标签:
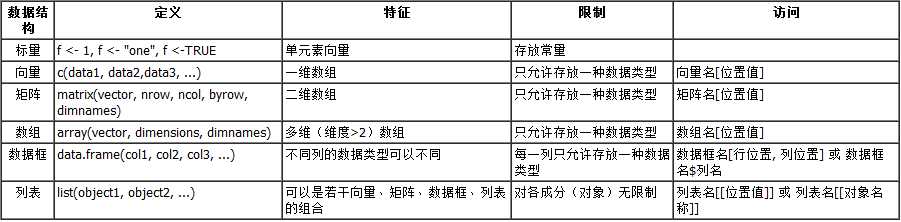
两种常用的数据结构示例(R version 3.2.2):
Vertor 向量
c函数语法:c(data1, data2,data3, ...)
> c(1,2,3,4,5,6)
[1] 1 2 3 4 5 6 # 开始的[1]代表随后输出的1在向量中的位置是第1位
> c(TRUE,FALSE) # 逻辑型变量注意是大写TRUE和FALSE
[1] TRUE FALSE
> c("a","b","c") # 字符型变量使用单引号或双引号括起来都可,但输出时都是双引号
[1] "a" "b" "c"
> c(1,2,TRUE) # 逻辑型变量TRUE被转换成数值1
[1] 1 2 1
> c(1,2,FALSE) # 逻辑型变量FALSE被转换成数值0
[1] 1 2 0
> C("A","B",TRUE) # 逻辑型变量和字符型变量不能混用
Error in C("A", "B", TRUE) : 不能把对象解释成因子
> c(1,2,"A")
[1] "1" "2" "A" # 数值型变量1,2被转换成字符型“1”,“2”
向量的访问:Val[index]
> x <- c(2,5,7,9,10)
> x[2] # 向量的位置从1开始
[1] 5
> x[2:5] # 使用冒号可访问从2到5位置上的数据
[1] 5 7 9 10
> x[6] # 如果位置置超过向量总长度,则只能返回NA
[1] NA # NA 即 NotAvailable,表示这个位置上没有数据,不可用
Frame 数据框
data.frame函数语法:data.frame(向量1, 向量2, 向量3, ..., 向量n)
> name <- c("Amy", "Jean", "July")
> age <- c(20, 21, 22)
> f <- data.frame(name, age) # 向量作为数据框中的列
> f
name age # 向量的变量名作为数据框的列名
1 Amy 20
2 Jean 21
3 July 22
数据框的访问:数据框的变量名[行位置, 列位置]
> f
name age
1 Amy 20
2 Jean 21
3 July 22
> f[1,2] # 同时输入行位置和列位置,返回对应行列位置上的值
[1] 20
> f[1,] # 只是输入行位置,返回对应行位置上的所有值
name age
1 Amy 20
> f[,1] # 只是输入列位置,返回对应列位置上的所有值
[1] Amy Jean July
Levels: Amy Jean July
可视化编辑工具:fix(dataFrame)
通过fix(f),调用出数据编辑器,将Amy修改为Dany,如下,

可见数据框中的Amy确实被修改成了Dany,

当然,利用f <- data.frame()生成一个空的数据框,再通过fix(f)在数据编辑器中直接编辑行列变量也是可以的。
标签:
原文地址:http://www.cnblogs.com/janedu/p/4899090.html