标签:
课程地址:http://ufldl.stanford.edu/tutorial/supervised/FeatureExtractionUsingConvolution/
在之前的练习中,图片比较小,这节课的方法可以应用到更大的图像上。
在sparse autoencoder(后面会讲到)中,一种设计选择是将输入层与隐藏层fully connect,这种方式对图片小的情况下计算量还
可以接受,但对大图片来说变得不可接受。
一种简单的解决方式是隐藏层只连接一部分的输入层,即只对特定的输入产生反应。
自然图像有一种stationary的性质,即图像的某个部分的统计信息和该图像的其他部分是一致的,也就是说,在图像某个部分提取的特征可
以应用到图像的其他部分,并且可以在所有的位置上使用同样的特征(不太理解啊)。
更准确的说,我们可以在一副96*96图像上随机提取一个patch(比如8*8)的特征,我们可以将这个8*8的feature detector应用到这副图像的任何地方,
具体说就是,我们将学习到的8*8feature与大图像作convolve,因而在图像的每个位置上都得到一个不同的feature activation value
为了更好理解,给了一个具体的例子。假设已经学到了特征,来自于一个96*96图像上的一个8*8的patch,更近一步,假设这是由一个有100个隐藏单元的
autoencoder完成的。为了得到convolved features,对于96*96的每个8*8区域(参考课程中的动图)。
正式的说法是,给定一个r*c的大图xlarge,我们首先在一个小的a*b的pathces xsmall(从大图中采样得到)上训练一个sparse autoencoder,使及方程
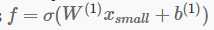 得到k个特征,然后
得到k个特征,然后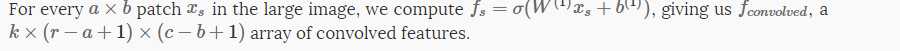
下部分将要讨论如何pool这些特征,来得到更好的用于分类的特征。
标签:
原文地址:http://www.cnblogs.com/573177885qq/p/4858802.html