标签:
我们现在从需求中提取关键词来逐步分析问题。
首先是“种子节点”。它就是一个或多个在爬虫程序运行前手动给出的URL(网址),爬虫正是下载并解析这些种子URL指向的页面,从中提取出新的URL,然后重复以上的工作,直到达到设定的条件才停止。
然后是“特定的策略”。这里所说的策略就是以怎样的顺序去请求这些URL。如下图是一个简单的页面指向示意图(实际情况远比这个复杂),页面A是种子节点,当然最先请求。但是剩下的页面该以何种顺序请求呢?我们可以采用深度优先遍历策略,通俗讲就是一条路走到底,走完一条路才再走另一条路,在下图中就是按A,B,C,F,D,G,E,H的顺序访问。我们也可以采用宽度优先遍历策略,就是按深度顺序去遍历,在下图中就是按A,B,C,D,E,F,G,H的顺序请求各页面。还有许多其他的遍历策略,如Google经典的PageRank策略,OPIC策略策略,大站优先策略等,这里不一一介绍了。我们还需要注意的一个问题是,很有可能某个页面被多个页面同时指向,这样我们可能重复请求某一页面,因此我们还必须过滤掉已经请求过的页面。 
最后是“设定的条件”,爬虫程序终止的条件可以根据实际情况灵活设置,比如设定爬取时间,爬取数量,爬行深度等。
到此,我们分析完了爬虫如何开始,怎么运作,如何结束(当然,要实现一个强大,完备的爬虫要考虑的远比这些复杂,这里只是入门分析),下面给出整个运作的流程图:

根据以上的分析,我们需要用一种数据结构来保存初始的种子URL和解析下载的页面得到的URL,并且我们希望先解析出的URL先执行请求,因此我们用队列来储存URL。因为我们要频繁的添加,取出URL,因此我们采用链式存储。下载的页面解析后直接原封不动的保存到磁盘。
所谓网络爬虫,我们当然要访问网络,我们这里使用jsoup,它对http请求和html解析都做了良好的封装,使用起来十分方便。根据数据结构分析,我们用LinkedList实现队列,用来保存未访问的URL,用HashSet来保存访问过的URL(因为我们要大量的判断该URL是否在该集合内,而HashSet用元素的Hash值作为“索引”,查找速度很快)。
以上分析,我们一共要实现2个类:
① JsoupDownloader,该类是对Jsoup做一个简单的封装,方便调用。暴露出以下几个方法:
—public Document downloadPage(String url);根据url下载页面
—public Set<String> parsePage(Document doc, String regex);从Document中解析出匹配regex的url。
—public void savePage(Document doc, String saveDir, String saveName, String regex);保存匹配regex的url对应的Document到指定路径。
② UrlQueue,该类用来保存和获取URL。暴露出以下几个方法:
—public void enQueue(String url);添加url。
—public String deQueue();取出url。
—public int getVisitedCount();获取访问过的url的数量;
package com.hjzgg.spider; import java.io.File; import java.io.FileNotFoundException; import java.io.IOException; import java.io.PrintWriter; import java.net.SocketTimeoutException; import java.util.HashSet; import java.util.Map; import java.util.Set; import org.jsoup.Connection; import org.jsoup.Connection.Response; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class JsoupDownloader { public static final String DEFAULT_SAVE_DIR = "c:/download/"; private static JsoupDownloader downloader; private JsoupDownloader() { } public static JsoupDownloader getInstance() { if (downloader == null) { synchronized (JsoupDownloader.class) { if (downloader == null) { downloader = new JsoupDownloader(); } } } return downloader; } public Document downloadPage(String url) { try { System.out.println("正在下载" + url); Connection connection = Jsoup.connect(url); connection.timeout(1000); connection.followRedirects(false);//默认是true,也就是连接遵循重定向!设置为false,对重定向的地址进行筛选 Response response = connection.execute(); Map<String, String> headers = response.headers(); System.out.println(response.statusCode() + " " + response.statusMessage()); if(response.statusCode()==301 || response.statusCode()==302){////重定向地址,位于信息头header中 Main.urlQueue.enQueue(headers.get("Location")); } else if(response.statusCode() == 404){ //或者一些其他的错误信息,直接将改地址丢弃 return null; } for(String name : headers.keySet())//在这里可以查看http的响应信息头信息 System.out.println(name + " : " + headers.get(name)); return connection.get(); } catch(SocketTimeoutException e){//对于连接超时的url我们可以重新将其放入未访问url队列中 Main.urlQueue.enQueueUrlTimeOut(url); }catch (IOException e) { e.printStackTrace(); } return null; } public Set<String> parsePage(Document doc, String regex) { Set<String> urlSet = new HashSet<String>(); if (doc != null) { Elements elements = doc.select("a[href]"); for (Element element : elements) { String url = element.attr("href"); if (url.length() > 6 && !urlSet.contains(url)) { if (regex != null && !url.matches(regex)) { continue; } if(!url.contains("http")) url = doc.baseUri()+url; urlSet.add(url); } } } return urlSet; } public void savePage(Document doc, String saveDir, String saveName, String regex) { if (doc == null) { return; } if (regex != null && doc.baseUri() != null && !doc.baseUri().matches(regex)) { return; } saveDir = saveDir == null ? DEFAULT_SAVE_DIR : saveDir; saveName = saveName == null ? doc.title().trim().replaceAll("[\\?