标签:
特征提取:
在深度学习中,下层携带的信息量会大于上层的信息量。最下层被认为是基。譬如高维空间中,总有一组完备基。任何一个向量都可以通过完备基线性表示。这是,经过多层表示,后面的各个向量组成的矩阵的秩小于等于其下一层个向量组成矩阵的秩当然,我们这里一开始引入时,也认为任何一幅图可以表示为400张图的线性组合。
但实际深度学习中的层还有一些激活函数,它们是非线性的。如果是这样,紫色部分应改为“任何一层S和第一层的互信息小于等于S下一层与第一层的信息”。注意,这里一定都是和第一层的互信息。因为由于每层除了削减的一些信息外,还可能额外增加了一些其他信息,这部分额外的信息可能会传递给下一层。这样导致,如果只用任何相邻的互信息来比较,就会出现很大的问题。

浅层学习:
20世纪80年代末,神经网络就开始出现。不过,此时的神经网络就只是多了一层隐藏层。
20世纪90年代,各种可以视为浅层网络相继出现:SVM,Boosting,最大熵方法。此时,浅层的神经网络又是陷入了沉寂。
2006,Geoffrey Hinton和他的学生RuslanSalakhutdinov发表在《科学》上一篇文章,开启了深度学习热潮。其主要思想:
1)多隐层的人工神经网络具有优异的特征学习能力,学习得到的特征对数据有更本质的刻画,从而有利于可视化或分类;
2)深度神经网络在训练上的难度,可以通过“逐层初始化”(layer-wise pre-training)来有效克服,在这篇文章中,逐层初始化是通过无监督学习实现的。
缺点:
1)难以表达复杂分类映射,感觉欠拟合,泛化能力低。(当然深度学习过拟合时,泛化能力也会低,当时可控)
深度学习:
为了解决浅层学习由于欠拟合造成的泛化能力低,自然想着复杂的映射。什么样的复杂?仅仅选择一个初等函数远远不够。选几个初等函数的组合,怎么样?怎么组合法?线性相加?一个作为另一个的指数?有这样的考虑,比如:
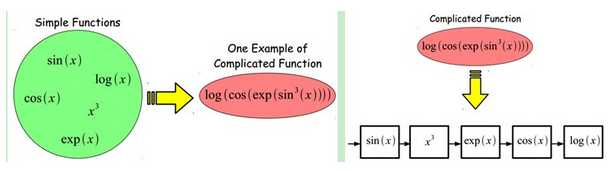
实际上,我们会有一种经典的映射,已经实验得到了不错的效果。
优点:
区别于传统的浅层学习,深度学习的不同在于:1)强调了模型结构的深度,通常有5层、6层,甚至10多层的隐层节点;2)明确突出了特征学习的重要性,也就是说,通过逐层特征变换,将样本在原空间的特征表示变换到一个新特征空间,从而使分类或预测更加容易。与人工规则构造特征的方法相比,利用大数据来学习特征,更能够刻画数据的丰富内在信息。
标签:
原文地址:http://www.cnblogs.com/Wanggcong/p/4888167.html