标签:style blog http color 使用 strong
基于相似性聚类
很多时候,我们想了解一群人中的一个成员与其他成员之间有多么相似。例如,假设我们是一家品牌营销公司,刚刚完成了一份挂怒有潜力新品牌的研究调查问卷。在这份调查问卷中,我们向一群人展示了新品牌的几个特征,并且要求他们对这个新品牌的每个特征按五分制打分。同时也收集了目标人群的社会经济特征,例如:年龄、性别、种族、住址的邮编以及大概的年收入。
通过这份调查问卷,我们想搞清楚品牌如何吸引不同社会经济特征的人群。最重要的是,我们想要知道这个品牌是否有很大的吸引力。换个角度想这个问题,我们想看看那些最喜欢这个品牌特征的人们,是否有多种多样的社会经济特征。实现这一点的一种方法就是对问卷受访者的聚类结果进行可视化。然后就可以使用各种各样的视觉线索,识别出不同社会经济特征的成员。也就是说,我们想要看到大量不同性别、不同种族以及不同收入的人聚类到一起。
同样,我们想要使用这些知识来看看,相近的人群如何基于品牌吸引力而聚类到一起的。我们也想看看一个聚类中有多少人,或者它与其他聚类的距离有多远。这也能告诉我们这个品牌的什么特征吸引了不同社会经济特征的人群。
在提出这些问题时,我们使用这样的名词,如“近”和“远”,它们本身都是说明距离概念的词。因此,为了使聚类结果之间的距离更形象化,我们需要引入一些个体聚集的空间概念。
对不同的观测记录,如何理解用距离的概念来阐明它们之间的相似性和相异性。这需要针对分析数据定义一些不同类型的距离矩阵。例如,在假设的品牌市场情形中,我们可以利用调查规模的顺序性以及一种非常直接的方式发现不同受访者之间的距离:简单计算绝对差异。
可是,仅仅计算这些距离还不够。下面我们介绍一种叫做多维定标(multidimensional scaling,MDS)的技术。该技术的目的是基于观察值之间的距离度量进行聚类。通过MDS,我们可以只使用所有点之间的一个距离度量,就能将数据进行可视化。
距离度量与多维定标简介
在正式开始介绍之前,假设已有一份非常简单的数据,这份数据中有四个用户,以及他们对六个产品的评分。每个用户按要求对每个产品给出一个“拇指向上”(1)或者“拇指向下”(-1)的评价,如果他们对某个产品没有任何意见,也可忽略这个产品(0)。有很多评价系统采用这种方式,包括YouTube等。我们想使用这个评分数据度量每个用户和其他用户之间有多大的相似性。
在这个简单的例子中,我们创建一个4*6的矩阵A,行表示用户,列表示产品。元素aij表示用户 i 给产品 j 的评价。
set.seed(851982) ex.matrix<-matrix(sample(c(-1,0,1),24,replace=TRUE),nrow=4,ncol=6) row.names(ex.matrix)<-c(‘A‘,‘B‘,‘C‘,‘D‘) colnames(ex.matrix)<-c(‘P1‘,‘P2‘,‘P3‘,‘P4‘,‘P5‘,‘P6‘)
|
|
row.names |
P1 |
P2 |
P3 |
P4 |
P5 |
P6 |
|
|
1 |
A |
0 |
-1 |
0 |
-1 |
0 |
0 |
|
|
2 |
B |
-1 |
0 |
1 |
1 |
1 |
0 |
|
|
3 |
C |
0 |
0 |
0 |
1 |
-1 |
1 |
|
|
4 |
D |
1 |
0 |
1 |
-1 |
0 |
0 |
|
矩阵A将用户和产品关联起来,我们需要把这矩阵转化成用户与用户关联的矩阵B:(B=AAT)
ex.matrix<-ex.matrix %*% t(ex.matrix)
|
|
row.names |
A |
B |
C |
D |
|
1 |
A |
2 |
-1 |
-1 |
1 |
|
2 |
B |
-1 |
4 |
0 |
-1 |
|
3 |
C |
-1 |
0 |
3 |
-1 |
|
4 |
D |
1 |
-1 |
-1 |
3 |
非主对角线元素的正值越大,则两个用户的评价分就越一致;同样,负值越小,则两个用户的评价分就越不一致。因为我们最初的矩阵中的元素是随机的,所以不同用户之间的差异很小。对角线元素的值只是反映了每个用户对多少个产品进行了评分。
