标签:
主要解决一个问题,就是针对每次mapreduce的计算的时候希望通过一个缓存可以做做些查找,希望针对map或者reduce到的每条记录可以直接在内存中找到数据,如果找不到那么需要加载到内存!
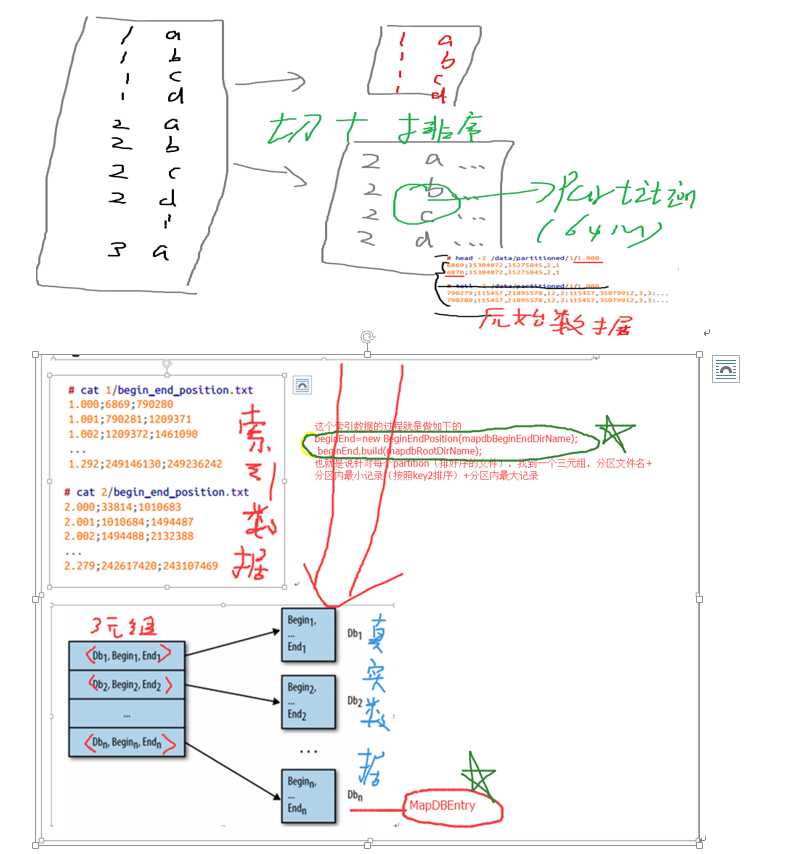
这个索引的结构也就是 <分区文件名字,开始position,结束position> 这个三元组。
原始数据如上图所示,现在还需要一个meta data去组织数据
比如固定key1以后的按照key2做排序后split形成的partition文件如下:

这个文件就是最后的partition文件,注意:
Note that each of these partitioned files has a range of position values (since they are sorted by position). We will use these ranges in our cache implementation. Therefore, given a chromosome_id=1 and a position, we know exactly which partition holds the result of a query. Let’s look at the content of one of these sorted partitioned files如下是partition文件的内容,最左边的就是position(就是key2)字段,然后这个partition name是和key1有关系的:
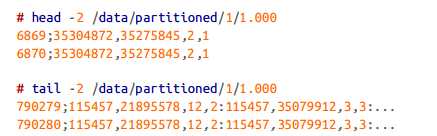
You can see that all positions are sorted within each partition. To support meta‐ data for all partitions using LRU Map, we need an additional data structure to keep track of (begin, end) positions. For each partitioned file we will keep the (partition name, begin, end) information.
伪代码:
>>BeginEndPosition对象实现了 the partition data structure such that you can get the database name for a given composite key.--作用就是
根据chrId+position得到database name。
>> 注意MapDBEntry class 代表了 sorted partition of 64MB as a Map data structure implemented in MapDB.
the MapDBEntry class defines a single entry of a MapDB object ,比如new一个MapDBEntry对象的过程
public static MapDBEntry create(String dbName){
DB db=DBMaker.newFileDB(new File(dbName)).closeOnJvmShutDown().readOnly().make();
Map<String,String> map=db.getTreeMap("collectionName");
//可以从外村加载数据到map中去
MapDBEntry entry=new MapDBEntry(db,map);
return entry;
}
>>1、然后是cacheManager的初始化过程分析,注意cacheManage管理的是每一个partition,所以做替换内存操作的是每一个partition的操作!!!!
public static void init() throws Exception{
if(initialized)
return;
//注意这里的map类型 value是一个MapDBEntry类型的,其实
//这个数据结构说白了就是map中套map的类型
theCustomLRUMap=new CustomLRUMap<String,MapDBEntry<String,String>>(theLRUMapSize);
beginEnd=new BeginEndPosition(mapdbBeginEndDirName);
beginEnd.build(mapdbRootDirName);
initilized=true;
}
>>2、然后是使用
//首先是getDBName()
//
public static String getDBName(String key1,String key2){
List<Interval> results=beginEnd.query(key1,key2);
if(results==null || results.isEnpty()||results.size()==0) return null;
else return results.get(0).db();
}
//
public static String get(String key1,String key2) throws Exception{
String dbName=getDBName(key1,key2);
if(dbName==null) return null;
MapDBEntry<String,String> entry=theCustomLRUMap.get(dbName);
if(entry==null){
//需要做替换了
entry=MapDBEntryFactory.create(dbName);
theCustomLRUMap.put(dbName,entry);
}
return entry.getValue(key2);
}
标签:
原文地址:http://www.cnblogs.com/amazement/p/4866369.html