户访问存储系统时如何保证优先级和公平性
阿里盘古文件系统中采用的方案:
3.数据正确性:checkSum
在集群中网络、内存、磁盘和软件都有可能导致数据错误,那么在分布式存储系统中如何保证海量数据中没有任何数据错误呢? 数据应该给全程保护,否则任何一个环节出现问题导致数据错误未被检查到,都可能会导致数据出错。被保护的数据至少应该具有数据、数据长度和CRC校验值这样的三元组,而且在任何后续的处理中,都应该先对数据进行处理后,再校验这个3元组的一致性,来保证刚被处理过的数据是正确的。
4.数据可靠性(Replication)
当机器/磁盘出现异常,应通过其它副本快速恢复,充分利用多台机器的复制带宽,但是实际中,应考虑复制的优先级以及复制的流量控制。
5.节点的负载均衡(Rebalance)
当有新的机器/磁盘上线时,迁移数据保证负载均衡。充分利用多台机器的复制带宽,同上,实际中,也需要考虑控制因为负载均衡而导致复制优先级和流量控制。
6.垃圾回收(Garbage collection)
垃圾回收在分布式系统中就好像我们平时对屋子的整理过程,将无用的扔掉给有用物品留下足够的空间.
7.纠删码 (Erasure coding)
纠删码能降低系统的存储代价,但是增加了计算和恢复的代价。
8.元数据的高可用性和可扩展性
通常分布式存储中meta管理节点不多,但是数据读取过程都依赖meta节点,因此元数据管理需要做到高可用性非常重要。
通常的做法是可以将这些节点做成多个备份,保证在一个备份出现问题的时候,仍然可以提供服务。但是多个备份间需要维护数据一致性,防止服务切换造成的数据不一致或者丢失。
高可用性方案:
可扩展性方案:
9.混合存储
混合存储原因是要根据不同存储介质合理使用,提高存储系统性能的同时又不会太大的增大成本。例如HDFS中可以将一个副本放在SSD中,其他副本放在此盘上,Heterogeneous Storages in HDFS,http://hortonworks.com/blog/heterogeneous-storages-hdfs/;阿里的盘古文件系统中,后台程序定期将SSD上记录的多次随机写合并成一次批量写,将数据写入到HDD的chunk replica文件中,这样能在一定程度上降低写的延迟;
RAMCloud内存存RAMCloud,https://ramcloud.atlassian.net/wiki/display/RAM/RAMCloud
RAMCloud内存存储方案同盘古的混合存储方案比较接近,最明显的不同点是将SSD换成了内存存储。 当数据写入是,所以数据均写入到内存,为了高效利用内存,采用了连续记录日志的方式将数据存放在内存中。同时将数据按照数据所属应用进行划分,分别建立索引,方便对数据进行随机访问。由于内存存储的易失性,所以需要将内存中的数据以异步方式保存到磁盘中。 这种实现策略非常适用于分布式的cache服务,可以充分利用内存的高带宽和低延迟,但是在分布式环境中需要同时配备高速网络,否则其威力得不到发挥。
从上面的例子可以看到,混合存储技术基本是利用高性能小容量高成本的介质来作为低性能大容量低成本的cache来满足业务需求。
|
磁盘 |
SSD |
内存 |
|
|
容量 |
1–4 TB |
400–800 GB |
24–128 GB |
|
延时 |
10 ms |
50–75 us |
100 ns |
|
吞吐 |
100–200 MB/s |
400 MB/s |
20 GB/s |
|
成本 |
0.06 $/GB |
1 $/GB |
10 $/GB |
标签:
原文地址:http://www.cnblogs.com/wxquare/p/4850167.html