现在,我们有了关于用户之间差异的摘要,在一定程度上这是有用的。例如,用户A和用户D都给了产品4反对票;可是,用户D喜欢产品1和产品3,而用户A根本没有对他们进行评价。因此,从他们给出投票信息的那些产品角度来看,我们可以说这两个用户是相似的,因此我们有一个值为1的元素对应他们的关系。很遗憾,这个结果传达的信息是有限的,因为我们只能对用户共有评分记录给出一些解释。但是我们想要的方法是可以把用户评分记录的差异化到更丰富的表达程度。
为此,我们引入欧氏距离(Euclidean distance)的概念:
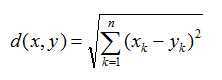
我们想要基于上面的矩阵的乘积所定义的整体相似性和差异性度量,来计算所有用户之间的欧氏距离。为了实现这一点,我们将把每个用户的所有评分作为一个向量。用户A和用户B的欧氏距离:
sqrt(sum((ex.matrix[1,]-ex.matrix[4,])^2))
[1] 2.236068
任意用户之间的距离:
ex.dist<-dist(ex.matrix) ex.dist A B C B 6.244998 C 5.477226 5.000000 D 2.236068 6.782330 6.082763
#dist()函数返回一个关于距离的矩阵(可设置参数upper=TRUE覆盖只显示下三角的默认值)
可视化表示:
ex.mds<-cmdscale(ex.dist) plot(ex.mds,type=‘n‘) text(ex.mds,c(‘A‘,‘B‘,‘C‘,‘D‘))
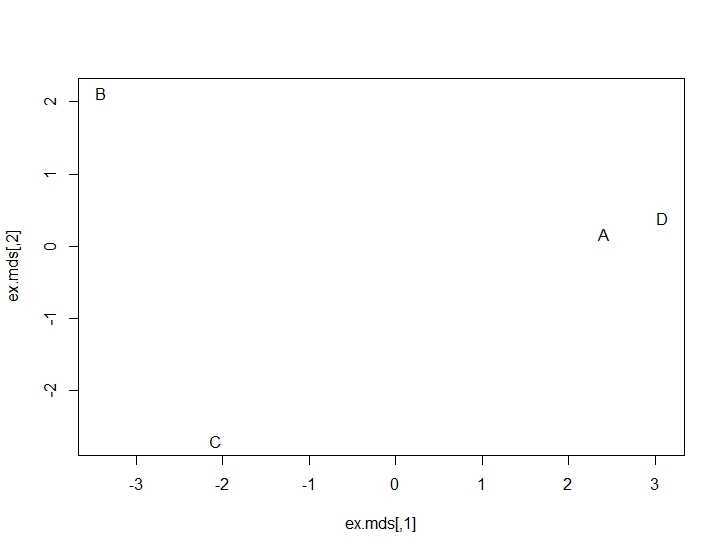
用户A和用户D确实在图的中间靠右的位置被聚类到了一起。可是,用户B和用户C根本就没有形成聚类。从我们的数据来看用户A和用户D具有某种程度的相似口味。想要深入理解请查阅MDS算法
如何对美国参议员做聚类
当前的国会——第111届国会是历史中意识形态两极化最严重的一届。在白宫和参议院中,最保守的民主党都要比最开明的共和党还要开明。如果把国会“中心”定义为两党重叠的部分,那么这个中心已经消失了。
——William A.Galston布鲁金斯学会(2010)
使用MDS对参议员聚类进行可视化,以此观察两党成员是否有混合在一起的情况。可是,在做这些事情之前,我们需要一个参议员之间距离的衡量标准。幸运的是,我们可以使用立法者的公开记录创建一个合理的距离度量。我们可以使用记名投票记录来看一个立法者是支持还是反对一项提案。就像前面例子中用户给出的“拇指向上”或者“拇指向下”的评价一样,立法者使用“赞同”或者“反对”对法案进行投票。数据下载地址:http://www.voteview.com/,它是一个存放美国记名投票数据的仓库。
 R code
R code
library(‘foreign‘) library(‘ggplot2‘) data.dir <- file.path("data", "roll_call") data.files <- list.files(data.dir) data.files #[1] "sen101kh.dta" "sen102kh.dta" #[3] "sen103kh.dta" "sen104kh.dta" #[5] "sen105kh.dta" "sen106kh.dta" #[7] "sen107kh.dta" "sen108kh_7.dta" #[9] "sen109kh.dta" "sen110kh_2008.dta" #[11] "sen111kh.dta" # Eighth code snippet # Add all roll call vote data frames to a single list rollcall.data <- lapply(data.files, function(f) { read.dta(file.path(data.dir, f), convert.factors = FALSE) }) # Ninth code snippet dim(rollcall.data[[1]]) #[1] 103 647 head(rollcall.data[[1]]) #cong id state dist lstate party eh1 eh2 name V1 V2 V3 ... V638 #1 101 99908 99 0 USA 200 0 0 BUSH 1 1 1 ... 1 #2 101 14659 41 0 ALABAMA 100 0 1 SHELBY, RIC 1 1 1 ... 