标签:
理解 OpenStack + Ceph 系列文章:
(1)安装和部署
(3)Ceph 物理和逻辑结构
(4)Ceph 基础数据结构
Kilo 版本中,glance-store 代码被从 glance 代码中分离出来了,地址在 https://github.com/openstack/glance_store。
Glance 中与 Ceph 相关的配置项:
| 配置项 | 含义 | 默认值 |
| rbd_pool | 保存rbd 卷的ceph pool 名称 | images |
| rbd_user | rbd user id,仅仅在使用 cephx 认证时使用 | none。让 librados 根据 ceph 配置文件决定 |
| rbd_ceph_conf | Ceph 配置文件的完整路径 | /etc/ceph/ceph.conf |
| rbd_store_chunk_size | 卷会被分成对象的大小(单位为 MB) | 64 |
class Store(driver.Store) 实现的主要方法:
(1)获取 image 数据:根据传入的Glance image location,获取 image 的 IO Interator
def get(self, location, offset=0, chunk_size=None, context=None):
return (ImageIterator(loc.pool, loc.image, loc.snapshot, self), self.get_size(location))
1. 根据 location,定位到 rbd image
2. 调用 image.read 方法,按照 chunk size 读取 image data
3. 将 image data 返回调用端
(2)获取 image 的 size
def get_size(self, location, context=None): 1. 找到 store location:loc = location.store_location 2. 使用 loc 中指定的 pool 或者配置的默认pool 3. 建立 connection 和 打开 IO Context:with rbd.Image(ioctx, loc.image, snapshot=loc.snapshot) as image 4. 获取 image.stat() 并获取 “size”
(3)添加 image
def add(self, image_id, image_file, image_size, context=None): 1. 将 image_id 作为 rbd image name:image_name = str(image_id) 2. 创建 rbd image:librbd.create(ioctx, image_name, size, order, old_format=False, features=rbd.RBD_FEATURE_LAYERING)。如果 rbd 支持 RBD_FEATURE_LAYERING 的话,创建一个 clonable snapshot:rbd://fsid/pool/image/snapshot;否则,创建一个 rbd image:rbd://image 3. 调用 image.write 方法将 image_file 的内容按照 chunksize 依次写入 rbd image 4. 如果要创建 snapshot 的话,调用 image.create_snap(loc.snapshot) 和 image.protect_snap(loc.snapshot) 创建snapshot
(4)删除 image
def delete(self, location, context=None): 1. 根据 location 计算出 rbd image,snapshot 和 pool 2. 如果它是一个 snapshot (location 是 rbd://fsid/pool/image/snapshot),则 unprotect_snap,再 remove_snap,然后删除 image;这时候有可能出错,比如存在基于该 image 的 volume。 3. 如果它不是一个 snapshot (location 是 rbd://image),直接删除 rbd image。这操作也可能会出错。
root@ceph1:~# rbd info images/71dc76da-774c-411f-a958-1b51816ec50f rbd image ‘71dc76da-774c-411f-a958-1b51816ec50f‘: size 40162 kB in 5 objects order 23 (8192 kB objects) block_name_prefix: rbd_data.103d2246be0e format: 2 features: layering
root@ceph1:~# rbd snap ls images/71dc76da-774c-411f-a958-1b51816ec50f SNAPID NAME SIZE 2 snap 40162 kB
root@ceph1:~# rbd info images/71dc76da-774c-411f-a958-1b51816ec50f@snap
rbd image ‘71dc76da-774c-411f-a958-1b51816ec50f‘:
size 40162 kB in 5 objects
order 23 (8192 kB objects)
block_name_prefix: rbd_data.103d2246be0e
