标签:
环境:Jdk 1.7 Solr 5.3.0 Tomcat 7 mmseg4j-solr-2.3.0
1、Solr环境搭建
1.解压solr 5.3.0
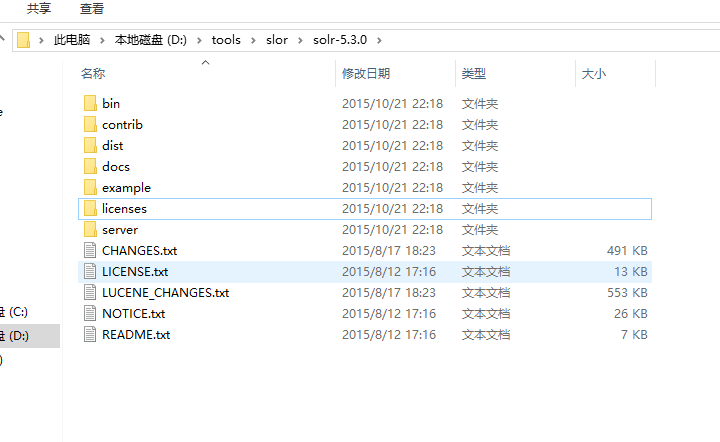
2.新建solr_home,将解压文件中的 server/solr 文件夹的复制到solr_home
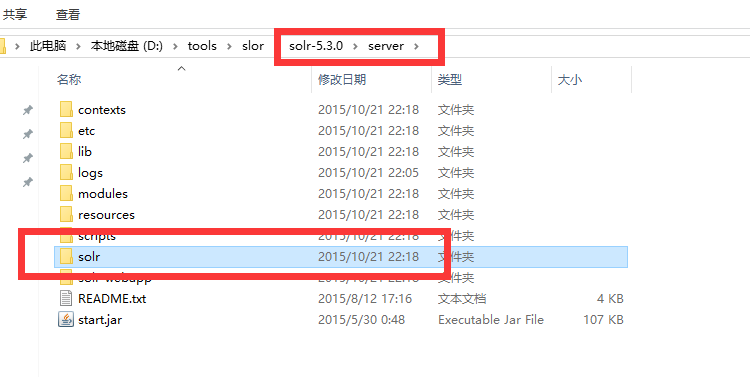
3.配置solr_home。在solr_home/solr中新建应用 mysolr
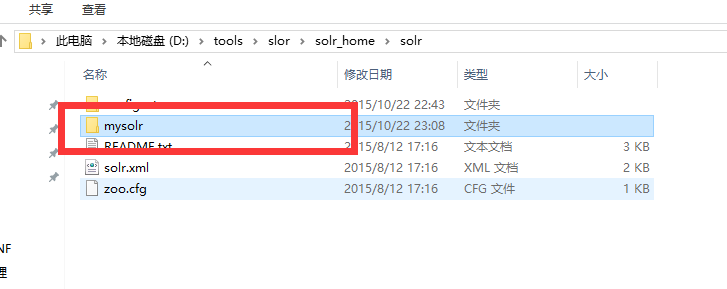
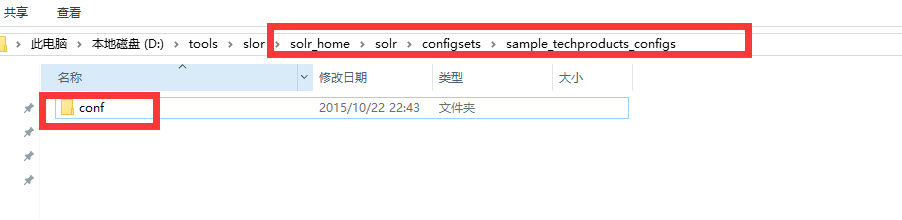
4.将solr_home/solr/configsets/sample_techproducts_configs中的conf文件夹复制到mysolr中
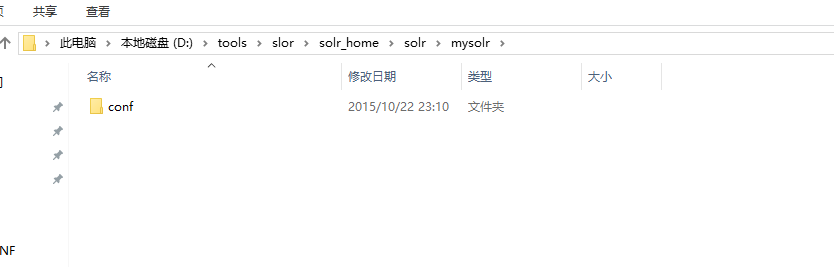
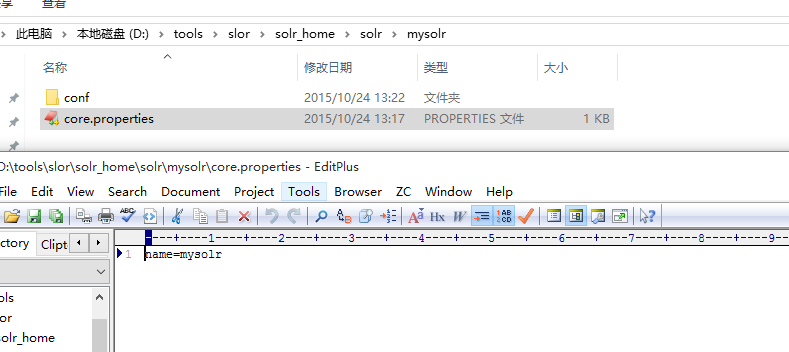
5.在mysolr目录中新建core.properties内容为name=mysolr (solr中的mysolr应用)
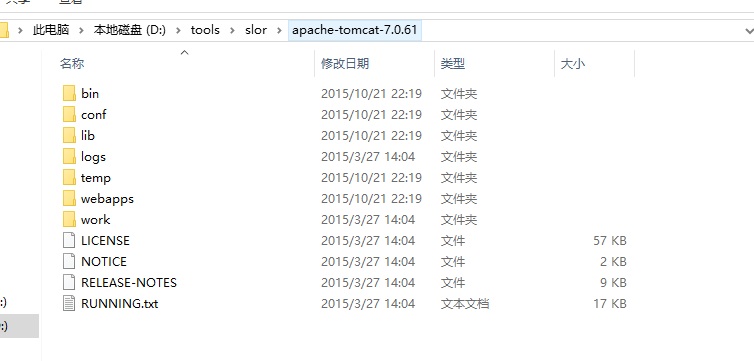
6.以tomcat 7为solr容器,解压tomcat
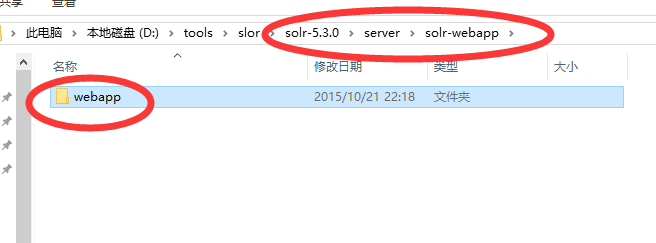
7.将solr-5.3.0\server中的solr-webapp复制到tomcat的webapps目录,重命名为solr
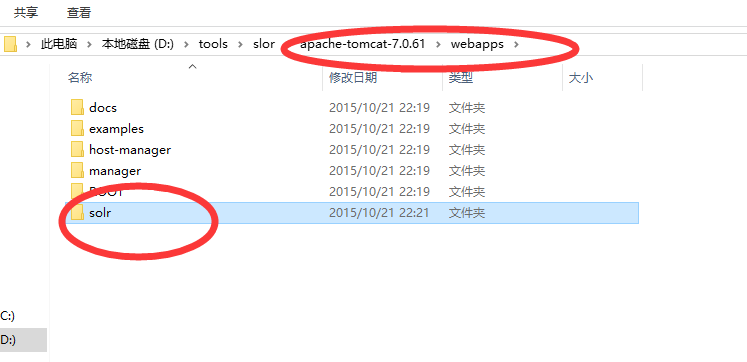
8.复制文件
