标签:
libSVM是台湾林智仁(Chih-Jen Lin) 教授2001年开发的一套支持向量机库,这套库运算速度挺快,可以很方便的对数据做分类或回归。由于libSVM程序小,运用灵活,输入参数少,并且是开源的,易于扩展,因此成为目前国内应用最多的SVM的库。
(1)Java文件夹 ,主要应用于java平台;
(2)Python文件夹,是用来参数优选的工具,稍后介绍;
(3)tools文件夹,主要包含四个python文件,用来数据集抽样(subset),参数优选(grid),集成测试(easy), 数据查(checkdata);
(4)windows文件夹 —— 包含libSVM四个exe程序包,我们所用的库就是他们,里面还有个heart_scale,是一 个样本文件,测试可用的数据集,可以用 记事本打开,用来测试用的,svm-train用来训练数据的,其中所用的参数的含义:
svm-train [options] training_set_file [model_file]
-s 设置svm类型:
0 – C-SVC ;1 – v-SVC ; 2 – one-class-SVM ; 3 – ε-SVR ; 4 – n - SVR
-t 设置核函数类型,默认值为2
0 -- 线性核:u‘*v ; 1 -- 多项式核: (g*u‘*v+ coef 0)degree
2 -- RBF 核:exp(-γ*||u-v||2) 3 -- sigmoid 核:tanh(γ*u‘*v+ coef 0)
-d degree: 设置多项式核中degree的值,默认为3
-gγ: 设置核函数中γ的值,默认为1/k,k为特征(或者说是属性)数;
-r coef 0:设置核函数中的coef 0,默认值为0;
-c cost:设置C-SVC、ε-SVR、n - SVR中从惩罚系数C,默认值为1;
-n v :设置v-SVC、one-class-SVM 与n - SVR 中参数n ,默认值0.5;
-p ε :设置v-SVR的损失函数中的e ,默认值为0.1;
-m cachesize:设置cache内存大小,以MB为单位,默认值为40;
-e ε :设置终止准则中的可容忍偏差,默认值为0.001;
-h shrinking:是否使用启发式,可选值为0 或1,默认值为1;
-b 概率估计:是否计算SVC或SVR的概率估计,可选值0 或1,默认0;
-wi weight:对各类样本的惩罚系数C加权,默认值为1;
-v n:n折交叉验证模式;
SVM-predict用来预测的,用法如下:
svmpredict [options] test_file model_file output_file
如下使用:

svm-scale是用来对原始样本进行缩放的,范围可以自己定,一般为[0,1]或者[-1,1],防止某个特征过大或者过小,在训练中起的作用不平衡,在核函数计算中会用到内积或者exp运算,不平衡的数据可能造成计算困难,对于其中所用的一些参数汇总如下:
用法:svm-scale [-l lower] [-u upper]
[-y y_lower y_upper]
[-s save_filename]
[-r restore_filename] filename
其中,[]中都是可选项:-l:设定数据下限;lower:设定的数据下限值,缺省为-1 ;-u设定数据上限;upper:设定的数据上限值,缺省为 1;-y:是否对目标值同时进行缩放;y_lower为下限值,y_upper为上限值; -s save_filename:表示将缩放的规则保存为文件save_filename; -r restore_filename:表示将按照已经存在的规则文件restore_filename进行缩放; filename:待缩放的数据文件,文件格式按照libSVM格式。 默认情况下,只需要输入要缩放的文件名就可以了:比如(已经存在的文件为)heart_scale。比如:svmscale –l 0 –u 1 –s
。 svm-toy文件,一个可视化的工具,用来展示训练数据和分类界面,里面是源码,其编译后的程序在windows文件夹下,可以形象化的展示分类页面;
(6)heart_scale文件,是测试用的训练文件,训练集文件
(7)其他.h和.cpp文件都是程序的源码,可以编译出相应的.exe文件。其中,最重要的是svm.h和svm.cpp文件,svm-predict.c、svm-scale.c和svm-train.c(还有一个svm-toy.c在svm-toy文件夹中)都是调用的这个文件中的接口函数,编译后就是windows下相应的四个exe程序。另外,里面的 README 跟 FAQ 是很好的帮助文件。
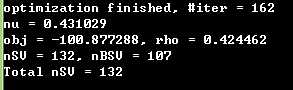
train后得到的结果其中的一些参数iter迭代的次数,nu你选择的核函数类型的参数,obj为SVM文件转换为的二次规划求解得到的最小值,rho为判决函数的偏置项b,nSV 为标准支持向量个数(0<a<c),nBSV为边界上的支持向量个数(a=c),Total nSV为支持向量总个数(对于两类来说,因为只有一个分类模型Total nSV = nSV,但是对于多类,这个是各个分类模型的nSV之和)。
怎样使用tools下的grid文件:
第一步:打开d:/libsvm/program下的tools文件夹,找到grid.py文件。用python打开(不能双击,而要右键选择“Edit with IDLE”),修改svmtrain_exe和gnuplot_exe的路径。
svmtrain_exe = r"I:\code\libsvm-3.20\libsvm-3.20\windows\svm-train.exe‘
gnuplot_exe = r"D:\gnuplot\install\gnuplot\bin\pgnuplot.exe‘
(这里面有一个是对非win32的,可以不用改,只改# example for windows下的就可以了)
第二步:运行cmd,进入dos环境,定位到d:/libsvm/program/tools文件夹,这里是放置grid.py的地方。怎么定位可以参看第一节。
第三步:输入以下命令:
python grid.py heart_scale
你就会看到dos窗口中飞速乱串的[local]数据,以及一个gnuplot的动态绘图窗口。大约过10秒钟,就会停止。Dos窗口中的[local]数据时局部最优值,这个不用管,直接看最后一行:
2048.0 0.0001220703125 84.0741
其中这一行数据的含义是
C = 2048.0;γ=0.0001220703125
交叉验证精度CV Rate = 84.0741%,这就是最优结果
利用上面的结果,进行train得到
语句是:

得到的结果是:
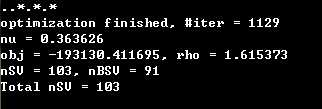
迭代次数1129,支持向量的个数103,边界上的支持向量的个数91,
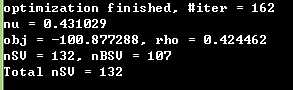
这是优化之前的结果,优化之前的支持向量个数多,边界上的支持向量从107降到了91,说明在优化以前边界向量由10多个错误分类
,
文件easy.py对样本文件做了“一条龙服务”,从参数优选,到文件预测。因此,其对grid.py、svm-train、svm-scale和svm-predict都进行了调用(当然还有必须的python和gnuplot)其余做法和grid.py的做法是类似的,还是要改.exe文件的位置
标签:
原文地址:http://www.cnblogs.com/huicpc0212/p/4883798.html