format: 2
features: layering
protected: True
基于该 Glance image 创建的 Cinder volume 都是该 snapshot 的 clone:
root@ceph1:~# rbd children images/71dc76da-774c-411f-a958-1b51816ec50f@snap volumes/volume-65dbaf38-0b9d-4654-bba4-53f12cc906e3 volumes/volume-6868a043-1412-4f6c-917f-bbffb1a8d21a
此时如果试着去删除该 image,则会报错:
The image cannot be deleted because it is in use through the backend store outside of Glance. 这是因为该 image 的 rbd image 的 snapshot 被使用了。
OpenStack Cinder 组件和 Ceph RBD 集成的目的是将 Cinder 卷(volume)保存在 Ceph RBD 中。
| 配置项 | 含义 | 默认值 |
| rbd_pool | 保存rbd 卷的ceph pool 名称 | rbd |
| rbd_user | 访问 RBD 的用户的 ID,仅仅在使用 cephx 认证时使用 | none |
| rbd_ceph_conf | Ceph 配置文件的完整路径 | ‘’,表示使用 librados 的默认ceph 配置文件 |
| rbd_secret_uuid | rbd secret uuid | |
| rbd_flatten_volume_from_snapshot | RBD Snapshot 在底层会快速复制一个元信息表,但不会产生实际的数据拷贝,因此当从 Snapshot 创建新的卷时,用户可能会期望不要依赖原来的 Snapshot,这个选项开启会在创建新卷时对原来的 Snapshot 数据进行拷贝来生成一个不依赖于源 Snapshot 的卷。 | false |
| rbd_max_clone_depth |
卷克隆的最大层数,超过的话则使用 fallter。设为 0 的话,则禁止克隆。 与上面这个选项类似的原因,RBD 在支持 Cinder 的部分 API (如从 Snapshot 创建卷和克隆卷)都会使用 rbd clone 操作,但是由于 RBD 目前对于多级卷依赖的 IO 操作不好,多级依赖卷会有比较严重的性能问题。因此这里设置了一个最大克隆值来避免这个问题,一旦超出这个阀值,新的卷会自动被 flatten。 |
5 |
| rbd_store_chunk_size | 每个 RBD 卷实际上就是由多个对象组成的,因此用户可以指定一个对象的大小来决定对象的数量,默认是 4 MB | 4 |
| rados_connect_timeout | 连接 ceph 集群的超时时间,单位为秒。如果设为负值,则使用默认 librados 中的值 | -1 |
从这里也能看出来,
(1)Cinder 不支持单个 volume 的条带化参数设置,而只是使用了公共配置项 rbd_store_chunk_size 来指定 order。
(2)Cinder 不支持卷被附加到客户机时设置缓存模式。
Cinder 使用的就是之前介绍过的 rbd phthon 模块:
import rados import rbd
它实现了以下主要接口。
def initialize_connection(self, volume, connector):
hosts, ports = self._get_mon_addrs() #调用 args = [‘ceph‘, ‘mon‘, ‘dump‘, ‘--format=json‘] 获取 monmap,再获取 hosts 和 ports
data = {
‘driver_volume_type‘: ‘rbd‘,
‘data‘: {
‘name‘: ‘%s/%s‘ % (self.configuration.rbd_pool, volume[‘name‘]),
‘hosts‘: hosts,
‘ports‘: ports,
‘auth_enabled‘: (self.configuration.rbd_user is not None),
‘auth_username‘: self.configuration.rbd_user,
‘secret_type‘: ‘ceph‘,
‘secret_uuid‘: self.configuration.rbd_secret_uuid, }
}
(2)连接到 ceph rados
client = self.rados.Rados(rados_id=self.configuration.rbd_user, conffile=self.configuration.rbd_ceph_conf)
client.connect(timeout= self.configuration.rados_connect_timeout)
ioctx = client.open_ioctx(pool)
(3)断开连接
ioctx.close()
client.shutdown()
with RADOSClient(self) as client: self.rbd.RBD().create(client.ioctx, encodeutils.safe_encode(volume[‘name‘]), size, order, old_format=old_format, features=features)
