标签:style blog http color 使用 strong
欢迎转载,转载请注明出处,徽沪一郎。
上篇博文讲述了如何通过修改源码来查看调用堆栈,尽管也很实用,但每修改一次都需要编译,花费的时间不少,效率不高,而且属于侵入性的修改,不优雅。本篇讲述如何使用intellij idea来跟踪调试spark源码。
本文假设开发环境是在Linux平台,并且已经安装下列软件,我个人使用的是arch linux。
为idea安装scala插件,具体步骤如下
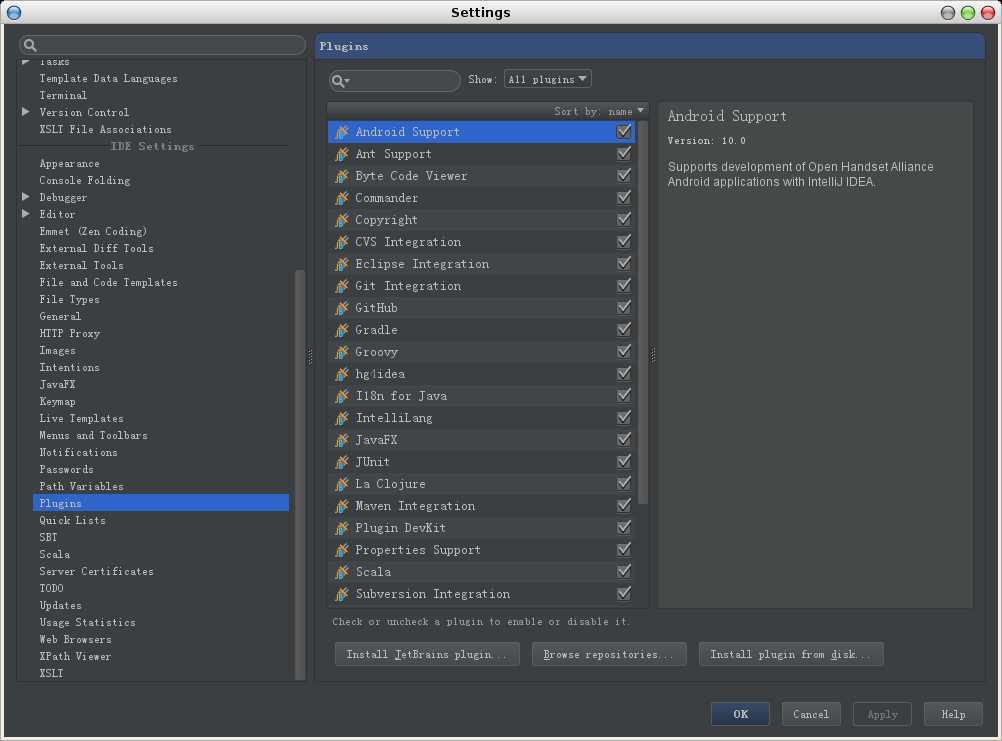
2 步骤2: 选择右侧的Install Jetbrains Plugin,在弹出窗口的左侧输入scala,然后点击安装,如下图所示
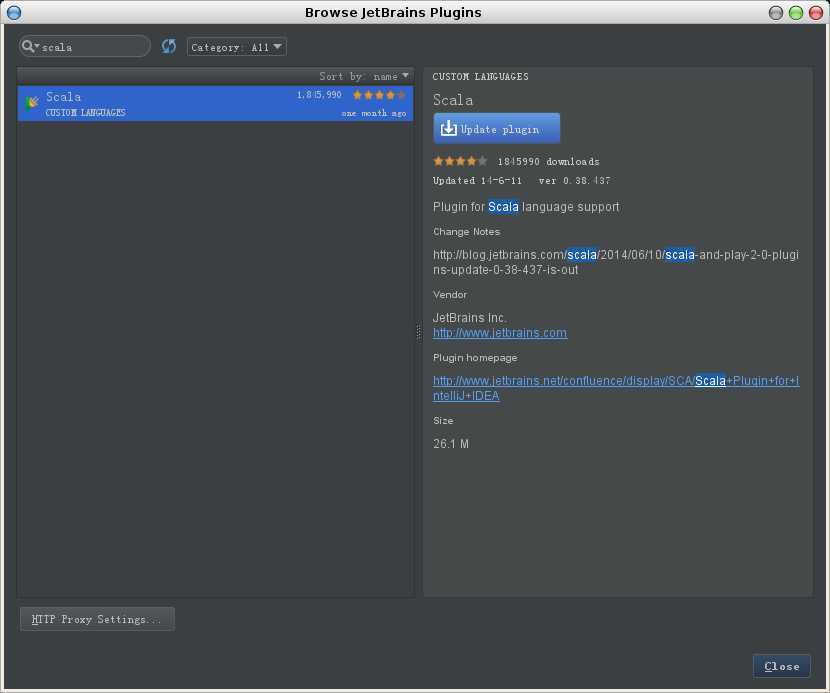
3. scala插件安装结束,需要重启idea生效
