标签:
文章内容非常干货,非常值得学习。文章将以四部分进行阐述,建议大家耐心看完。第一部分:Log是什么?
第二部分:数据集成
第三部分:日志和实时流处理
第四部分:系统建设
我在六年前的一个令人兴奋的时刻加入到LinkedIn公司。从那个时候开始我们就破解单一的、集中式数据库的限制,并且启动到特殊的分布式系统套件 的转换。这是一件令人兴奋的事情:我们构建、部署,而且直到今天仍然在运行的分布式图形数据库、分布式搜索后端、Hadoop安装以及第一代和第二代键值 数据存储。
从这一切里我们体会到的最有益的事情是我们构建的许多东西的核心里都包含一个简单的理念:日志。有时候也称作预先写入日志或者提交日志或者事务日志,日志几乎在计算机产生的时候就存在,同时它还是许多分布式数据系统和实时应用结构的核心。
不懂得日志,你就不可能完全懂得数据库,NoSQL存储,键值存储,复制,paxos,Hadoop,版本控制以及几乎所有的软件系统;然而大多数软 件工程师对它们不是很熟悉。我愿意改变这种现状。在这篇博客文章里,我将带你浏览你必须了解的有关日志的所有的东西,包括日志是什么,如何在数据集成、实 时处理和系统构建中使用日志等。
第一部分:日志是什么?
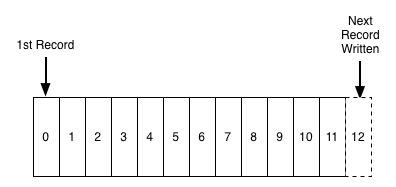
日志是一种简单的不能再简单的存储抽象。它是一个只能增加的,完全按照时间排序的一系列记录。日志看起来如下:
我们可以给日志的末尾添加记录,并且可以从左到右读取日志记录。每一条记录都指定了一个唯一的有一定顺序的日志记录编号。
日志记录的排序是由“时间”来确定的,这是因为位于左边的日志记录比位于右边的要早些。日志记录编号可以看作是这条日志 记录的“时间戳”。在一开始就把这种排序说成是按时间排序显得有点多余 ,不过 ,与任何一个具体的物理时钟相比,时间 属性是非常便于使用的属性。在我们运行多个分布式系统的时候,这个属性就显得非常重要。
对于这篇讨论的目标而言,日志记录的内容和格式不怎么重要。另外提醒一下,在完全耗尽存储空间的情况下,我们不可能 再给日志添加记录。稍后我们将会提到这个问题。
日志并不是完全不同于文件或者数据表的。文件是由一系列字节组成,表是由一系列记录组成,而日志实际上只是按照时间顺序存储记录的 一种数据表或者文件。
此时,你可能奇怪为什么要讨论这么简单的事情呢? 不同环境下的一个只可增加的有一定顺序的日志记录是怎样与数据系统关联起来的呢?答案是日志有其特定的应用目标:它记录了什么时间发生了什么事情。 而对分布式数据系统许多方面而言, 这才是问题的真正核心。
不过,在我们进行更加深入的讨论之前,让我先澄清有些让人混淆的概念。每个编程人员都熟悉另一种日志记录-应用使用syslog或者log4j可能写 入到本地文件里的没有结构的错误信息或者追踪信息。为了区分开来,我们把这种情形的日志记录称为“应用日志记录”。应用日志记录是我在这儿所说的日志的一 种低级的变种。最大的区别是:文本日志意味着主要用来方便人们阅读,而我所说明的“日志”或者“数据日志”的建立是方便程序访问。
(实际上,如果你对它进行深入的思考,那么人们读取某个机器上的日志这种理念有些不顺应时代潮流。当涉及到许多服务和服务器的时候,这种方法很快就变 成一个难于管理的方式,而且为了认识多个机器的行为,日志的目标很快就变成查询和图形化这些行为的输入了-对多个机器的某些行为而言,文件里的英文形式的 文本同这儿所描述的这种结构化的日志相比几乎就不适合了。)
数据库日志
我不知道日志概念起源于何处-可能它就像二进制搜索一样:发明者认为它太简单而不能当作一项发明。它早在IBM的系统R出现时候就出现了。数据库里的 用法是在崩溃的时候用它来同步各种数据结构和索引。为了保证操作的原子性和持久性,在对数据库维护的所有各种数据结构做更改之前,数据库把即将修改的信息 誊写到日志里。日志记录了发生了什么,而且其中的每个表或者索引都是一些数据结构或者索引的历史映射。由于日志是即刻永久化的,可以把它当作崩溃发生时用 来恢复其他所有永久性结构的可信赖数据源。