#创建克隆卷 def create_cloned_volume(self, volume, src_vref):
# 因为 RBD 的 clone 方法是基于 snapshot 的,所有 cinder 会首先创建一个 snapshot,再创建一个 clone。 if CONF.rbd_max_clone_depth <= 0: #如果设置的 rbd_max_clone_depth 为负数,则做一个完整的 rbd image copy vol.copy(vol.ioctx, dest_name) depth = self._get_clone_depth(client, src_name) #判断 volume 对应的 image 的 clone depth,如果已经达到 CONF.rbd_max_clone_depth,则需要做 flattern src_volume = self.rbd.Image(client.ioctx, src_name) #获取 source volume 对应的 rbd image #如果需要 flattern, _pool, parent, snap = self._get_clone_info(src_volume, src_name) #获取 parent 和 snapshot src_volume.flatten() # 将 parent 的data 拷贝到该 clone 中 parent_volume = self.rbd.Image(client.ioctx, parent) #获取 paraent image parent_volume.unprotect_snap(snap) #将 snap 去保护 parent_volume.remove_snap(snap) #删除 snapshot src_volume.create_snap(clone_snap) #创建新的 snapshot src_volume.protect_snap(clone_snap) #将 snapshot 加保护 self.rbd.RBD().clone(client.ioctx, src_name, clone_snap, client.ioctx, dest_name, features=client.features) #在 snapshot 上做clone self._resize(volume) #如果 clone 的size 和 src volume 的size 不一样,则 resize
| 配置项 | 含义 | 默认值 |
| images_type |
其值可以设为下面几个选项中的一个:
|
default |
| images_rbd_pool | 存放 vm 镜像文件的 RBD pool | rbd |
| images_rbd_ceph_conf | Ceph 配置文件的完整路径 | ‘’ |
| hw_disk_discard |
设置使用或者不使用discard 模式,使用的话需要 Need Libvirt(1.0.6)、 Qemu1.5 (raw format) 和 Qemu1.6(qcow2 format)‘) 的支持 "unmap" : Discard requests("trim" or "unmap") are passed to the filesystem. |
none |
| rbd_user | rbd user ID | |
| rbd_secret_uuid | rbd secret UUID |
要让虚机使用该接口,需要设置 Glance image 的属性:
$ glance image-update --property hw_scsi_model=virtio-scsi --property hw_disk_bus=scsi
(2)在 nova.conf 中配置 hw_disk_discard = unmap
注意目前 cinder 尚不支持 discard。
Nova 在 \nova\virt\libvirt\imagebackend.py 文件中添加了支持 RBD 的新类 class Rbd(Image) 来支持将虚机的image 放在 RBD 中。其主要方法包括:
def create_image(self, prepare_template, base, size, *args, **kwargs): # 调用 ‘rbd‘, ‘import‘ 命令将 image file 的数据保存到 rbd image 中
import [–image-format format-id] [–order bits] [–stripe-unit size-in-B/K/M –stripe-count num] [–image-feature feature-name]... [–image-shared] src-path[image-spec] Creates a new image and imports its data from path (use - for stdin). The import operation will try to create sparse rbd images if possible. For import from stdin, the sparsification unit is the data block size of the destination image (1 << order). The –stripe-unit and –stripe-count arguments are optional, but must be used together.