由于idea 13已经原生支持sbt,所以无须为idea安装sbt插件。
下载源码,假设使用git同步最新的源码
git clone https://github.com/apache/spark.git
生成idea工程
sbt/sbt gen-idea
导入Spark源码
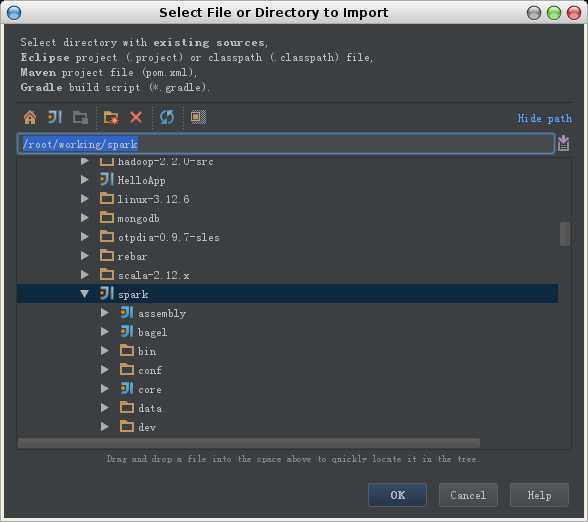
1. 选择File->Import Project, 在弹出的窗口中指定spark源码目录
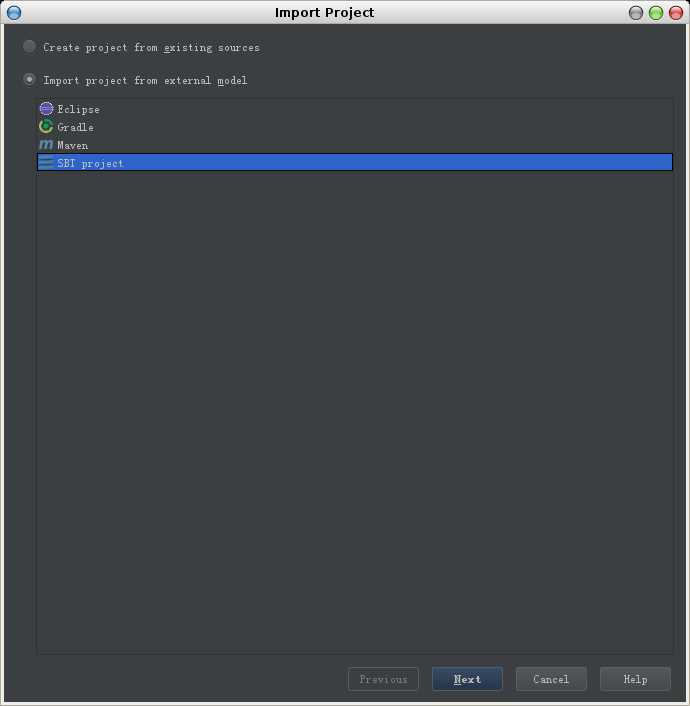
2. 选择项目类型为sbt project,然后点击next
3. 在新弹出的窗口中点击Finish
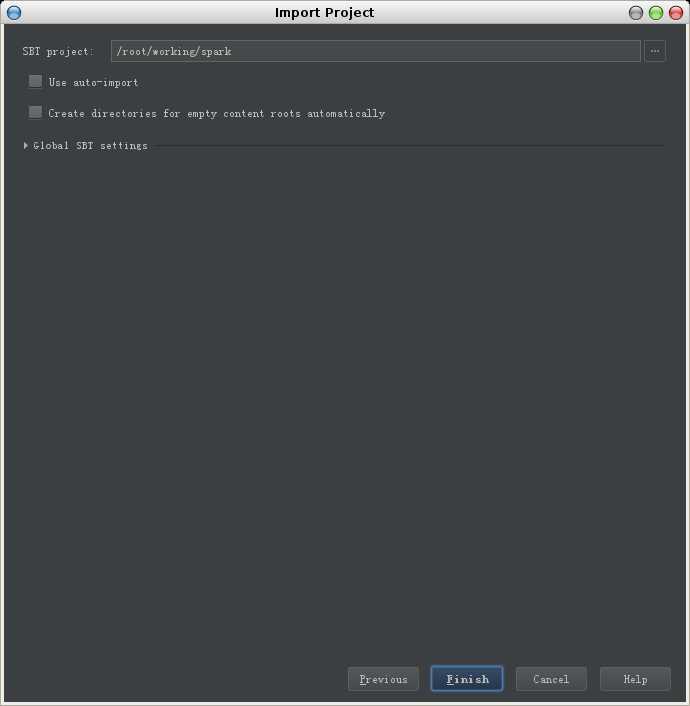
导入设置完成,进入漫长的等待,idea会对导入的源码进行编译,同时会生成文件索引。