(1)将以下内容复制到tomcat/webapps/solr/WEB-INF/lib文件夹中

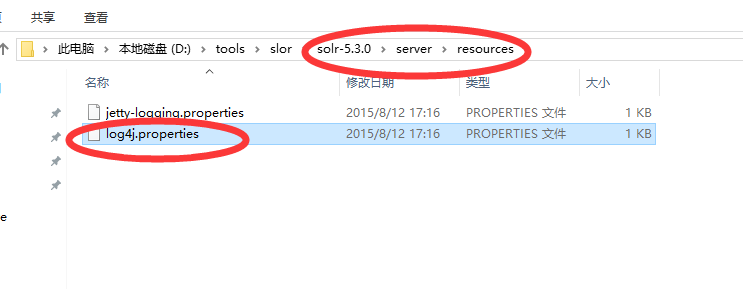
(2)将log4j.properties复制到tomcat/webapps/solr/WEB-INF/classes文件夹中(新建classes)
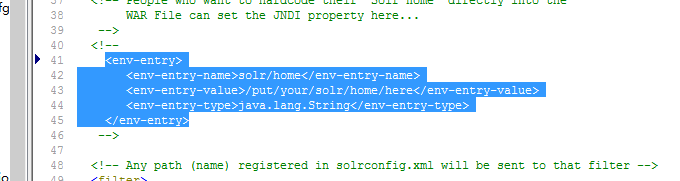
9.配置solr项目中的web.xml,打开 env-entry节点,配置solr_home


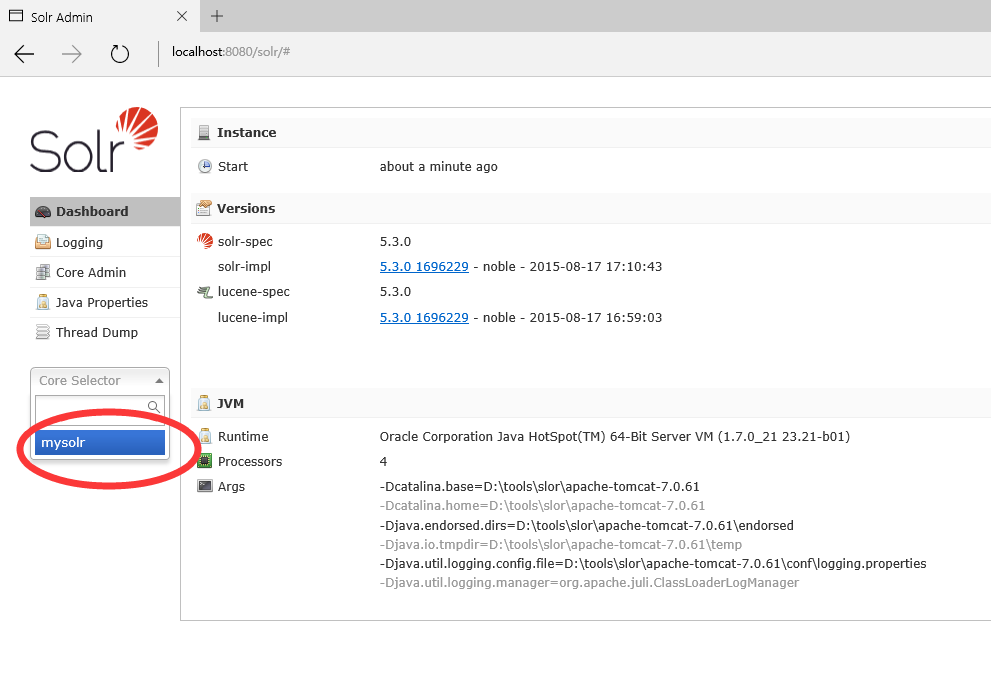
10.启动tomcat浏览器输入http://localhost:8080/solr
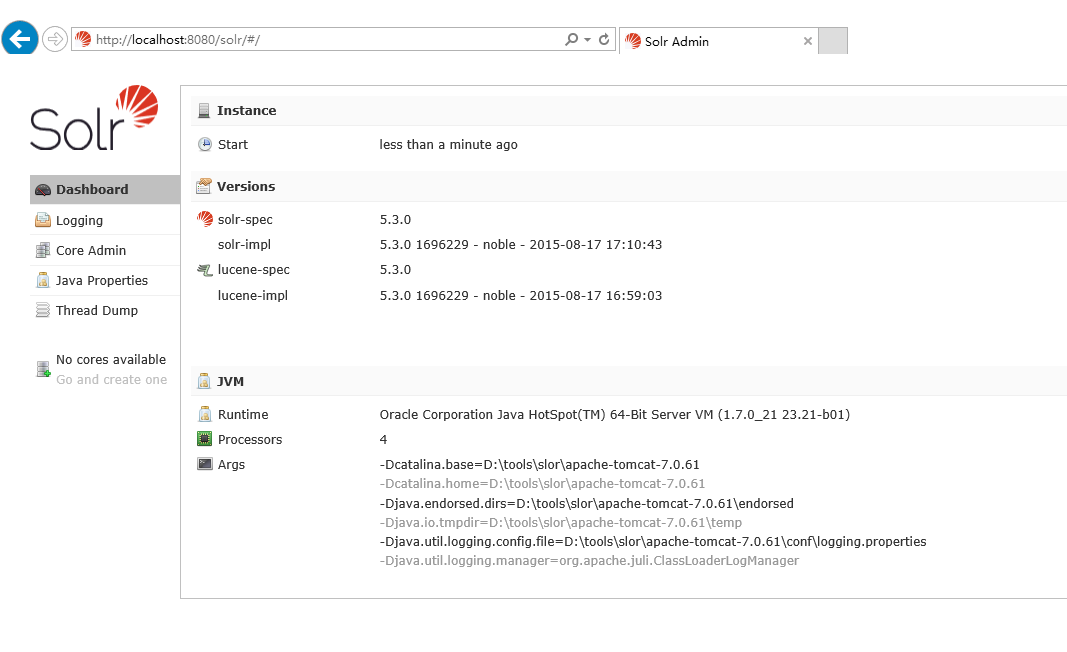
11.选择刚在solr_home中建的mysolr的应用、测试分词、默认分词器对中文支持不好
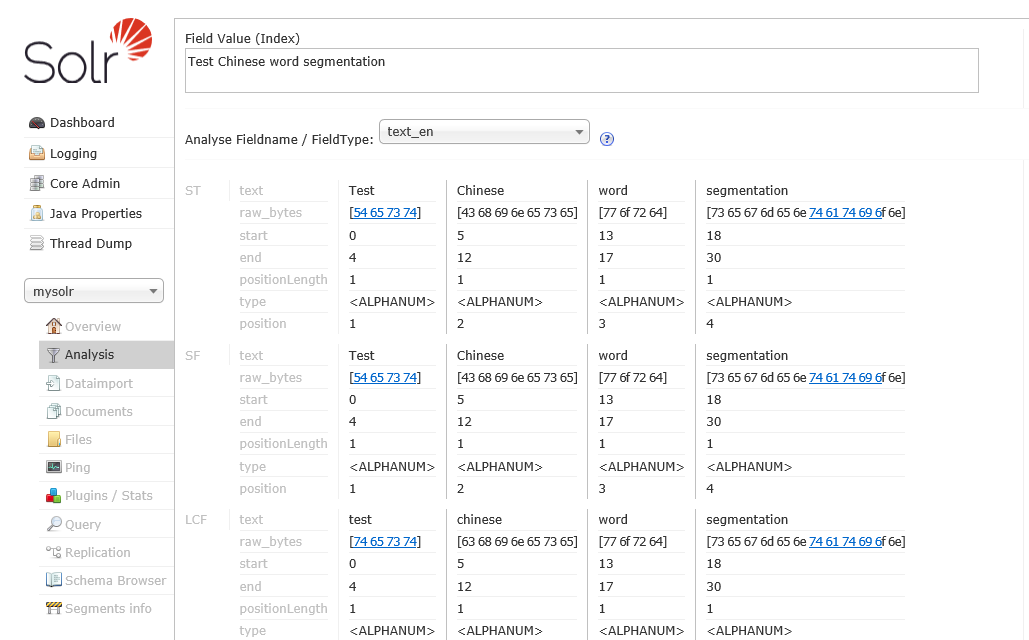

二、配置中文分词器(mmseg4j)
mmseg4j-solr-2.3.0支持solr5.3
1.将两个jar包考入tomcat中solr项目里的lib文件内

2.配置solr_home中mysolr域的schema.xml
新增:
<fieldtype name="textComplex" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="dic"/> </analyzer> </fieldtype> <fieldtype name="textMaxWord" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" /> </analyzer> </fieldtype> <fieldtype