虚机创建成功后,在 RBD 中查看创建出来的 image:
root@ceph1:~# rbd ls vms 74cbdb41-3789-4eae-b22e-5085de8caba8_disk.local root@ceph1:~# rbd info vms/74cbdb41-3789-4eae-b22e-5085de8caba8_disk.local rbd image ‘74cbdb41-3789-4eae-b22e-5085de8caba8_disk.local‘: size 1024 MB in 256 objects order 22 (4096 kB objects) block_name_prefix: rbd_data.11552ae8944a format: 2 features: layering
查看虚机的 xml 定义文件,能看到虚机的系统盘、临时盘和交换盘的镜像文件都在 RBD 中,而且可以使用特定的 cache 模式(由 CONF.libvirt.disk_cachemodes 配置项指定)和 discard 模式(由 CONF.libvirt.hw_disk_discard 配置项设置):
<devices>
<disk type="network" device="disk">
<driver type="raw" cache="writeback" discard="unmap"/>
<source protocol="rbd" name="vms/74cbdb41-3789-4eae-b22e-5085de8caba8_disk.local">
<host name="9.115.251.194" port="6789"/>
<host name="9.115.251.195" port="6789"/>
<host name="9.115.251.218" port="6789"/>
</source>
<auth username="cinder">
<secret type="ceph" uuid="e21a123a-31f8-425a-86db-7204c33a6161"/>
</auth>
<target bus="virtio" dev="vdb"/>
</disk>
<disk type="network" device="disk">
<driver name="qemu" type="raw" cache="writeback"/>
<source protocol="rbd" name="volumes/volume-6868a043-1412-4f6c-917f-bbffb1a8d21a">
<host name="9.115.251.194" port="6789"/>
<host name="9.115.251.195" port="6789"/>
<host name="9.115.251.218" port="6789"/>
</source>
<auth username="cinder">
<secret type="ceph" uuid="e21a123a-31f8-425a-86db-7204c33a6161"/>
</auth>
<target bus="virtio" dev="vda"/>
<serial>6868a043-1412-4f6c-917f-bbffb1a8d21a</serial>
</disk>
关于 libvirt.disk_cachemodes 配置项,可以指定镜像文件的缓存模式,其值的格式为 ”A=B",其中:
上面的虚机 XML 定义文件是在Nova 配置为 disk_cachemodes="network=writeback" 和 hw_disk_discard = unmap 的情形下生成的。
(2)image clone API
def clone(self, context, image_id_or_uri): 1. 通过 Glance API 获取 image 的 rbd location 2. 检查 rbd image 是否可以被克隆(检查它是不是在本 ceph cluster 内、是不是 raw 格式、是不是可以访问等) 3. 调用 rbd 的 clone 方法来创建 clone
使用传统存储作为 image 的后端存储时,在创建虚机的过程中的创建镜像文件时,都是调用 _try_fetch_image_cache 方法来从 Glance 中将镜像文件下载到本地(第一次会缓存,以后就直接读缓存而不用下载),然后再创建镜像文件的方法。而在使用 RBD 作为镜像的后端存储时,如果 Glance 镜像文件被保存在 RBD 中,那么该过程将是重复的(先通过 Glance 从 RDB 中倒出镜像,然后再由 Nova 放到RBD中),而且是非常耗时的。针对这种情况,Nova 实现了一种新的办法,具体见下面的蓝色字体部分:
def _create_image(self, context, instance, disk_mapping, suffix=‘‘, disk_images=None, network_info=None, block_device_info=None, files=None, admin_pass=None, inject_files=True, fallback_from_host=None): if not booted_from_volume: #如果不是从 volume 启动虚机 root_fname = imagecache.get_cache_fname(disk_images, ‘image_id‘) size = instance.root_gb * units.Gi backend = image(‘disk‘) if backend.SUPPORTS_CLONE: #如果 image backend 支持 clone 的话(目前的各种 image backend,只有 RBD 支持 clone) def clone_fallback_to_fetch(*args, **kwargs): backend.clone(context, disk_images[‘image_id‘]) #直接调用 backend 的 clone 函数做 image clone fetch_func = clone_fallback_to_fetch else: fetch_func = libvirt_utils.fetch_image #否则走常规的 image 下载-导入过程 self._try_fetch_image_cache(backend, fetch_func, context, root_fname, disk_images[‘image_id‘], instance, size, fallback_from_host)