如果在提示栏出现如下的提示内容"is waiting for .sbt.ivy.lock",说明该lock文件无法创建,需要手工删除,具体操作如下
cd $HOME/.ivy2
rm *.lock
手工删除掉lock之后,重启idea,重启后会继续上次没有完成的sbt过程。
使用idea来编译spark源码,中间会有多次出错,问题的根源是sbt/sbt gen-idea的时候并没有很好的解决依赖关系。
解决办法如下,
1. 选择File->Project Structures
2. 在右侧dependencies中添加新的module,
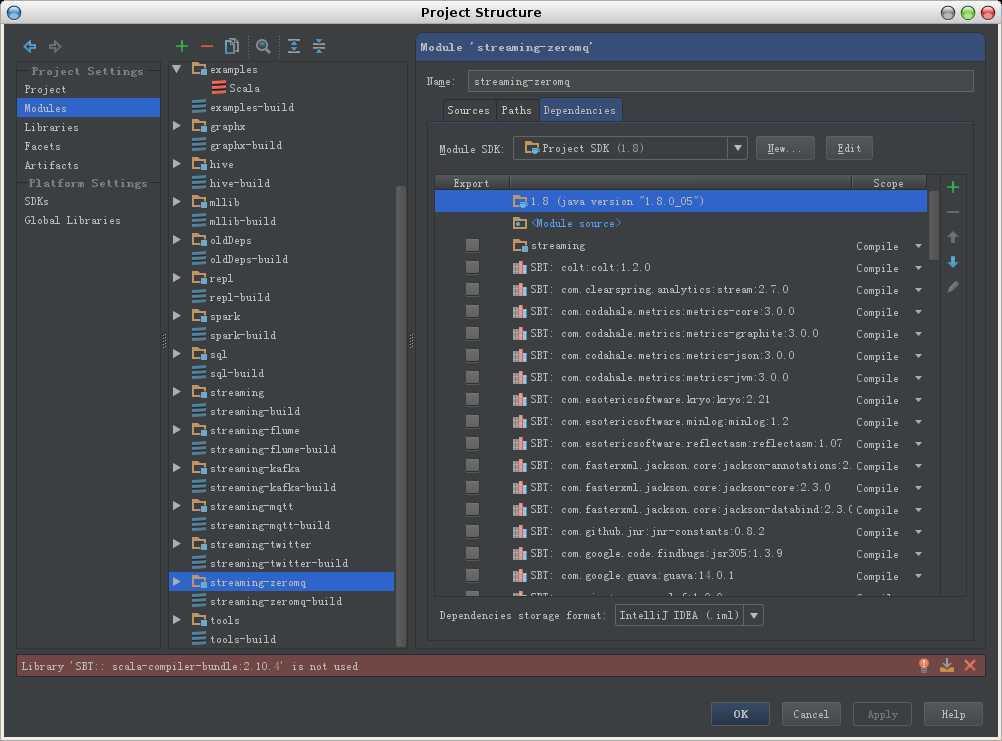
选择spark-core
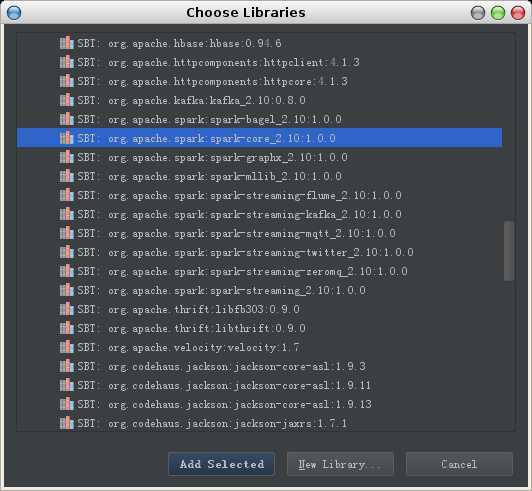
其它模块如streaming-twitter, streaming-kafka, streaming-flume, streaming-mqtt出错的情况解决方案与此类似。
