标签:
http://www.ibm.com/developerworks/cn/data/library/techarticle/dm-1107yangy/
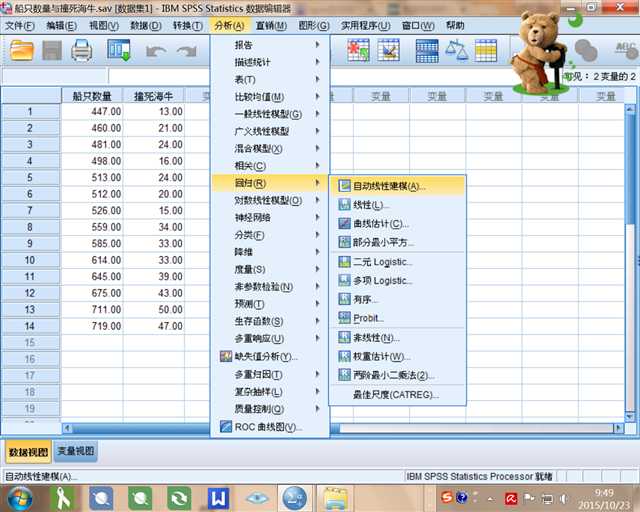
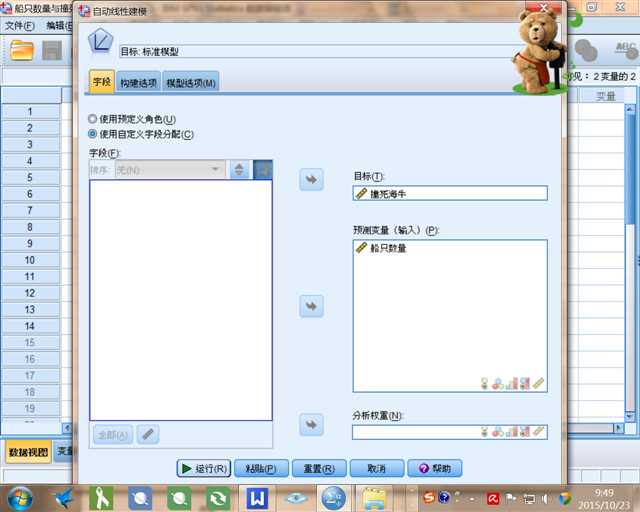
一般用户经常会被统计分析软件中的复杂的参数设置而头疼,即使知道了选择合适的模型,也不知道该如何调整参数来进行使用,针对于此,IBM SPSS Statistics 19 加入了一个新的功能:自动化线性建模,这是对最经常使用的线性模型加以改进,让用户输入最少的参数而自动进行建立线性模型的功能,选择菜单:分析 -> 回归 -> 自动线性建模,在目标栏中设置当前薪金变量作为模型的目标预测变量,如果对剩余变量不能确定哪些变量与当前薪金变量有关系,可以全部选为输入预测变量,自动化线性建模会自动选择合适的预测变量来作为线性模型的输入变量,如图 11,单击运行按钮来产生线性模型。


结果报告分析
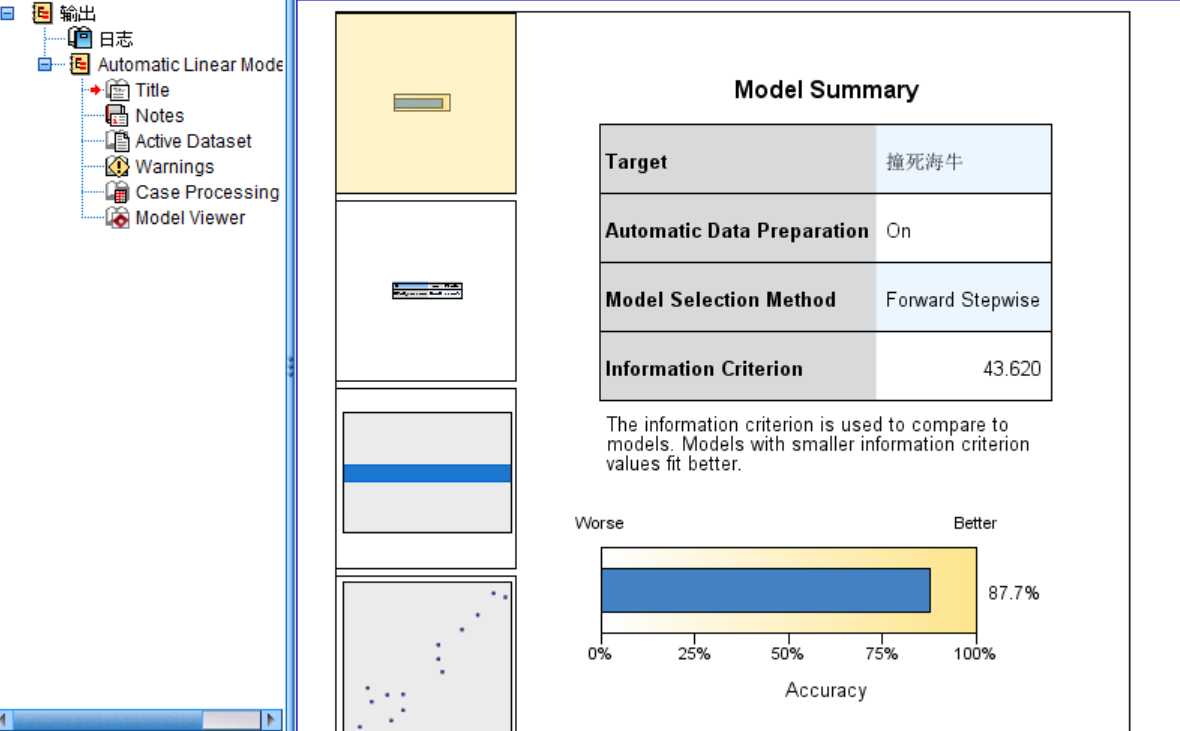
在 IBM SPSS Statistics 的输出查看器中,双击产生的线性模型就可以打开一个模型浏览器来具体观察分析这个线性模型的情况。从图 12 模型概要页中可以看出,产生的线性模型的预测准确度达到了 80.3%,说明这个模型的预测准确度还是比较高的。