name="textSimple" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="n:/custom/path/to/my_dic" /> </analyzer> </fieldtype>
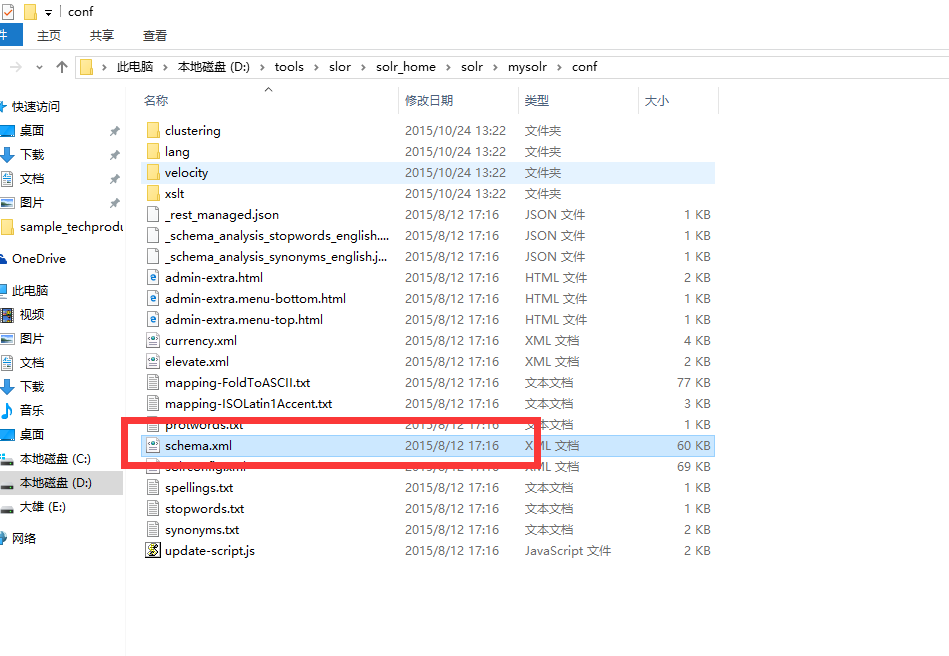

3.重启tomcat测试分词:(选择刚刚定义的textMaxWord )
)
三、Java调用Solr 5.3
package myjava.cn.dx.solr;
import org.apache.solr.client.solrj.*;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* solr 5.3.0
* Created by daxiong on 2015/10/23.
*/
public class MySolr {
//solr url
public static final String URL = "http://localhost:8080/solr";
//solr应用
public static final String SERVER = "mysolr";
//待索引、查询字段
public static String[] docs = {"Solr是一个独立的企业级搜索应用服务器",
"它对外提供类似于Web-service的API接口",
"用户可以通过http请求",
"向搜索引擎服务器提交一定格式的XML文件生成索引",
"也可以通过Http Get操作提出查找请求",
"并得到XML格式的返回结果"};
