标签:
首先,上图(*+﹏+*)~@

1.如何看待结对编程
结对编程优点:
1.两个人能够相互支持,相互监督,客服编程过程中可能出现的烦躁的情况0_0。
2.在开发功能的同时,伴随了UnitTest的进行,可以提高代码的正确性和稳定性。
3.不想坑队友,工作时会比较认真b( ̄▽ ̄)d。
4.两个人写的模块会相互调用,开发过程中会不断的对同伴的代码进行复审,提高了程序运行的正确性和稳定性。
5.分工合作,每人负责自己的部分,效率高。
结对编程缺点:
1.分工容易出现失衡,能者多劳可能变成不能者不劳。
2.“领航员”容易游离于整个开发过程,导致开发进度缓慢或者开发过程混乱
3.代码风格迥异的两人可能互相看不懂代码,拖慢开发进程。
4.项目中的设计问题,一旦出现意见分歧,比较难解决(特别是对于两个水平经验都不丰富的小伙伴来说。。。)。
我的同伴的优点:
1.人很nice,很容易沟通,待人亲切随和。
2.代码风格比较好,能比较快的读懂他的代码,这点很欣慰~(因为我自己读代码能力不够强悍。。。)
3.测试能力不错,测出来好多Bug,估计是OO课练出来的。。
我的同伴的缺点:
1.编程能力不是很强,对数据结构以及C#特性的理解和运用仍有不足之处
2.调试能力欠缺,发现了Bug后定位以及修补的时间较长
2.Information Hiding、interface design、loose coupling
Information Hiding:
信息隐藏原则,是面向对象程序设计的基础。信息隐藏的好处是可以保护数据随意被修改,只有拥有权限才可以访问并修改程序内的数据。这样程序可以相对稳定执行,避免出现数据出错导致的程序崩溃。将程序需要提供的功能模块化,每个模块完成各自的功能,每个模块封装起自己的数据,只有自己才能访问并修改,即所有变量采用private型。这便保证了信息隐藏。模块之间的交互通过接口完成,也就是只能通过访问模块内的public方法,才可以在不访问模块内任何数据的情况下,能且仅能获取该模块的功能(即返回值)。
这一点原则已经被OO训练的相当的熟悉了,使用起来也很熟练。。。。从后面的UML图中可以看出,我的所有属性全是private(除了一个随机数生成器,以为全局都要用到,我设为public static)╭(╯_╰)╭
interface design:
接口设计原则,可以令面向对象的程序设计封装起来更加精简。模块化的程序中,每个模块(即每个类)只完成一个功能,然而有些时候我们需要许多“小”功能共同作用,完成一个大“功能”。这时候我们需要将所需的所有模块实例化,再取其中的方法,连续调用,过于冗杂。这个时候我们定义一个接口,将所需的方法封在里面,当需要完成“大功能”的时候,我们只需调用这个接口就可以了。当然,应该尽量减少通用接口,具体问题具体分析,多提供特定的接口给用户才更加人性化。
关于这一点。。。。我表示这次的项目没有采用,,,,因为我觉得用不到额..@_@|||||..并没有拥有同样行为或者需要同样接口的类型。
loose coupling:
松耦合高内聚。即模块之间尽可能独立,模块内部数据联系紧密。要想做到这点,必须在开始写程序之前,将功能细化(模块化),把用户要求实现的功能分析清楚,尽可能独立出各种“小”功能。使可以完成这些“小“功能的模块,只要求尽量少的输入,即可返回相应输出,并且不依赖于其它模块。
这一原则在实现的时候,我们组比较好的遵循了。模块与模块之间所传递的数据,仅是少量必须数据或者是由模块已经组织运算好的数据结果。尽量把小功能模块化,模块输入参数化,这样写出来的程序维护性较好,而且比较适合二次开发和团队开发。
比如在我们的程序中,Generator类把从界面获取的用户输入的setting数据传给Problem类的构造函数,然后Problem的构造又把与构造操作数有关的setting数据传给Fraction的构造,从而实现松耦合。