随着时间的推移,日志的用途从实现ACID细节成长为数据库间复制数据的一种方法。利用日志的结果就是发生在数据库上的更改顺序与远端复制数据库上的更改顺序需要保持完全同步。
Oracle,MySQL 和PostgreSQL都包括用于给备用的复制数据库传输日志的日志传输协议。Oracle还把日志产品化为一个通用的数据订阅机制,这样非Oracle 数据订阅用户就可以使用XStreams和GoldenGate订阅数据了,MySQL和PostgreSQL上的类似的实现则成为许多数据结构的关键组 件。
正是由于这样的起源,机器可识别的日志的概念大部分都被局限在数据库内部。日志用做数据订阅的机制似乎是偶然出现的,不过要把这种 抽象用于支持所有类型的消息传输、数据流和实时数据处理是不切实际的。
分布式系统日志
日志解决了两个问题:更改动作的排序和数据的分发,这两个问题在分布式数据系统里显得尤为重要。协商出一致的更改动作的顺序(或者说保持各个子系统本身的做法,但可以进行存在副作用的数据拷贝)是分布式系统设计的核心问题之一。
以日志为中心实现分布式系统是受到了一个简单的经验常识的启发,我把这个经验常识称为状态机复制原理:如果两个相同的、确定性的进程从同一状态开始,并且以相同的顺序获得相同的输入,那么这两个进程将会生成相同的输出,并且结束在相同的状态。
这也许有点难以理解,让我们更加深入的探讨,弄懂它的真正含义。
确定性意味着处理过程是与时间无关的,而且任何其他“外部的“输入不会影响到处理结果。例如,如果一个程序的输出会受到线程执行的具体顺序影响,或者 受到gettimeofday调用、或者其他一些非重复性事件的影响,那么这样的程序一般最有可能被认为是非确定性的。
进程状态是进程保存在机器上的任何数据,在进程处理结束的时候,这些数据要么保存在内存里,要么保存在磁盘上。
以相同的顺序获得相同输入的地方应当引起注意-这就是引入日志的地方。这儿有一个重要的常识:如果给两段确定性代码相同的日志输入,那么它们就会生成相同的输出。
分布式计算这方面的应用就格外明显。你可以把用多台机器一起执行同一件事情的问题缩减为实现分布式一致性日志为这些进程输入的问题。这儿日志的目的是把所有非确定性的东西排除在输入流之外,来确保每个复制进程能够同步地处理输入。
当你理解了这个以后,状态机复制原理就不再复杂或者说不再深奥了:这或多或少的意味着“确定性的处理过程就是确定性的”。不管怎样,我都认为它是分布式系统设计里较常用的工具之一。
这种方式的一个美妙之处就在于索引日志的时间戳就像时钟状态的一个副本——你可以用一个单独的数字描述每一个副本,这就是经过处理的日志的时间戳。时间戳与日志一一对应着整个副本的状态。
由于写进日志的内容的不同,也就有许多在系统中应用这个原则的不同方式。举个例子,我们记录一个服务的请求,或者服务从请求到响应的状态变化,或者它 执行命令的转换。理论上来说,我们甚至可以为每一个副本记录一系列要执行的机器指令或者调用的方法名和参数。只要两个进程用相同的方式处理这些输入,这些 进程就会保持副本的一致性。
一千个人眼中有一千种日志的用法。数据库工作者通常区分物理日志和逻辑日志。物理日志就是记录每一行被改变的内容。逻辑日志记录的不是改变的行而是那些引起行的内容被改变的SQL语句(insert,update和delete语句)。
分布式系统通常可以宽泛分为两种方法来处理数据和完成响应。“状态机器模型”通常引用一个主动-主动的模型——也就是我们为之记录请求和响应的对象。 对此进行一个细微的更改,称之为“预备份模型”,就是选出一个副本做为leader,并允许它按照请求到达的时间来进行处理并从处理过程中输出记录其状态 改变的日志。其他的副本按照leader状态改变的顺序而应用那些改变,这样他们之间达到同步,并能够在leader失败的时候接替leader的工作。
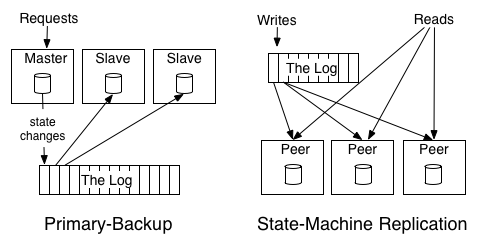
为了理解两种方式的不同,我们来看一个不太严谨的例子。假定有一个算法服务的副本,保持一个独立的数字作为它的状态(初始值为0),并对这个值进行加 法和乘法运算。主动-主动方式应该会输出所进行的变换,比如“+1”,“*2”等。每一个副本都会应用这些变换,从而得到同样的解集。主动-被动方式将会 有一个独立的主体执行这些变换并输出结果日志,比如“1”,“3”,“6”等。这个例子也清楚的展示了为什么说顺序是保证各副本间一致性的关键:一次加法 和乘法的顺序的改变将会导致不同的结果。