6 #3 101 14705 41 0 ALABAMA 100 0 1 HEFLIN, HOW 1 1 1 ... 6 #4 101 12109 81 0 ALASKA 200 0 1 STEVENS, TH 1 1 1 ... 1 #5 101 14907 81 0 ALASKA 200 0 1 MURKOWSKI, 1 1 1 ... 6 #6 101 14502 61 0 ARIZONA 100 0 1 DECONCINI, 1 1 1 ... 6 # Tenth code snippet # This function takes a single data frame of roll call votes and returns a # Senator-by-vote matrix. rollcall.simplified <- function(df) { no.pres <- subset(df, state < 99) for(i in 10:ncol(no.pres)) { no.pres[,i] <- ifelse(no.pres[,i] > 6, 0, no.pres[,i]) no.pres[,i] <- ifelse(no.pres[,i] > 0 & no.pres[,i] < 4, 1, no.pres[,i]) no.pres[,i] <- ifelse(no.pres[,i] > 1, -1, no.pres[,i]) } return(as.matrix(no.pres[,10:ncol(no.pres)])) } rollcall.simple <- lapply(rollcall.data, rollcall.simplified) # Eleventh code snippet # Multiply the matrix by its transpose to get Senator-to-Senator tranformation, # and calculate the Euclidan distance between each Senator. rollcall.dist <- lapply(rollcall.simple, function(m) dist(m %*% t(m))) # Do the multidimensional scaling rollcall.mds <- lapply(rollcall.dist, function(d) as.data.frame((cmdscale(d, k = 2)) * -1)) # Twelfth code snippet # Add identification information about Senators back into MDS data frames congresses <- 101:111 for(i in 1:length(rollcall.mds)) { names(rollcall.mds[[i]]) <- c("x", "y") congress <- subset(rollcall.data[[i]], state < 99) congress.names <- sapply(as.character(congress$name), function(n) strsplit(n, "[, ]")[[1]][1]) rollcall.mds[[i]] <- transform(rollcall.mds[[i]], name = congress.names, party = as.factor(congress$party), congress = congresses[i]) } head(rollcall.mds[[1]]) #x y name party congress #2 -11.44068 293.0001 SHELBY 100 101 #3 283.82580 132.4369 HEFLIN 100 101 #4 885.85564 430.3451 STEVENS 200 101 #5 1714.21327 185.5262 MURKOWSKI 200 101 #6 -843.58421 220.1038 DECONCINI 100 101 #7 1594.50998 225.8166 MCCAIN 200 101 # Thirteenth code snippet # Create a plot