标签:
Linear Model Selection and Regularization
此博文是 An Introduction to Statistical Learning with Applications in R 的系列读书笔记,作为本人的一份学习总结,也希望和朋友们进行交流学习。
该书是The Elements of Statistical Learning 的R语言简明版,包含了对算法的简明介绍以及其R实现,最让我感兴趣的是算法的R语言实现。
【转载时请注明来源】:http://www.cnblogs.com/runner-ljt/
Ljt 勿忘初心 无畏未来
作为一个初学者,水平有限,欢迎交流指正。
这一节的内容主要是线性回归的进一步延伸,在一般的最小二乘线性回归中经常遇到的问题是自变量数目较多,高维度的自变量会导致样本数目
相对偏少和自变量间的共线性现象,最终使得回归模型过拟合,预测精度下降以及模型的解释能力的削弱。选择合理的自变量不仅能降低模型的复杂
度,而且能有效防止过拟合问题.
本节内容主要介绍在变量选择上的三种常见方法:
(1)子集选择(subset selection):以模型优劣的判别准则来选择合适的自变量子集,常见的方法有最优子集法和逐步回归法;
(2)收缩法/正则化(shrinkage/regularization):在对所有变量的传统最小二乘回归中加入约束,使得某些回归系数收缩为0,从而达到选择合适
自变量的目的,主要包括岭回归(ridge regression)及lasso回归;
(3)维数缩减(dimension reduction):利用投影得到不相关的自变量组合,主要方法为主成分回归(PCR)和偏最小二乘回归(PLS).
前两种方法在本质上是一样的,都是通过选择全变量的一个合适的子集来达到降维的目的,只不过(1)是将选择和判别分开,每一个子集便是一个
选择,判别是通过相应的判别准则来决定哪一个子集选择是最佳的,而(2)是将选择和判别融为一个过程,在全变量的最小二乘中加入罚约束,在最小
二乘的过程中要考虑到变量的选择问题,最终达到最小二乘和变量选择的一个权衡;(1)和(2)都是在原始变量基础上选择一个合理的子集,而(3)则换
了一种思路,不直接使用原始变量,而是对原始变量进行投影转换为新的变量,既使得变量的维度减少又使新变量间相互独立。
subset selection
最优子集法是将全自变量的所有非空子集都作为一个选择,然后通过判别准则来选择最优的子集,当有p个自变量时便会有2^p 个回归方程需要进
行判别,当p稍微大一些时复杂度就会极高。
逐步回归法是对自变量进行逐个的分析,按照优进差退是原则进行选择,主要的方法包括前进法、后退法及混合法;前进法和后退法主要的区别是
原始模型是空模型还是全模型,由此产生了不同的适用性:当自变量维度较高(自变量个数大于样本量,p>n)时,前进法仍然适用,而由于后退法第
一步就要建立全模型(只有当样本量大于自变量个数时才能建立合理的全模型),所以后退法不再适用;前进法是只进不出,后退法是只出不进,而合
法则是有进也有出,因为新进的变量不能保证已被选择的变量仍然显著,所以混合法最受推崇。
模型选择的判别准则
模型拟合优劣的一般判别准则有残差平方和SSE及复相关系数R等,但是当自变量子集扩大时,残差平方和会减少,复决定系数会增大,这便会导
致自变量选择的越多拟合效果就会越好的假象,所以残差平方和、复相关系数或样本决定系数都不能作为选择自变量的准则。
以下本文从不同角度给出自模型选择的几个常用判别准则:
(1)拟合角度:调整的复决定系数 Ra=1-(n-1)(1-R2)/(n-p-1)越大,对应的回归方程越好;
(2)极大似然估计角度:AIC准则,AIC值越小,对应的回归方程越优;
(3)预测角度:Cp统计量越小,对应的回归模型越优;
(4)试验误差:对样本进行训练样本和试验样本分组,在试验样本上的验证集法或交叉验证的试验误差最小的回归方程最优.
