标签:
随笔说明:由于参加了上海交大组织的飞谷云项目,而且报名第三组:基于Spark的机器学习。于是打算先花时间把Spark的基础学习学习。这次学习的参考书选择的是Spark的官方文档(这个肯定是最权威的)和机械工业的《Spark大数据处理 技术、应用与性能优化》;届时肯定还有项目组提供的学习资料。
Spark是基于内存计算的大数据并行计算框架。它基于内存计算,提高了实时性,保证了高容错性和高可伸缩性,允许用户将它部署在大量廉价硬件之上,形成集群。
Spark之于Hadoop:Spark只是一个计算框架,而hadoop中包含计算框架MapReduce和分布式文件系统HDFS,更加广泛的说,Hadoop还包括在其生态系统上的其他系统,如Hbase,Hive等。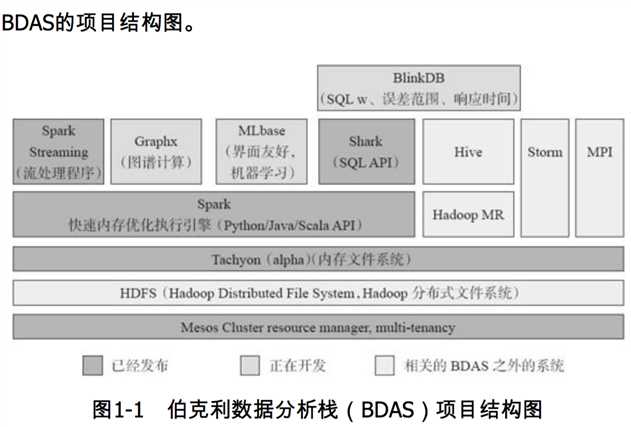
Spark是整个BDAS的核心组件,将分布式数据抽象为弹性分布式数据集(RDD),实现了任务调度、RPC、序列化和压缩。
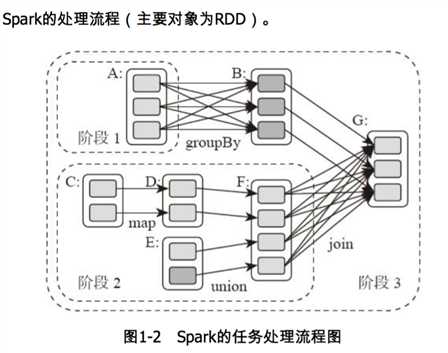 Spark将数据在分布式环境下分区,然后将作业转化为有向无环图,并分阶段进行DAG的调度和任务的分布式并行处理。
Spark将数据在分布式环境下分区,然后将作业转化为有向无环图,并分阶段进行DAG的调度和任务的分布式并行处理。
