标签:







个人总结:
1、这一篇文章主要是证明性的东西为主,所以说数学公式相对较多,原文笔记作者省略了一些东西,没有和上文很好衔接,所以初学者不一定看明白,建议结合斯坦福机器学习原文讲义(是英文的,没找到有全文中文翻译版的)看一看,如果刚入门对公式的推导就迷糊,说明你有必要去学一些数学基础。
2、结合上一篇文章中提到的梯度下降方法,本文提出了一种更快的迭代方法,叫牛顿方法。原文中公式(1)都能看懂,一转眼怎么就变公式(2)了呢?不知有没有对此迷糊的朋友,其实原文作者这么写确实存在误会,实际上公式(2)不应该写成f(theta)的形式,而是L(theta),而L(theta)是谁?就是上篇文章中提到的似然估计函数:

写成对数形式为:
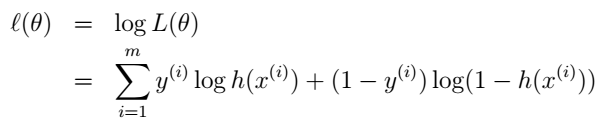
求导后:

所以说公式(2)中的f‘(theta)其实就是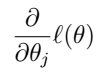 ,而f‘‘(theta)就是对上式再次求导。
,而f‘‘(theta)就是对上式再次求导。
3、上文中提到牛顿方法迭代速度快,并提到它是二次收敛,想必很多人想问啥是二次收敛,为啥就快呢?简单的说就是牛顿方法考虑了梯度的梯度,在二阶函数中可以直接找到最快的下降方法,一步到位,实际上它是采用二次曲面去拟合当前位置的曲面,而梯度下降是用平面去拟合当前曲面。如果你还不理解,看下面这张来自wiki的图,

红色的线是牛顿法,绿色的线是梯度下降法,通俗的理解就是梯度下降属于贪心算法,走一步看一步,每次都选当前梯度最大方向下降,而牛顿法可以考虑梯度的梯度,具有全局眼光,它会考虑你走完一步后的梯度是否会变大,所以更符合真实的最优下降策略。这里面涉及的一些理论、数学证明以及凸优化理论可以参考:最优化问题中,牛顿法为什么比梯度下降法求解需要的迭代次数更少?以及梯度-牛顿-拟牛顿优化算法和实现
4、关于上篇文章中最后提到的问题,为什么逻辑回归算法与最小二乘法最后公式的形式很像,本文已给出证明,它们都属于指数分布家族,而且借此引出了广义线性回归的模型,这部分数学推导较多,数学基础不是很好的可以看下英文讲义原文,实在看不懂就记个结论吧。
5、关于牛顿方法,上文提过,有一个H(n*n,实际为(n+1)*(n+1)包括x0截距项,n为属性个数)矩阵,所以n不能太大,牛顿方法可以与随机梯度下降结合使用,先利用随机梯度下降找到最优值附近的点,再利用牛顿法,效果会更好一些。
6、关于多分类的问题,实际上是二分类的一种推广,对于多分类的问题,多使用树模型,回归树、分类树等
标签:
原文地址:http://my.oschina.net/dfsj66011/blog/515169