基于 Ra2、AIC、Cp判别准则的模型选择
regsubsets(formula,data,nvmax=8,method=c(‘exhaustive‘,‘backward‘,‘frowand‘,‘seqrep‘))
formula:因变量Y及自变量X的线性回归模型
nvmax:自变量集中含有自变量的最大个数
na.omit(data) 去掉含有NA的样本
plot(x,scale=c(‘r2‘,‘adjr2‘,‘Cp‘,‘bic‘)) -----plot.regsubsets
x:regsubsets类
scale:由于绘图排序的统计量(判别准则)
>
> library(ISLR)
> library(leaps)
> names(Hitters)
[1] "AtBat" "Hits" "HmRun" "Runs" "RBI" "Walks"
[7] "Years" "CAtBat" "CHits" "CHmRun" "CRuns" "CRBI"
[13] "CWalks" "League" "Division" "PutOuts" "Assists" "Errors"
[19] "Salary" "NewLeague"
> dim(Hitters)
[1] 322 20
> #去掉含有NA的样本
> data<-na.omit(Hitters)
> dim(data)
[1] 263 20
> #最优子集法
> regfit.full<-regsubsets(Salary~.,data,nvmax=15)
> summary(regfit.full)
Subset selection object
Call: regsubsets.formula(Salary ~ ., data, nvmax = 15)
19 Variables (and intercept)
Forced in Forced out
AtBat FALSE FALSE
Hits FALSE FALSE
HmRun FALSE FALSE
Runs FALSE FALSE
RBI FALSE FALSE
Walks FALSE FALSE
Years FALSE FALSE
CAtBat FALSE FALSE
CHits FALSE FALSE
CHmRun FALSE FALSE
CRuns FALSE FALSE
CRBI FALSE FALSE
CWalks FALSE FALSE
LeagueN FALSE FALSE
DivisionW FALSE FALSE
PutOuts FALSE FALSE
Assists FALSE FALSE
Errors FALSE FALSE
NewLeagueN FALSE FALSE
1 subsets of each size up to 15
Selection Algorithm: exhaustive
AtBat Hits HmRun Runs RBI Walks Years CAtBat CHits CHmRun CRuns CRBI CWalks LeagueN DivisionW PutOuts Assists Errors NewLeagueN
1 ( 1 ) " " " " " " " " " " " " " " " " " " " " " " "*" " " " " " " " " " " " " " "
2 ( 1 ) " " "*" " " " " " " " " " " " " " " " " " " "*" " " " " " " " " " " " " " "
3 ( 1 ) " " "*" " " " " " " " " " " " " " " " " " " "*" " " " " " " "*" " " " " " "
4 ( 1 ) " " "*" " " " " " " " " " " " " " " " " " " "*" " " " " "*" "*" " " " " " "
5 ( 1 ) "*" "*" " " " " " " " " " " " " " " " " " " "*" " " " " "*" "*" " " " " " "
6 ( 1 ) "*" "*" " " " " " " "*" " " " " " " " " " " "*" " " " " "*" "*" " " " " " "
7 ( 1 ) " " "*" " " " " " " "*" " " "*" "*" "*" " " " " " " " " "*" "*" " " " " " "
8 ( 1 ) "*" "*" " " " " " " "*" " " " " " " "*" "*" " " "*" " " "*" "*" " " " " " "