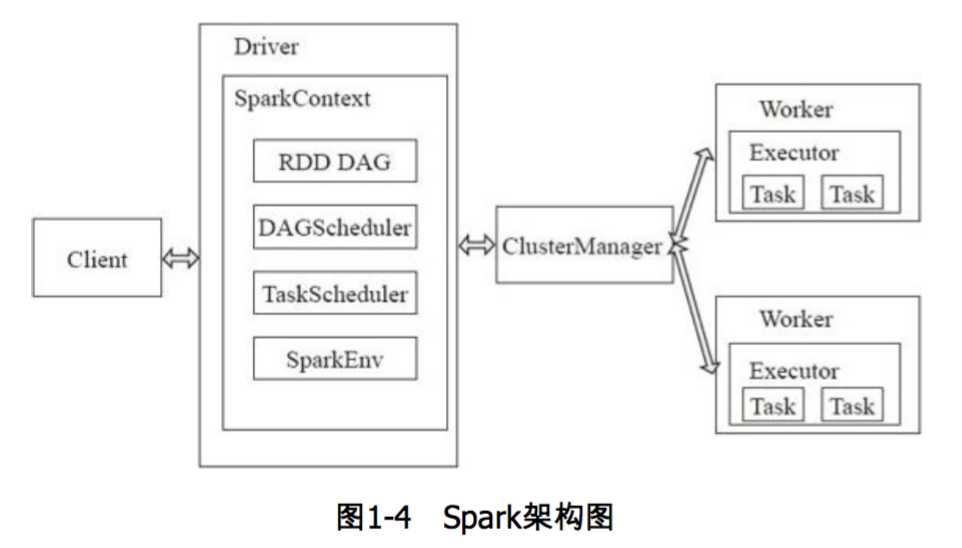
Spark架构采用了分布式计算中的Master-Slave模型。Master是对应集群中的含有Master进程的节点,作为整个集群的控制器,负载整个集群的正常运行;Slave是集群中含有Worker进程的节点。Worker相当于是计算节点,接受主节点命名与进行状态汇报。
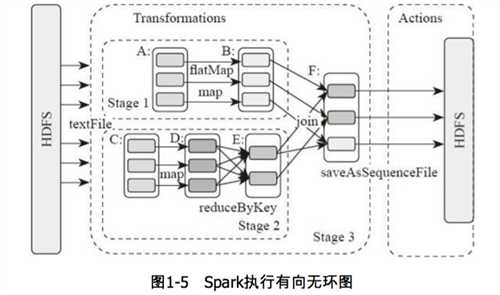
图中的A,B,C,D,E,F分别代表不同的RDD,RDD内的方框代表分区。数据从HDFS输入Spark,形成RDD A和RDD C,RDD C上执行map操作,转化为D,B,E执行join操作,转换为F,而在B和E连接转化为F的过程中又会执行Shuffle,最后F通过函数saveAsSequenceFile输出并保存到HDFS中。
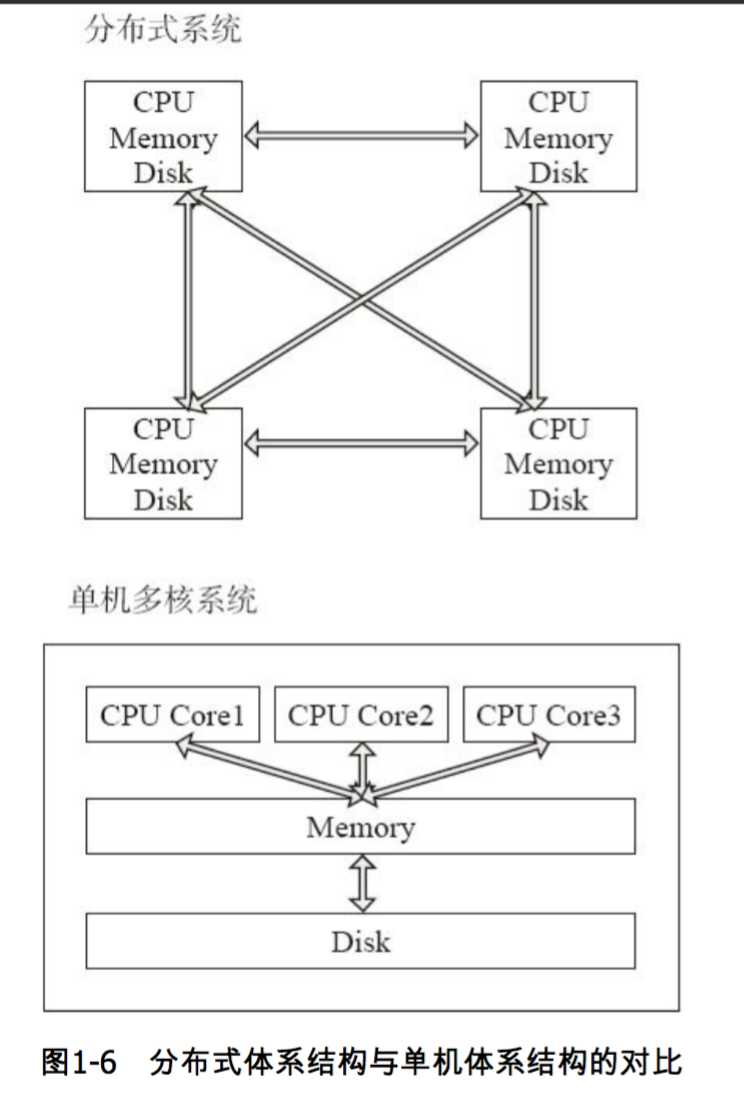
单机多核环境下,多CPU共享内存和磁盘;而分布式并行处理系统是由许多松耦合的处理单元组成的,每个单元内的CPU都有自己的资源,如总线,内存,硬盘等。其最大的特点就是不共享资源,即计算能力和存储扩展性可以成倍增长。
标签:
原文地址:http://www.cnblogs.com/JXPITer/p/4859220.html