三、基于Storm和Kafka的车辆信息实时监控系统打造
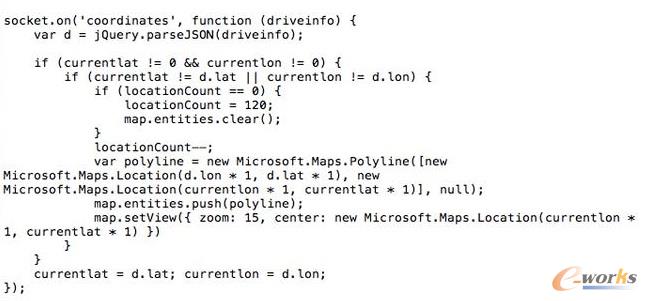
接下来做的就是将车辆信息实时监控系统部署到系统中。这个系统演示了如何编写一个Storm的Topology,从Kafka消息系统中将信息读取出 来。我们使用Kafka的客户端模拟从世界各地发送车辆实时信息给Kafka集群,然后Storm Topology会把这些消息通过Bolts将坐标转换为Json对象,并且使用GeoJSON在Bing Map上显示车辆的实时位置、温度、转速以及速度等等信息。Topology还会将信息写到Redis缓存中,然后Node.js通过socket.io 读取Redis中的信息,并且使用d3js显示在页面上。
首先,我们需要编写Kafka 生产者的部分代码,主要是模拟读取汽车的实时数据并向Kafka集群进行发送,我们实现了一个KafkaCarDataProducer类,通过配置 ProducerConfig来创建一个Producer对象来发送数据。它可以用来连接到Zookeeper,或者直接是Kafka 代理。例如:kafkaclient.cloudapp.net:2181或者0:kafkaclient.cloudapp.net:9092。代码中 我们根据不同的连接字符串设置不同配置。伪代码如下:
然后就可以直接通过下面代码来发送消息:
接下来我们需要编写3个Storm类,首先是创建Storm的Topology,这个类叫KafkaCarTopology,我们创建了一个叫car 的topic,然后定义本机一个hosts和Zookeeper hosts,最后创建一个Spout,叫做KafkaSpout,然后添加ParseCarDataBolt连接到KafkaSout,再创建一个 RedisCarBolt,用于将结果写入Redis缓存。最后根据参数创建3个Worker,提交Storm Topology。
在这个拓扑结构中,我们有2个Bolt用于数据的处理,第一个叫ParserCarDataBolt,这个Bolt主要将Kafka传出的消息转换为 Json格式,它继承BaseBasicBolt,在execute函数中通过collector提交数据,同时重载了 declareOutputFields函数,通知下一个Bolt的数据格式。代码如下:
数据会被写入RedisCarBolt,再写入到Redis缓存中。它继承自BaseRichBolt,需要重载prepare和excute方法来处理消息元组。此外还需要重载prepare和cleanup函数,几个关键的函数如下:
最后我们还需要编写一些Node.js的代码,保证在页面上通过socket.io进行通讯,实时将最终数据从Redis里面读取出来,并在BingMap上显示。
到此为止,一个简单的车辆信息实时监控系统就实现了,我们通过bash脚本进行编译,并安装到相应的服务器上,比如下列代码需要被安装在Storm的服务器上:
有一点需要注意的是,由于在编译过程中需要自动下载Storm库,在阿里云的国内机房的虚拟机很有可能需要设置代理进行。设置代理的方法也很简单,通过对lein命令增加以下参数就可以了:http_proxy=http://URL:PORT
接着我们在网页上访问http://webhostname或者运行node.js的服务器,就会看到下面的网页,同时发现网页将同步刷新汽车的实时位置、速度、转速等。
图6 车联网监控系统演示页面
四、对车联网监控系统的性能测试
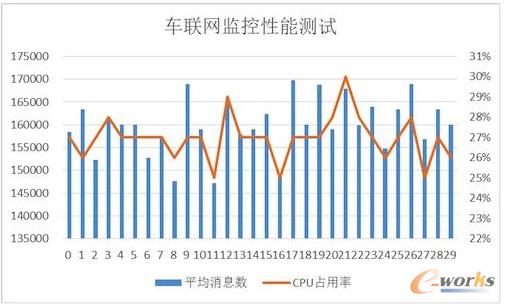
接下来我们对这个系统进行了一个简单的吞吐量测试。我们只有1个Topic,使用5个partition、3个worker、1个Spout和2个 Bolt,在一台2核2GB的ECS上运行。我们使用了另外4台客户端,每个客户端有4核8G内存,分别启动40个线程不断向这个系统实时发送汽车信息, 模拟160台汽车发送的情况,其消息发送数量和CPU占用率情况如图7所示。
图7 车联网监控系统性能分析
从图7中可以看出,平均每辆汽车客户端会模拟每秒给系统发送了1000条消息,总的吞吐量达到16万条左右,此时平均的CPU占用率大约在30%左 右。如果系统是完全线性的,在系统CPU占用率达到90%的情况下,大约能处理48万条消息。不过实际情况中,在阿里云ECS上,却发现CPU达到50% 以后,就不再上升,而客户端发送消息的延时也逐步增加。
经过分析以后发现,由于ECS的磁盘性能无法和物理机的SSD磁盘相比,所以在Kafka消息大量写入磁盘的过程中,吞吐量下降,磁盘读写负担变得非 常大。这时我们增加了Kafka的Broker和Storm的Spout的数量,将消息分布式地分发到多台ECS上,从而实现了消息吞吐量的线性增加。
在这个系统中,我们不推荐使用大核和大内存的机器,而推荐使用多台2核2GB的服务器分布式地处理消息。这也是云计算处理大数据的原则所在,使用横向扩展而不用纵向扩展。
五、结论
至此我们介绍了利用Storm和Kafka实现大数据的实时处理,并且介绍了如何在云上通过镜像快速地创建这套系统。此外,我们还介绍了如何对 Storm、Kafka、Redis以及Node.js开发出一个实时的车辆信息监控系统。这个系统能够实现高性能、大吞吐量和高并发。当然,随着大数据 的快速发展,我们相信还会有越来越多好的工具和产品出现在市场上,到那时我们从大数据中获取有效的信息将会变得更加容易和便捷。有了云计算的帮助,开发的 周期也会变得越来越短。
原文:http://articles.e-works.net.cn/infrastructure/Article120178_1.htm