of just the 110th Congress cong.110 <- rollcall.mds[[9]] base.110 <- ggplot(cong.110, aes(x = x, y = y)) + scale_size(range = c(2,2), guide = ‘none‘) + scale_alpha(guide = ‘none‘) + theme_bw() + theme(axis.ticks = element_blank(), axis.text.x = element_blank(), axis.text.y = element_blank(), panel.grid.major = element_blank()) + ggtitle("Roll Call Vote MDS Clustering for 110th U.S. Senate") + xlab("") + ylab("") + scale_shape(name = "Party", breaks = c("100", "200", "328"), labels = c("Dem.", "Rep.", "Ind."), solid = FALSE) + scale_color_manual(name = "Party", values = c("100" = "black", "200" = "dimgray", "328"="grey"), breaks = c("100", "200", "328"), labels = c("Dem.", "Rep.", "Ind.")) print(base.110 + geom_point(aes(shape = party, alpha = 0.75, size = 2))) print(base.110 + geom_text(aes(color = party, alpha = 0.75, label = cong.110$name, size = 2))) # Fourteenth code snippet # Create a single visualization of MDS for all Congresses on a grid all.mds <- do.call(rbind, rollcall.mds) all.plot <- ggplot(all.mds, aes(x = x, y = y)) + geom_point(aes(shape = party, alpha = 0.75, size = 2)) + scale_size(range = c(2, 2), guide = ‘none‘) + scale_alpha(guide = ‘none‘) + theme_bw() + theme(axis.ticks = element_blank(), axis.text.x = element_blank(), axis.text.y = element_blank(), panel.grid.major = element_blank()) + ggtitle("Roll Call Vote MDS Clustering for U.S. Senate (101st - 111th Congress)") + xlab("") + ylab("") + scale_shape(name = "Party", breaks = c("100", "200", "328"), labels = c("Dem.", "Rep.", "Ind."), solid = FALSE) + facet_wrap(~ congress) print(all.plot) # This is the code omitted from the chapter. This is used to create shnazy plots of everything! for(i in 1:length(rollcall.mds)) { mds <- rollcall.mds[[i]] congress <- congresses[i] plot.title <- paste("Roll Call Vote MDS Clustering for ", congress, " U.S. Senate", sep = "") # Build base plot mds.plot <- ggplot(mds, aes(x = x, y = y)) + scale_size(range = c(2, 2), guide = ‘none‘) + scale_alpha(guide = ‘none‘) + theme_bw() + theme(axis.ticks = element_blank(), axis.text.x = element_blank(), axis.text.y = element_blank(), panel.grid.major = element_blank()) + ggtitle(plot.title) + xlab("") + ylab("") # Build up point and text plots separately mds.point <- mds.plot + geom_point(aes(shape = party, alpha = 0.75, size = 2)) mds.text <- mds.plot + geom_text(aes(color = party, alpha = 0.75, label = mds$name, size = 2)) # Fix labels, shapes and colors if(length(levels(mds$party)) > 2) { mds.point <- mds.point + scale_shape(name = "Party", breaks = c("100", "200", "328"), labels = c("Dem.", "Rep.", "Ind."), solid = FALSE) mds.text <- mds.text + scale_color_manual(name = "Party", values = c("100" = "black", "200" = "dimgray", "328" = "gray"), breaks = c("100", "200", "328"), labels = c("Dem.", "Rep.", "Ind.")) } else { mds.point <- mds.point + scale_shape(name = "Party", breaks = c("100", "200"), labels = c("Dem.", "Rep."), solid = FALSE) mds.text <- mds.text + scale_color_manual(name = "Party", values = c("100" = "black", "200" = "dimgray"), breaks = c("100", "200"), labels = c("Dem.", "Rep.")) } ggsave(plot = mds.point, filename = file.path(‘images‘, ‘senate_plots‘, paste(congress, "_point.pdf", sep = "")), width = 8, height = 5) ggsave(plot = mds.text, filename = file.path(‘images‘, ‘senate_plots‘, paste(congress, "_names.pdf", sep = "")), width = 8, height = 5) }
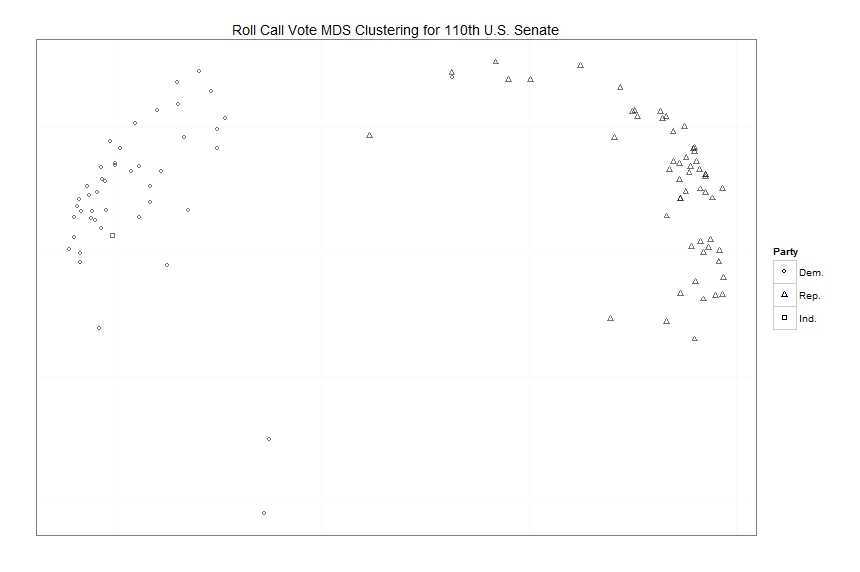
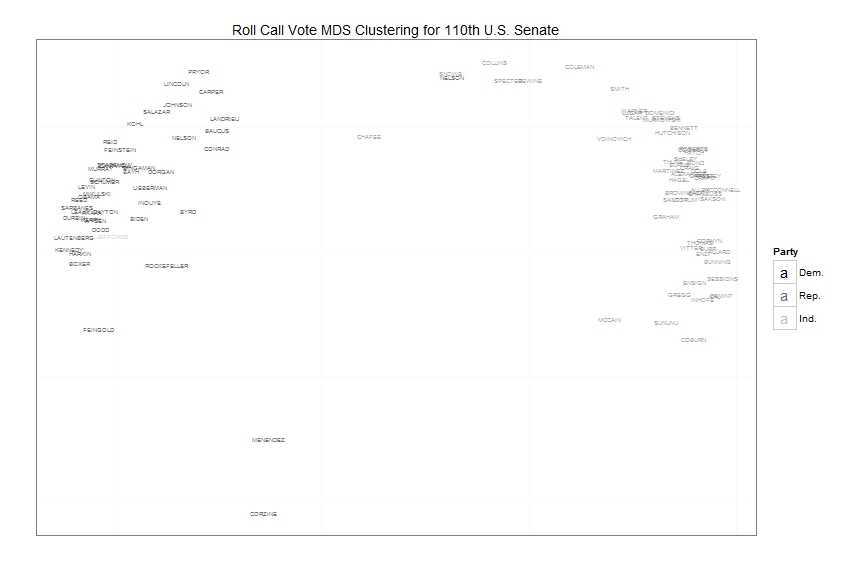

从这些结果可以看出,美国参议院实际上和过去一样具有党派性。大体上来说,在每一届国会中我们只能看到大量的三角形和圆形分别聚集在一起,而只有少数异常数据点。你也许会说,第101届和第102届国会两级分化不那么严重。这是坐标轴刻度造成的结果。这不意味这这两届国会的两极分化更轻。因为在一张图中对他们进行可视化,必须在不同的面板中使用相同的刻度,这导致有些图看上去更拥挤,而有的图铺得更开。
R语言学习笔记 之 可视化地研究参议员相似性,布布扣,bubuko.com
标签:style blog http color 使用 strong
原文地址:http://www.cnblogs.com/LittleTreasureBox/p/3851045.html
