标签:des blog http java 使用 strong
对于90%以上想学习Spark的人而言,如何构建Spark集群是其最大的难点之一,为了解决大家构建Spark集群的一切困难,家林把Spark集群的构建分为了四个步骤,从零起步,不需要任何前置知识,涵盖操作的每一个细节,构建完整的Spark集群。
从零起步,构建Spark集群经典四部曲:
第一步:搭建Hadoop单机和伪分布式环境;
第二步:构造分布式Hadoop集群;
第三步:构造分布式的Spark集群;
第四步:测试Spark集群;
本文内容为构建Spark集群经典四部曲的第一步,从零起步构建Hadoop单机版本和伪分布式的开发环境,涉及:
开发Hadoop需要的基本软件;
安装每个软件;
配置Hadoop单机模式并运行Wordcount示例;
配置Hadoop伪分布式模式并运行Wordcount示例;
我们的开发环境是在Windows 7上面构建Hadoop,此时需要Vmware虚拟机、Ubuntu的ISO镜像文件,Java SDK的支持、Eclipse IDE平台、Hadoop安装包等;
1、Vmware虚拟机,这里使用的是VMware Workstation 9.0.2 for Windows, 具体的下载地址是https://my.vmware.com/cn/web/vmware/details?downloadGroup=WKST-902-WIN&productId=293&rPId=3526 如下图所示: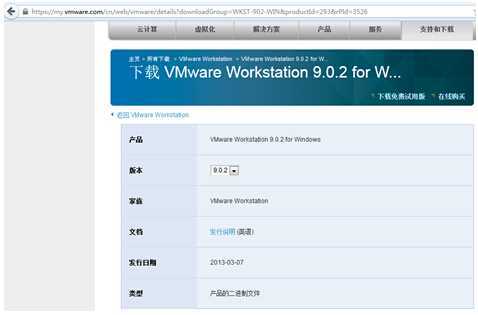
下载后在本地的保存如下图所示:
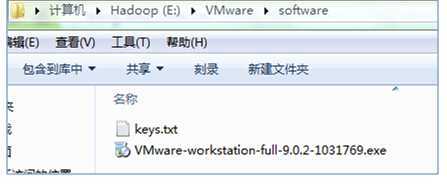
可以看出里面多了一个keys.txt文件,这个是安装Vwware时需要的序列码,读者需要从网络上下载;
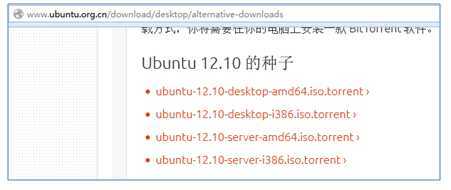
2、Ubuntu的ISO镜像文件,家林这里使用的ubuntu-12.10-desktop-i386,具体下载地址为:http://www.ubuntu.org.cn/download/desktop/alternative-downloads 如下图所示:
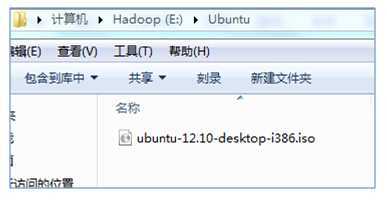
下载后,在本地电脑的保存为:
3、Java SDK的支持,使用的是最新的“jdk-7u60-linux-i586.tar.gz”,具体的下载地址http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html 如下图所示:
点击下载,保存在了Ubuntu系统如下图所示:
4、下载最新稳定版本的Hadoop,下载的是“hadoop-1.1.2-bin.tar.gz ”,具体官方下载地址为http://mirrors.cnnic.cn/apache/hadoop/common/stable/ 下载后在本地的保存为:
Spark教程-构建Spark集群(1),布布扣,bubuko.com
标签:des blog http java 使用 strong
原文地址:http://www.cnblogs.com/spark-china/p/3851565.html