9 ( 1 ) "*" "*" " " " " " " "*" " " "*" " " " " "*" "*" "*" " " "*" "*" " " " " " "
10 ( 1 ) "*" "*" " " " " " " "*" " " "*" " " " " "*" "*" "*" " " "*" "*" "*" " " " "
11 ( 1 ) "*" "*" " " " " " " "*" " " "*" " " " " "*" "*" "*" "*" "*" "*" "*" " " " "
12 ( 1 ) "*" "*" " " "*" " " "*" " " "*" " " " " "*" "*" "*" "*" "*" "*" "*" " " " "
13 ( 1 ) "*" "*" " " "*" " " "*" " " "*" " " " " "*" "*" "*" "*" "*" "*" "*" "*" " "
14 ( 1 ) "*" "*" "*" "*" " " "*" " " "*" " " " " "*" "*" "*" "*" "*" "*" "*" "*" " "
15 ( 1 ) "*" "*" "*" "*" " " "*" " " "*" "*" " " "*" "*" "*" "*" "*" "*" "*" "*" " "
>
>
> #选取最优自变量集合
> regsumm<-summary(regfit.full)
> names(regsumm)
[1] "which" "rsq" "rss" "adjr2" "cp" "bic" "outmat" "obj"
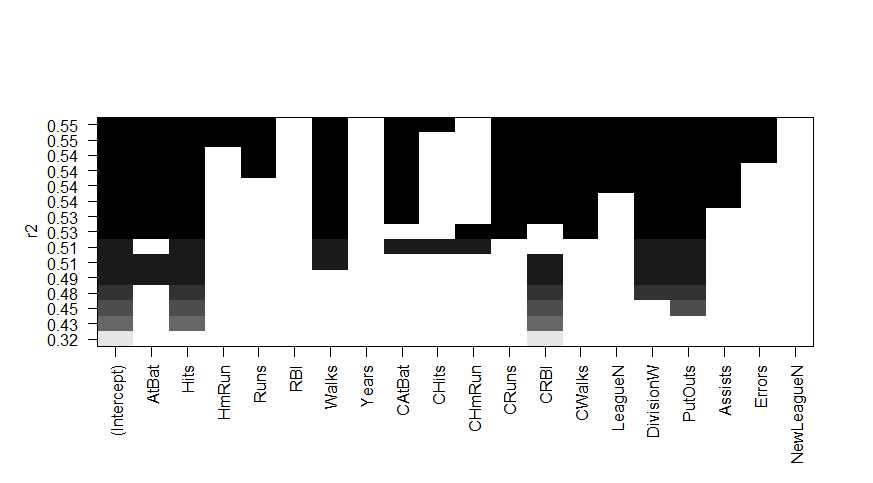
> regsumm$rsq
[1] 0.3214501 0.4252237 0.4514294 0.4754067 0.4908036 0.5087146 0.5141227 0.5285569 0.5346124 0.5404950 0.5426153 0.5436302 0.5444570
[14] 0.5452164 0.5454692
> regsumm$adjr2
[1] 0.3188503 0.4208024 0.4450753 0.4672734 0.4808971 0.4972001 0.5007849 0.5137083 0.5180572 0.5222606 0.5225706 0.5217245 0.5206736
[14] 0.5195431 0.5178661
> regsumm$cp
[1] 104.281319 50.723090 38.693127 27.856220 21.613011 14.023870
[7] 13.128474 7.400719 6.158685 5.009317 5.874113 7.330766
[13] 8.888112 10.481576 12.346193
> which.min(regsumm$cp)
[1] 10
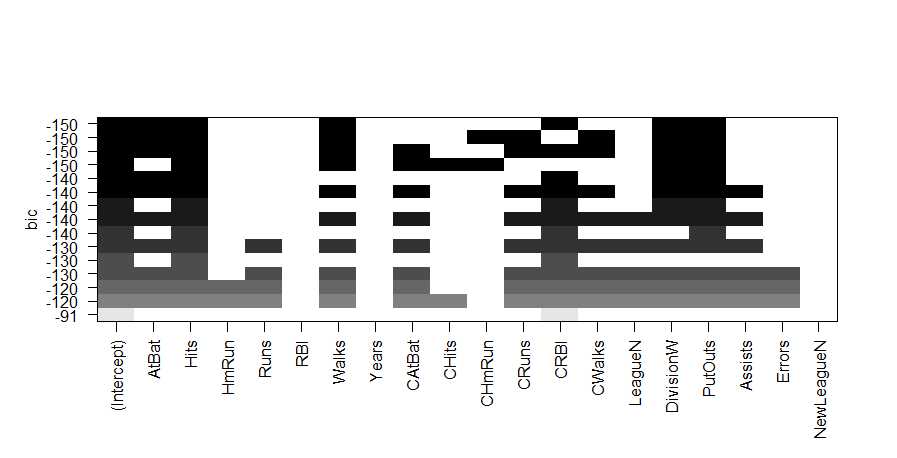
> regsumm$bic
[1] -90.84637 -128.92622 -135.62693 -141.80892 -144.07143 -147.91690 -145.25594 -147.61525 -145.44316 -143.21651 -138.86077
[12] -133.87283 -128.77759 -123.64420 -118.21832
> which.max(regsumm$rsq)
[1] 15
> which.max(regsumm$adjr2)
[1] 11
> which.min(regsumm$bic)
[1] 6
> #图形展示
> plot(regfit.full,scale=‘r2‘)
> plot(regfit.full,scale=‘adjr2‘)
> plot(regfit.full,scale=‘Cp‘)
> plot(regfit.full,scale=‘bic‘)
>
> #最优自变量的回归系数
> coef(regfit.full,6)
(Intercept) AtBat Hits Walks CRBI DivisionW PutOuts
91.5117981 -1.8685892 7.6043976 3.6976468 0.6430169 -122.9515338 0.2643076
>
> #前进法
> regfit.fwd<-regsubsets(Salary~.,data,nvmax=15,method=‘forward‘)
> #后退法
> regfit.fwd<-regsubsets(Salary~.,data,nvmax=15,method=‘backward‘)
>