3. Design by Contract, Code Contract
契约关系这个点。。。想起来就心累啊,上个学期的OO课,写了好多代码契约、代码规格。考试还手写证明。。。不说了,都是泪啊~~~
回到正题,我个人感觉有2个优势:
第一, 明确了用户和开发者的义务和权利(即用户提供正确输入或输入状态即可获得程序运行结果,开发者收到正确输入并处于正确等待运行状态便提供正确运行结果)后,开发者在开发过程中只需要考虑正确的输入即可,一切不正确的输入(不满足前置条件),都将报错。精简了程序逻辑,缩短了开发周期。将检查与正常运行分开无疑是最好的选择。
第二, 混在整段程序的冗杂判错代码段去除后, 清晰的程序逻辑框架有助于开发者Debug,一方面缩短开发周期,更重要的是有效减少了程序运行的安全隐患。复杂的判错代码很容导致原本代码的正常功能在绕着判错的过程中失效了。同时这样降低了开发者Debug的难度和时间开销,自然开发效率就高了。
缺点:
对用户要求较高,虽然可以单独提供判错模块对用户的输入及输入状态进行判断,但是时间成本不一定比原本低。
我感觉实际上把契约思想加到这次作业中还是能取得比较好的效果的,比如这次作业中有一个模块的前置条件比较苛刻,即计算用户在界面输入的题目的模块。该模块的前置条件是,用户输入的计算式符合格式规则。程序中只需要加入一个判错模块,对不符合要求的输入一律报错即可。这样的设计就符合了上述原则,并且能够很清晰的书写代码逻辑。
4.UnitTest
UnitTest代码示例图:
测试样例代码覆盖总览表:
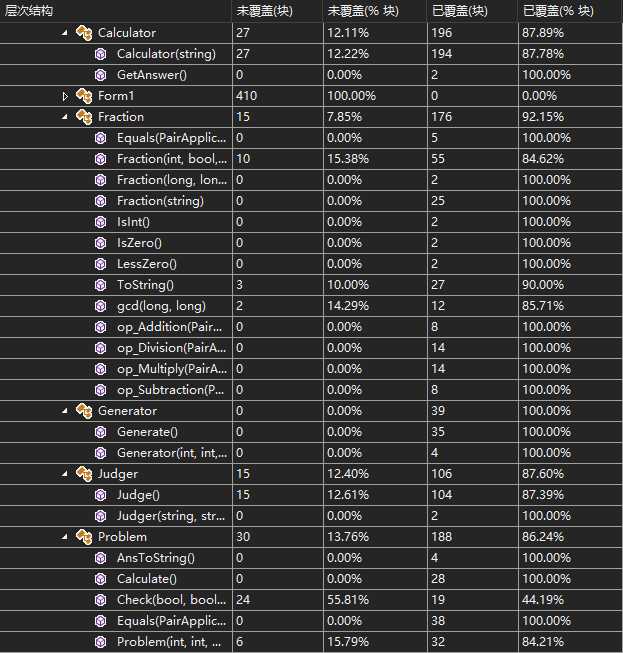
可以看出,只有表中Problem.Check()这个方法的覆盖率比较低,测试结果出来后我们检查了一下该方法的代码,发现其实是因为在设计方法逻辑的时候有些数据重复Check的情况存在,所以导致覆盖率低下。
自己编写的类和方法的覆盖率基本比较高,然而From1窗体的代码太多,导致整体覆盖率并不高= =!
5.UML图
首先发现了VS2012中自带的类图。。。点开来一看,发现木有类之间的关系,于是乎,我在此基础之上进行了P图~~~效果如下:
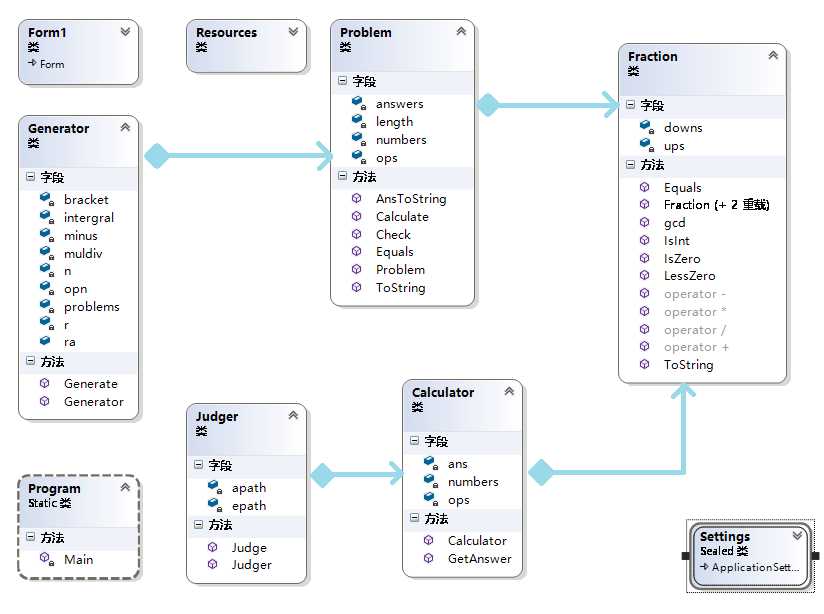
6.算法
算法实现其实和我之前的个人项目是差不多的,但是这次由于换成了C#语言来写,所以我的程序整体思想采用了面向对象的思想。
首先界面窗体使用了三个标签页来对接不同的功能模块,界面示例如下:
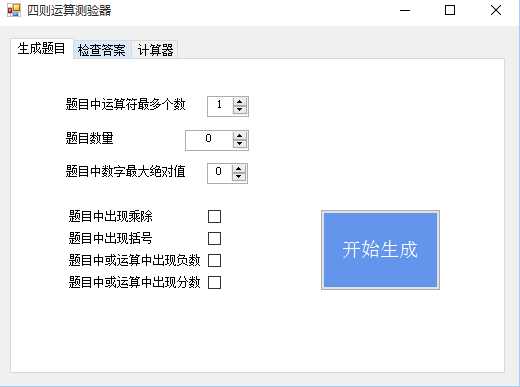
TabControl作为切换页Checkbox作为是否选中某选项NumericUpDown作为诸如值域以及其他的限制Button作为启动的按键和计算器的界面TextBox作为一些输出参数的显示和输入文件路径然后,Generator负责实现根据设置生成题目。内部的core()的设计思路与个人项目相仿,但是因为有了不同的设置参数,所以在生成过程中,我采取的是以同一种大思路的前提下来对不同的情况进行优化设计的方案。
Judger和Calculator这两个模块的核心是Calculator模块,即对输入的字符串形式的题目进行计算。设计思路是分离判断格式模块和真正的计算单元,先判断是否合法,在进行分析计算,实现起来难度都不大。
所谓的独到之处也就只有生成题目的时候,先生成后缀表达式,然后在进行转化这一条。这样做的好处就是能够方便地检查重复性。之前学习了大神们优秀的算法,如树的最小表示法,然而我实现的时候遇到问题太多,考虑到时间故而放弃,可能是因为我对于树结构的操作生疏了。
标签:
原文地址:http://www.cnblogs.com/nightcool/p/4857673.html