public static SolrClient getSolrClient(){
return new HttpSolrClient(URL+"/"+SERVER);
}
/**
* 新建索引
*/
public static void createIndex(){
SolrClient client = getSolrClient();
int i = 0;
List<SolrInputDocument> docList = new ArrayList<SolrInputDocument>();
for(String str : docs){
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id",i++);
doc.addField("content_test", str);
docList.add(doc);
}
try {
client.add(docList);
client.commit();
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
};
/**
* 搜索
*/
public static void search(){
SolrClient client = getSolrClient();
SolrQuery query = new SolrQuery();
query.setQuery("content_test:搜索");
QueryResponse response = null;
try {
response = client.query(query);
System.out.println(response.toString());
System.out.println();
SolrDocumentList docs = response.getResults();
System.out.println("文档个数:" + docs.getNumFound());
System.out.println("查询时间:" + response.getQTime());
for (SolrDocument doc : docs) {
System.out.println("id: " + doc.getFieldValue("id") + " title: " + doc.getFieldValue("content_test"));
}
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
//createIndex();
search();
}
}
mava配置 pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>myjava</groupId>
<artifactId>cn.dx</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>cn.dx</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>5.3.0</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>1.7.7</version>
</dependency>
</dependencies>
</project>

Solr 5.3.0集成mmseg4j、tomcat部署、Solrj 5.3.0使用
标签:
原文地址:http://my.oschina.net/daxiong0615/blog/521566