注意Example编译报错时的处理稍有不同,在指定Dependencies的时候,不是选择Library而是选择Module dependency,在弹出的窗口中选择sql.
有关编译出错问题的解决可以看一下这个链接,http://apache-spark-user-list.1001560.n3.nabble.com/Errors-occurred-while-compiling-module-spark-streaming-zeromq-IntelliJ-IDEA-13-0-2-td1282.html
1. 选择Run->Edit configurations
2. 添加Application,注意右侧窗口中配置项内容的填写,分别为Main class, vm options, working directory, use classpath of module
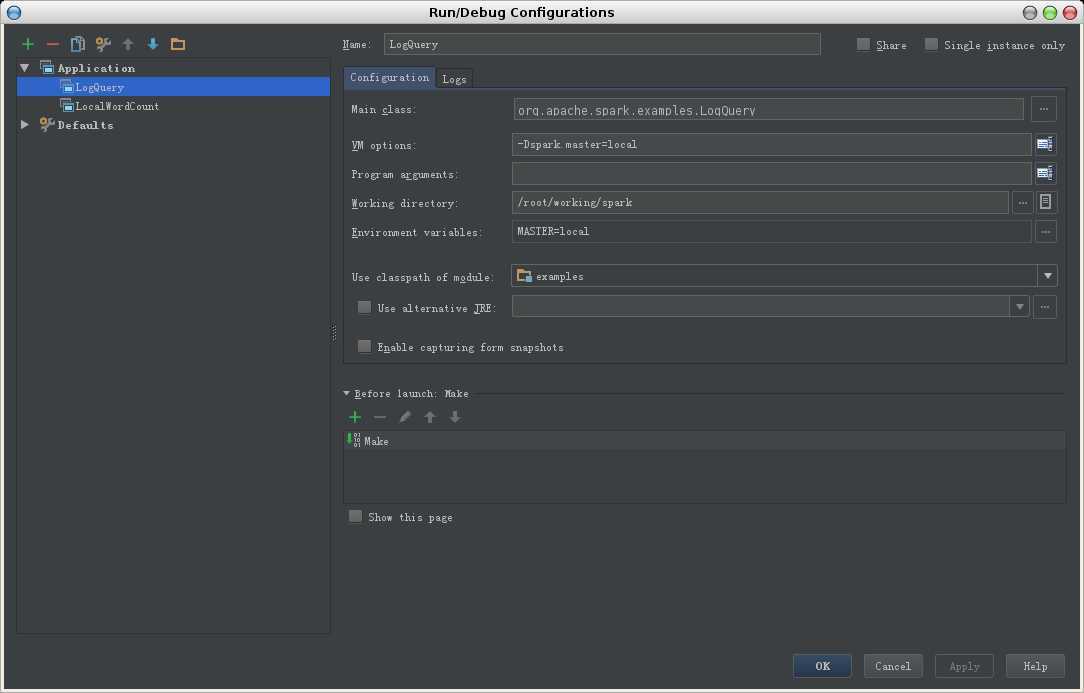