在如图 13 的预测变量重要性页面中可以看到,起始薪金与当前薪金的关系最为密切,重要性也最高,接下来重要的是雇佣类别,而最不重要的是出生日期,可以看出,这与人们的一般经验也是相符合的。

残差是指预测出来的值与实际值之间的差距,在图 14 中描述的残差页面,可以看到,该预测模型的残差直方图比较好的接近与正态分布曲线图,而线性模型的残差就是基于正态分布模型的假设,通过此页面也可以看出前面在离散图进行预分析得出的结论是正确的,可以用线性模型较好的来进行当前薪金的预测。

模型预测应用
通过之前的步骤已经产生了一个线性模型来预测当前薪金的值,如果需要将这个模型保存出来以便对今后的数据进行预测应用,可以在模型浏览器中,选择:文件 -> 导出 PMML,将该模型导出为一个名为:预测当前薪金的线性模型 .zip 的文件,如果解压该文件可以看到一个 xml 文件,该文件是符合 PMML 全称预测模型标记语言(Predictive Model Markup Language)规范的,可以将它用于任何支持 PMML 模型的程序当中。
在 IBM SPSS Statistics 当中,同样提供了模型预测应用的功能,选择菜单:实用程序 -> 评分向导,如图 15,选择刚才导出的“预测当前薪金的线性模型 .zip”文件作为评分模型,在模型详细信息中可以看到模型的一些基本信息,包括产生的应用程序,目标变量,预测输入变量,模型类型等,单击下一步按钮,进入模型变量匹配页面。

当变量名相同时,IBM SPSS Statistics 会自动匹配模型中用到的预测输入变量和当前数据集中已有的变量,如图 16,如果需要改变数据集中的字段可以在这里进行设置,通常一个模型是适用于特定数据集的,因此最好使用数据集中相同的字段作为模型应用的变量。单击下一步,进入评分函数选择页面。

因为线性模型只有预测值函数可以选择,因此这里只有一个选项如图 17,对于其他模型,如最近邻元素分类模型,神经网络模型等会有多个函数可供选择,单击完成。

如图 18,在结果数据集中会产生一个新的变量 PredictedValue,这个变量的值就是应用之前产生的线性模型在已有数据集后产生的预测当前薪金的结果变量,该公司今后可以根据该模型和方法来进行人员成本估计和控制,以及新员工薪资定位等问题。

本文从 IBM SPSS Statistics 的基本概念开始入手,通过实例应用分析,结合自动线性建模的应用,将 IBM SPSS Statistics 用于数据预测统计分析的基本流程做了简单介绍,实际当中每个步骤可能不会全部使用,也可能会有各个阶段交叉进行,比如在第一次得到模型后,根据模型信息,可以重新进行数据准备,调整参数后建模,或者选择其他模型,从而选择到最适合用户应用场景的模型。本文所展示的只是 IBM SPSS Statistics 很基础的一部分使用。随着用户使用的加深,将会了解到 IBM SPSS Statistics 更为强大的功能,如 ADP(自动数据准备),GLMM(广义线性混合模型),神经网络模型等等。
标签:
原文地址:http://www.cnblogs.com/biopy/p/4903535.html