基于验证集法或交叉验证判别准则的模型选择
Validation Set Approach
首先在训练样本上按照变量选择的方法,得到不同自变量个数所对应的自变量集合,即得到不同的模型;然后在试验样本上计算每个模型对应
的MES,得到MES最小的模型,即得到最优的自变量集合;最后在全体样本上重复变量选择方法,得到对应最优模型的回归系数(对于最优模型的
回归系数必须在全体样本上计算得到)。
> library(ISLR)
> library(leaps)
> Hitters<-na.omit(Hitters)
> set.seed(1)
> train<-sample(c(T,F),nrow(Hitters),rep=T)
> test<-!train
> #在训练样本上进行自变量子集选择
> regfit.best<-regsubsets(Salary~.,data=Hitters[train,],nvmax=19)
> #产生试验样本的X矩阵
> test.mat<-model.matrix(Salary~.,data=Hitters[test,])
> #对于产生的不同模型,计算在试验样本上的MSE
> val.errors<-rep(NA,19)
>
> for(i in 1:19){
+ coefi<-coef(regfit.best,i)
+ pred<-test.mat[,names(coefi)]%*%coefi
+ val.errors[i]<-mean((Hitters$Salary[test]-pred)^2)
+ }
>
> which.min(val.errors)
[1] 10
>
> #得到最优模型后,在全体样本上计算模型回归系数
> regfit.best<-regsubsets(Salary~.,data=Hitters,nvmax=19)
> coef(regfit.best,10)
(Intercept) AtBat Hits Walks CAtBat CRuns CRBI CWalks DivisionW PutOuts Assists
162.5354420 -2.1686501 6.9180175 5.7732246 -0.1300798 1.4082490 0.7743122 -0.8308264 -112.3800575 0.2973726 0.2831680
>
K-Cross Validation
> #10折交叉验证法
> k<-10
> set.seed(2)
> #将样本分为10组
> folds<-sample(1:k,nrow(Hitters),replace=T)
> #产生存储10折交叉验证的MSE
> cv.errors<-matrix(NA,k,19,dimnames=list(NULL,paste(1:19)))
>
> for(i in 1:k){
+ best.fit<-regsubsets(Salary~.,data=Hitters[folds!=i,],nvmax=19)
+ test.mat<-model.matrix(Salary~.,data=Hitters[folds==i,])
+ for(j in 1:19){
+ coefi<-coef(regfit.best,j)
+ pred<-test.mat[,names(coefi)]%*%coefi
+ cv.errors[i,j]<-mean((Hitters$Salary[folds==i]-pred)^2)
+ }
+ }
>
> #计算含有j个自变量的模型的交叉验证的评价MSE
> mean.cv.errors<-apply(cv.errors,2,mean)
> which.min(mean.cv.errors)
14
14
> #在全体样布上计算最优模型的回归系数
> reg.best<-regsubsets(Salary~.,data=Hitters,nvmax=19)
> coef(reg.best,14)
(Intercept) AtBat Hits HmRun Runs Walks CAtBat CRuns CRBI CWalks LeagueN
144.6793182 -2.0883279 7.6436454 2.3406524 -2.3580478 6.1794713 -0.1488074 1.5931621 0.7170767 -0.8565844 44.2352269
DivisionW PutOuts Assists Errors
-112.8079905 0.2876182 0.3677311 -3.1271251
>
ISLR系列:(4.1)模型选择--- Subset Selection
标签:
原文地址:http://www.cnblogs.com/runner-ljt/p/4856476.html