标签:
今天介绍基于密度的异常点检测,我们以LOF算法为例。先看下图



C1和C2为两个cluster,cluster里面的密度都很高,只是不同cluster里点的距离不太一样。b相对于C1为一个局部( local )的outlier。a为一个整体( global )的outlier。所以这里的outlier检测,并非是基于distance或者基于近邻的。而是比较点和点的密度的差距。如果某个点和周围点比起来密度明显小,则该点很可能是outlier!
问题是如何定义密度?为了引出密度的概念。这里我们来介绍 reachability distance。这个距离的定义是这样的:
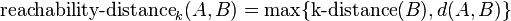
这个距离有一个方向性A-->B。它取的是B的K近邻的距离以及A和B距离之间的最大值。所以reachability distance( A, B ), reachability distance( B, A ) 很可能不相等。因为A和B的k近邻距离很可能不一样. 这里又有一个k-distance。它就是每个点的k近邻点的最大值。我们先来解决这个函数:
import numpy as np import scipy.spatial.distance as ssd from sklearn.neighbors import NearestNeighbors def kDistances( X, k = 5 ): n = X.shape[0] k = min( k, n - 1 ) nbhrInfos = range( n ) kNN = NearestNeighbors( metric = ssd.euclidean ).fit( X ) kDists = np.zeros( n, dtype = np.float ) for i in range(n): # Max k nearest neighbor distance dist, _ = kNN.kneighbors( X[ i ], n_neighbors = k + 1 ) kDists[ i ] = dist[ 0 ][ -1 ] # The set of k nearest neighbors as Nk(A) and distances. dists, neighbors = kNN.radius_neighbors( X[ i ], radius = kDists[ i ] ) mask = neighbors[ 0 ] != i # exclude self from k nearest neighbor nbhrInfos[ i ] = [ neighbors[ 0 ][ mask ], dists[ 0 ][ mask ] ] return kDists, nbhrInfos
这里,我们不仅仅计算了每个点的K-Distances距离,我们还计算了每个点在其K-Distances半径内的点以及其距离( 去除了每个点自身)。这就会后续计算reachability Distance做好了准备。接着就是计算reachability Distance的代码:
def reachabilityDistance( A, B, kDistB, dist = None ): if dist is None: dist = ssd.euclidean( A, B ) return max( kDistB, dist )
我们用图片来解释下reachability Distance的意义:

对于点A来说,它的3个近邻的k-Distance就是点A到点B的距离。也就是以A为圆心,AB为半径的一个圆。那D到A的reachability Distance( D, A )是多少呢。注意这里说得是D到A,有方向性!因为AD之间的距离,大于A的k-distance( k = 3 )。所以reachability Distance( D, A ) = AD之间的距离。
由这个定义我们再来看一张图:

A点到它的3个近邻的reachability Distance用红色标出。而大弧线虚线是A的k-Distance。小的弧线虚线是A近邻的k-distance的距离。这里很明显,如果一个点是outlier,那么它到近邻的reachability Distance会远远超出其近邻到各自近邻的reachability Distance。这里是有点绕的。不过reachability Distance是一个很重要的度量标志我们是明确了。我们实现这种度量后,就会明白LOF会怎么使用它。作者用了每个点到其所有Nk-distance近邻的 reachability Distance总和。然后取倒数并乘以Nk-distance近邻的数量。作者称之为 local reachability density。它的意义是单位可达距离里包含的近邻数。包含的越多,说明密度越高。公式如下:

代码如下,这里我们的函数是针对一个样本点来定义的。这样更加接近文献中的定义。
def lrd( i, X, kDists, nbhrInfos ): A = X[ i ] kNeighborsOfA, kNNDistsOfA = nbhrInfos[ i ] sumOfReachabilityDistances = 0. # A and its NA neighbors reachbility distances for j in range( len( kNeighborsOfA ) ): B = X[ kNeighborsOfA[ j ] ] kDistB = kDists[ kNeighborsOfA[ j ] ] distAB = kNNDistsOfA[ j ] reachDistance = reachabilityDistance( A, B, kDistB, distAB ) sumOfReachabilityDistances += reachDistance # A‘s density lrd = len( kNeighborsOfA ) / sumOfReachabilityDistances return lrd
这里利用前面kDistances获取的近邻信息可以计算出每个点的lrd。一般离群点的lrd较其近邻的lrd明显会小。所以利用lrd,作者构造出一个Outlier的离群度分数LOF。公式如下:

公式体现了作者的意图。作者就是用A点近邻的平均lrd值去和lrdA作比较。因为如果A是outlier的话,其lrd会很小,导致分数会明显的高!而作者也证明了一般密集的点,其LOF得分会往1收敛。得分越小密度越高。当然这里的LOF分数的设置也是经验性的,而这也是LOF的缺陷。分数不是那么统一和容易确认。下面是代码:
def calLOF( i, X, kDists, nbhrInfos, lrdCache = None ): A = X[i] kNeighborsOfA, _ = nbhrInfos[ i ] if lrdCache is None : lrdCache = {} if i not in lrdCache: lrdCache[ i ] = lrd( i, X, kDists, nbhrInfos ) lrdA = lrdCache[ i ] # A‘s neighbors densities sumOfNeighborsLrd = 0. for j in kNeighborsOfA: # print i, j if j not in lrdCache: lrdCache[ j ] = lrd( j, X, kDists, nbhrInfos ) lrdB = lrdCache[ j ] sumOfNeighborsLrd += lrdB # A‘s neighbors average density and A‘s density ---> LOF LOF = sumOfNeighborsLrd / ( len( kNeighborsOfA ) * lrdA ) return LOF
最后我们把代码整合到一个函数里去,这个函数需要指定2个参数: minPts就是LOF去看的近邻数, lofSpec是LOF得分超过多少算是outlier。
def detectOutliers( X, minPts = 5, lofSpec = 3 ): n = X.shape[ 0 ] kDists, nbhrInfos = kDistances( X, minPts ) lrdCache = {} lofs = np.array( [ calLOF( i, X, kDists, nbhrInfos, lrdCache ) for i in xrange( n ) ] ) labels = np.array( lofs >= lofSpec, dtype = np.int ) return labels, lofs
我们看下测试的结果:

这三个点的LOF分数分别是4.09888044, 11.33202877, 15.17396308.
标签:
原文地址:http://www.cnblogs.com/zhuyubei/p/4898388.html