标签:
基本的矩阵分解方法通过学习用户和物品的特征向量进行预测,即用户和物品的交互信息。用户的特征向量代表了用户的兴趣,物品的特征向量代表了物品的特点,且每一个维度相互对应,两个向量的内积表示用户对该物品的喜好程度。但是我们观测到的评分数据大部分都是都是和用户或物品无关的因素产生的效果,即有很大一部分因素是和用户对物品的喜好无关而只取决于用户或物品本身特性的。例如,对于乐观的用户来说,它的评分行为普遍偏高,而对批判性用户来说,他的评分记录普遍偏低,即使他们对同一物品的评分相同,但是他们对该物品的喜好程度却并不一样。同理,对物品来说,以电影为例,受大众欢迎的电影得到的评分普遍偏高,而一些烂片的评分普遍偏低,这些因素都是独立于用户或产品的因素,而和用户对产品的的喜好无关。
我们把这些独立于用户或独立于物品的因素称为偏置(Bias)部分,将用户和物品的交互即用户对物品的喜好部分称为个性化部分。事实上,在矩阵分解模型中偏好部分对提高评分预测准确率起的作用要大大高于个性化部分所起的作用,以Netflix Prize推荐比赛数据集为例为例,Yehuda Koren仅使用偏置部分可以将评分误差降低32%,而加入个性化部分能降低42%,也就是说只有10%是个性化部分起到的作用,这也充分说明了偏置部分所起的重要性,剩下的58%的误差Yehuda Koren将称之为模型不可解释部分,包括数据噪音等因素。
偏置部分表示为
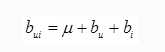
偏置部分主要由三个子部分组成,分别是
以上所有偏置和用户对物品的喜好无关,我们将偏置部分当作基本预测,在此基础上添加用户对物品的喜好信息,即个性化部分,因此得到总评分预测公式如下:
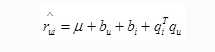
其中最后一项即为我们预测模型中的个性化部分,花括号部分为偏置部分,两个部分相加即得到最终预测评分。
模型训练过程中仍采用平方误差作为损失函数,优化函数表示如下:
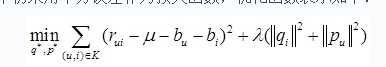
优化以上函数,分别获得用户特征矩阵P、物品特征矩阵Q、各用户偏置bu、各物品偏置bi,优化方法仍可采用交叉最小二乘或随机梯度下降。
数据集偏置:数据总体评分情况
用户偏执:用户的评分习惯
物品偏置:垃圾篇评分偏低,好的偏高。
偏置加上PQ的内积就是预测分数。
标签:
原文地址:http://www.cnblogs.com/hxsyl/p/4872233.html