/:\\*|<>\" ]", "_") + System.nanoTime() + ".html" : saveName; File file = new File(saveDir + "/" + saveName); File dir = file.getParentFile(); if (!dir.exists()) { dir.mkdirs(); } PrintWriter printWriter; try { printWriter = new PrintWriter(file); printWriter.write(doc.toString()); printWriter.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } } }
package com.hjzgg.spider; import java.util.Arrays; import java.util.Collection; import java.util.HashSet; import java.util.LinkedList; import java.util.NoSuchElementException; import java.util.Set; public class UrlQueue { private Set<String> visitedSet;// 用来存放已经访问过多url private LinkedList<String> unvisitedList;// 用来存放未访问过多url public UrlQueue(String[] seeds) { visitedSet = new HashSet<String>(); unvisitedList = new LinkedList<String>(); unvisitedList.addAll(Arrays.asList(seeds)); } /** * 添加url * * @param url */ public void enQueue(String url) { if (url != null && !visitedSet.contains(url)) { unvisitedList.addLast(url); } } /** * 添加访问超时的url * * @param url */ public void enQueueUrlTimeOut(String url) { if (url != null) { visitedSet.remove(url); unvisitedList.addLast(url); } } /** * 添加url * * @param urls */ public void enQueue(Collection<String> urls) { for (String url : urls) { enQueue(url); } } /** * 取出url * * @return */ public String deQueue() { try { String url = unvisitedList.removeFirst(); while(visitedSet.contains(url)) { url = unvisitedList.removeFirst(); } visitedSet.add(url); return url; } catch (NoSuchElementException e) { System.err.println("URL取光了"); } return null; } /** * 得到已经请求过的url的数目 * * @return */ public int getVisitedCount() { return visitedSet.size(); } }
package com.hjzgg.spider; import java.util.Set; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class Main { static UrlQueue urlQueue = new UrlQueue(new String[] { "http://192.168.1.201:8080/HZML/" }); public static void main(String[] args) { JsoupDownloader downloader = JsoupDownloader.getInstance(); long start = System.currentTimeMillis(); while (urlQueue.getVisitedCount() < 1000) { String url = urlQueue.deQueue(); if (url == null) { break; } Document doc = downloader.downloadPage(url); if (doc == null) { continue; } Set<String> urlSet = downloader.parsePage(doc, "userRequest\\?userRequest=showNoParticipateTask&taskid=\\d{1,2}|http://www.cnblogs.com/hujunzheng/(p|default|archive/\\d{4}/\\d{2}/\\d{2}/).*"); urlQueue.enQueue(urlSet); downloader.savePage(doc, "I:\\博客园-hjzgg", null, "userRequest\\?userRequest=showNoParticipateTask&taskid=\\d{1,2}|http://www.cnblogs.com/hujunzheng/(p|default|archive/\\d{4}/\\d{2}/\\d{2}/).*"); System.out.println("已请求" + urlQueue.getVisitedCount() + "个页面"); } long end = System.currentTimeMillis(); System.out.println(">>>>>>>>>>抓取完成,共抓取" + urlQueue.getVisitedCount() + "到个页面,用时" + ((end - start) / 1000) + "s<<<<<<<<<<<<"); } }
注:userRequest\\?userRequest=showNoParticipateTask&taskid=\\d{1,2} 是本地的网站中网页里的地址,当然种子地址也是本地网站!
在请求这个地址后会产生地址重定向,到博客园地址http://www.cnblogs.com/hujunzheng/,并完成相应的下载!
1.这是请求超时的情况
2.正常访问或者重定向访问
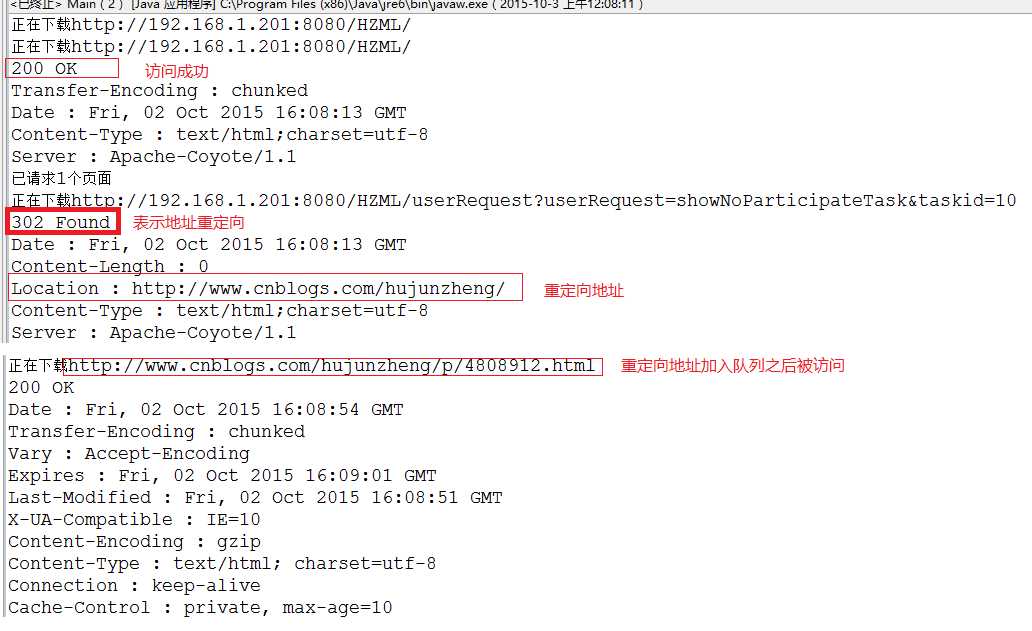
标签:
原文地址:http://www.cnblogs.com/hujunzheng/p/4852948.html