分布式日志可以理解为一致性问题模型的数据结构。因为日志代表了后续追加值的一系列决策。你需要重新审视Paxos算法簇,尽管日志模块是他们最常见 的应用。 在Paxos算法中,它通常通过使用称之为多paxos的协议,这种协议将日志建模为一系列的问题,在日志中每个问题都有对应的部分。在ZAB, RAFT等其它的协议中,日志的作用尤为突出,它直接对维护分布式的、一致性的日志的问题建模。
我怀疑的是,我们就历史发展的观点是有偏差的,可能是由于过去的几十年中,分布式计算的理论远超过了其实际应用。在现实中,共识的问题是有点太简单 了。计算机系统很少需要决定单个值,他们几乎总是处理成序列的请求。这样的记录,而不是一个简单的单值寄存器,自然是更加抽象。
此外,专注于算法掩盖了 抽象系统需要的底层的日志。我怀疑,我们最终会把日志中更注重作为一个商品化的基石,不论其是否以同样的方式 实施的,我们经常谈论一个哈希表而不是纠结我们 得到是不是具体某个细节的哈希表,例如线性或者带有什么什么其它变体哈希表。日志将成为一种大众化的接口,为大多数算法和其实现提升提供最好的保证和最佳 的性能。
变更日志101: 表与事件的二相性。
让我们继续聊数据库。数据库中存在着大量变更日志和表之间的二相性。这些日志有点类似借贷清单和银行的流程,数据库表就是当前的盈余表。如果你有大量 的变更日志,你就可以使用这些变更用以创建捕获当前状态的表。这张表将记录每个关键点(日志中一个特别的时间点)的状态信息。这就是为什么日志是非常基本 的数据结构的意义所在:日志可用来创建基本表,也可以用来创建各类衍生表。同时意味着可以存储非关系型的对象。

这个流程也是可逆的:如果你正在对一张表进行更新,你可以记录这些变更,并把所有更新的日志发布到表的状态信息中。这些变更日志就是你所需要的支持准 实时的克隆。基于此,你就可以清楚的理解表与事件的二相性: 表支持了静态数据而日志捕获变更。日志的魅力就在于它是变更的完整记录,它不仅仅捕获了表的最终版本的内容,它还记录了曾经存在过的其它版本的信息。日志 实质上是表历史状态的一系列备份。
这可能会引起你对源代码的版本管理。源代码管理和数据库之间有密切关系。版本管理解决了一个大家非常熟悉的问题,那就是什么是分布式数据系统需要解决 的— 时时刻刻在变化着的分布式管理。版本管理系统通常以补丁的发布为基础,这实际上可能是一个日志。您可以直接对当前 类似于表中的代码做出“快照”互动。你会注意到, 与其他分布式状态化系统类似,版本控制系统 当你更新时会复制日志,你希望的只是更新补丁并将它们应用到你的当前快照中。
最近,有些人从Datomic –一家销售日志数据库的公司得到了一些想法。这些想法使他们对如何 在他们的系统应用这些想法有了开阔的认识。 当然这些想法不是只针对这个系统,他们会成为 十多年分布式系统和数据库文献的一部分。
这可能似乎有点过于理想化。但是不要悲观!我们会很快把它实现。
接下来的内容
在这篇文章的其余部分,我将试图说明日志除了可用在分布式计算或者抽象分布式计算模型内部之外,还可用在哪些方面。其中包括:
数据集成-让机构的全部存储和处理系统里的所有数据很容易地得到访问。
实时数据处理-计算生成的数据流。
分布式系统设计-实际应用的系统是如何通过使用集中式日志来简化设计的。
所有这些用法都是通过把日志用做单独服务来实现的。
在上面任何一种用法里,日志的用途开始都是使用了日志所能提供的某个简单功能:生成永久的、可重现的历史记录。令人意外的是,问题的核心是可以让多少台机器以特定的方式,按照自身的速度重现历史记录的能力。
http://www.pmtoo.com/data/2014/0305/5037.html
首席工程师揭秘:LinkedIn大数据后台是如何运作的?(一)
标签:
原文地址:http://my.oschina.net/u/658658/blog/521018