可见,当 nova 后端使用 ceph 时,nova driver 调用 RBD imagebackend 命令,直接在 ceph 存储层完成镜像拷贝动作(无需消耗太多的nova性能,也无需将镜像下载到hypervisor本地,再上传镜像到ceph),如此创建虚拟机时间将会大大提升。当然,这个的前提是 image 也是保存在 ceph 中,而且 image 的格式为 raw,否则 clone 过程会报错。 具体过程如下:
(1)这是 Glance image 对应的 rbd image:
root@ceph1:~# rbd info images/0a64fa67-3e34-42e7-b7b0-423c11850e18 rbd image ‘0a64fa67-3e34-42e7-b7b0-423c11850e18‘: size 564 MB in 71 objects order 23 (8192 kB objects) block_name_prefix: rbd_data.16d21e1d755b format: 2 features: layering
(2)使用该 image 创建第一个虚机
root@ceph1:~# rbd info vms/982b8eac-6bcc-4a21-bd04-b67e26188be0_disk rbd image ‘982b8eac-6bcc-4a21-bd04-b67e26188be0_disk‘: size 3072 MB in 384 objects order 23 (8192 kB objects) block_name_prefix: rbd_data.130a36a6b435 format: 2 features: layering parent: images/0a64fa67-3e34-42e7-b7b0-423c11850e18@snap overlap: 564 MB root@ceph1:~# rbd info vms/982b8eac-6bcc-4a21-bd04-b67e26188be0_disk.local rbd image ‘982b8eac-6bcc-4a21-bd04-b67e26188be0_disk.local‘: size 2048 MB in 512 objects order 22 (4096 kB objects) block_name_prefix: rbd_data.a69b2ae8944a format: 2 features: layering root@ceph1:~# rbd info vms/982b8eac-6bcc-4a21-bd04-b67e26188be0_disk.swap rbd image ‘982b8eac-6bcc-4a21-bd04-b67e26188be0_disk.swap‘: size 102400 kB in 25 objects order 22 (4096 kB objects) block_name_prefix: rbd_data.a69e74b0dc51 format: 2 features: layering
(3)创建第二个虚机
root@ceph1:~# rbd info vms/a9670d9a-8aa7-49ba-baf5-9d7a450172f3_disk rbd image ‘a9670d9a-8aa7-49ba-baf5-9d7a450172f3_disk‘: size 3072 MB in 384 objects order 23 (8192 kB objects) block_name_prefix: rbd_data.13611f6abac6 format: 2 features: layering parent: images/0a64fa67-3e34-42e7-b7b0-423c11850e18@snap overlap: 564 MB
(4)会看到 Glance image 对应的 RBD image 有两个克隆,分别是上面虚机的系统盘
root@ceph1:~# rbd children images/0a64fa67-3e34-42e7-b7b0-423c11850e18@snap vms/982b8eac-6bcc-4a21-bd04-b67e26188be0_disk vms/a9670d9a-8aa7-49ba-baf5-9d7a450172f3_disk
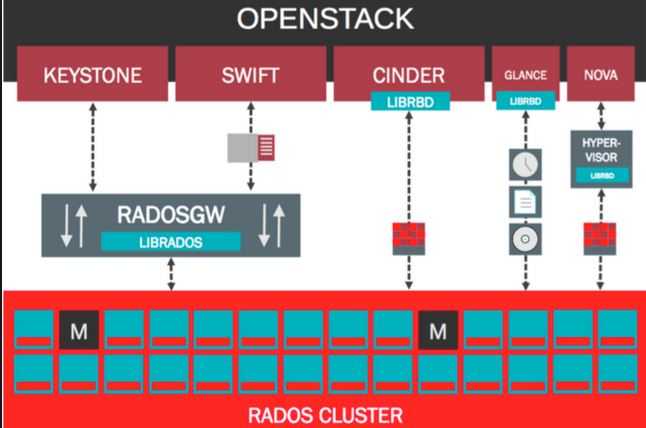
除了上面所描述的 Cinder、Nova 和 Glance 与 Ceph RBD 的集成外,OpenStack 和 Ceph 之间还有其它的集成点:
(1)使用 Ceph 替代 Swift 作为对象存储 (网络上有很多比较 Ceph 和 Swift 的文章,比如 1,2,3,)
(2)CephFS 作为 Manila 的后端(backend)
(3)Keystone 和 Ceph Object Gateway 的集成,具体可以参考文章 (1)(2)
参考文档:
http://www.sebastien-han.fr/blog/2015/02/02/openstack-and-ceph-rbd-discard/
理解 OpenStack + Ceph (5):OpenStack 与 Ceph 之间的集成 [OpenStack Integration with Ceph]
标签:
原文地址:http://www.cnblogs.com/sammyliu/p/4838138.html