-Dspark.master=local 指定Spark的运行模式,可根据需要作适当修改。
3. 至此,在Run菜单中可以发现有"Run LogQuery"一项存在,尝试运行,保证编译成功。
4. 断点设置,在源文件的左侧双击即可打上断点标记,然后点击Run->"Debug LogQuery", 大功告成,如下图所示,可以查看变量和调用堆栈了。
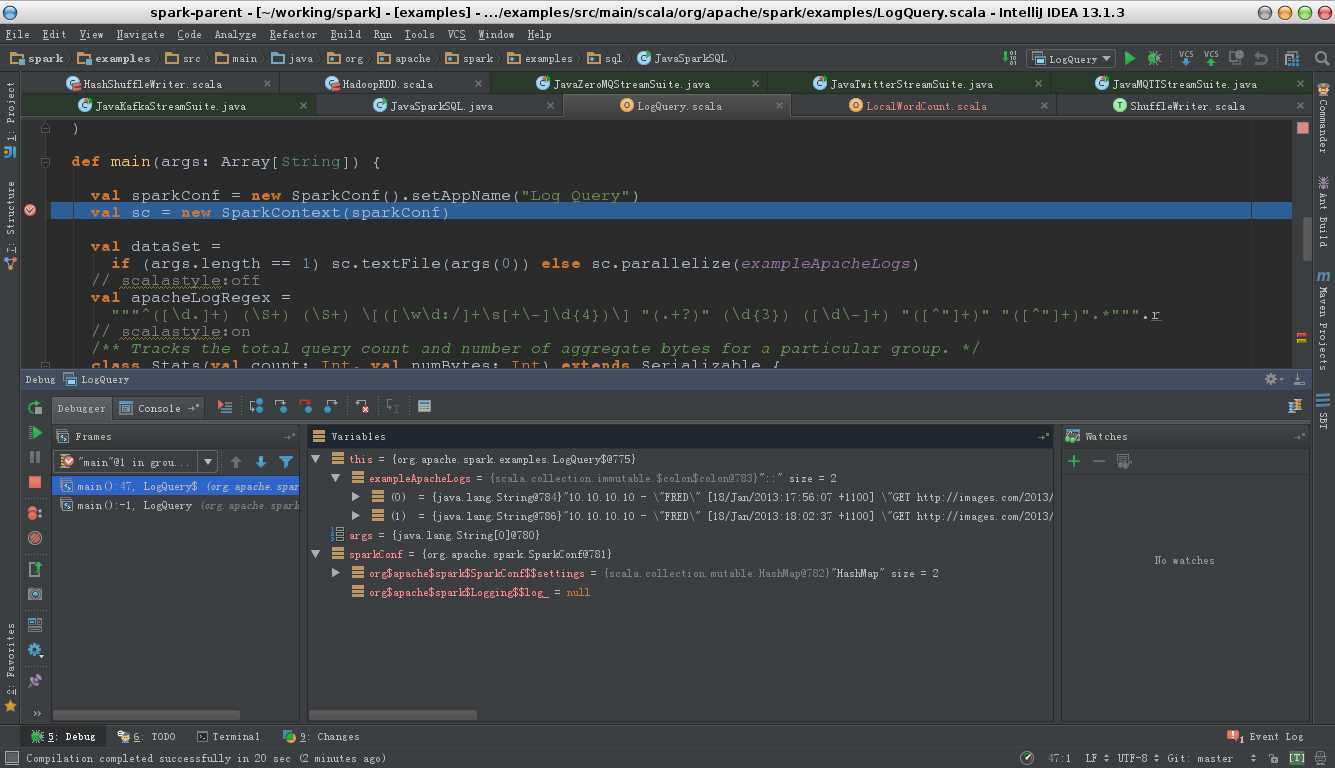
参考
Apache Spark源码走读之18 -- 使用Intellij idea调试Spark源码,布布扣,bubuko.com
Apache Spark源码走读之18 -- 使用Intellij idea调试Spark源码
标签:style blog http color 使用 strong
原文地址:http://www.cnblogs.com/hseagle/p/3850841.html