标签:
一、虚拟机版本
VirtualBox-4.3.30
二、操作系统
CentOS-6.7-x86_64-bin-DVD1.iso
下载地址1:http://www.centoscn.com/CentosSoft/iso/2015/0813/6001.html
三、安装两个Linux虚拟机
名字取名为hadoop1和hadoop2
具体步骤可以参考百度经验
只是注意细节在创建虚拟机时需要将内存大小修改1024MB,因为过低的内存将无法安装桌面系统,只能以命令行形式进行操作,并且建议不要选择安装最小桌面,选择第一个桌面,最小安装可能会缺少许多有用的程序,比如我最初安装一台是完全桌面hadoop1,另一台是最小桌面hadoop2,导致后面通过命令ssh hadoop1/2可以从hadoop1登陆到hadoop2,hadoop2无法登陆到hadoop1(但是ssh hadoop1的ip地址可以登陆),新建的hadoop3采用完全安装,则可以再hadoop1,3之间互相登陆。
说明:后面也是用hadoop1和hadoop3作为主从节点。虽然hadoop2事实上是可用的,但是自己的计算机无法流畅运行3个虚拟机。
http://www.cnblogs.com/zhcncn/p/4071539.html
3.1安装增强功能
虚拟机安装好了之后,可以安装增强功能,不安装的话,虚拟机拉伸窗口不会改变虚拟机界面大小,也无法建立共享文件夹
这时安装增强功能会出现错误:
building the main Guest Additions module [失败]
是因为缺少必要的包
需要在终端执行命令
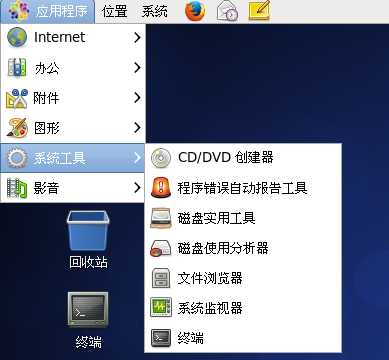
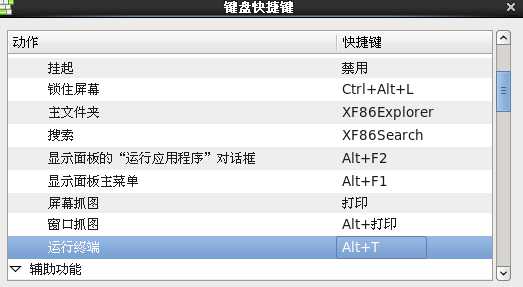
终端可拖至桌面,还可设置快捷键 系统/键盘快捷键/桌面/运行终端 点击快捷键,按住ctrl+alt+T 就可以设置如ubantu的运行终端快捷键了。
# yum install make gcc gcc-c++ kernel kernel-devel
安装 gcc ,gcc-c++,kernel,kernel-devel,可能还需要kernel-headers
安装完毕后,再执行之前操作安装增强功能,如果执行过一次了,点击没有反应。可以先弹出光驱,再加载进来,就会提示是否运行其中的程序。
注意:可能还是会提示有如下错误
Building the OpenGL support module [失败]
可以不管,重新启动虚拟机,就会生效
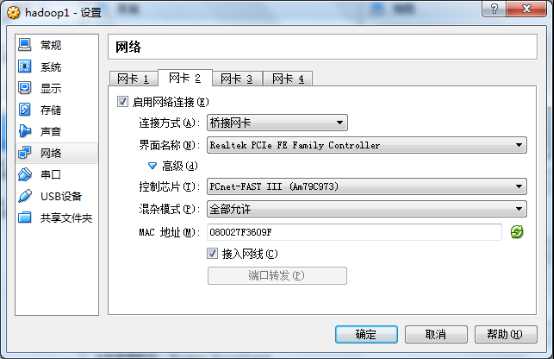
3.2创建虚拟机网络
3.3配置共享文件夹
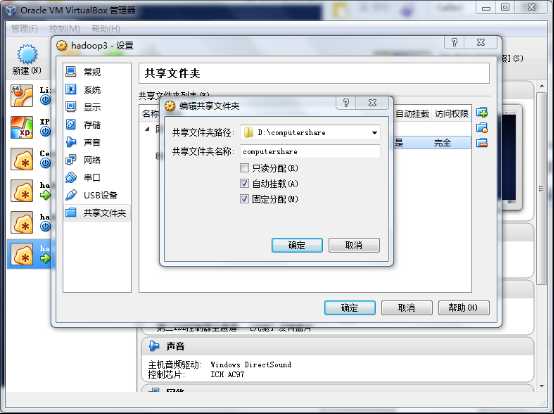
配置共享文件夹的作用:方便本机、虚拟机与虚拟机之间传递文件
各个虚拟机设置的共享路径最好是同一个,这样就有了一个共同可以访问的文件夹了。
现在回到虚拟机在文件系统 /mnt/ 目录下创建一个文件夹 shared(可以自取)
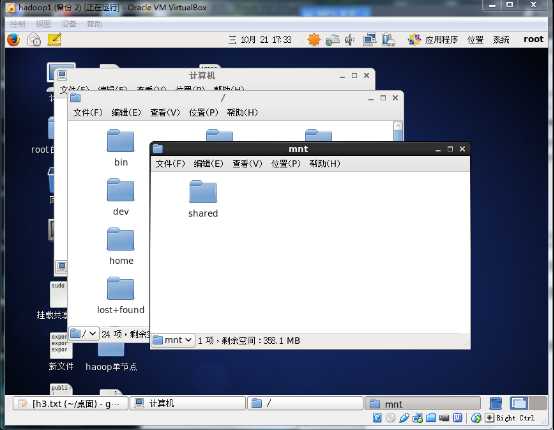
执行命令:sudo mount -t vboxsf computershare(共享文件夹名称) /mnt/shared

就挂载了共享文件夹。
不过每次启动虚拟机都需要执行此命令才会挂载共享文件夹。
四、配置虚拟机网络
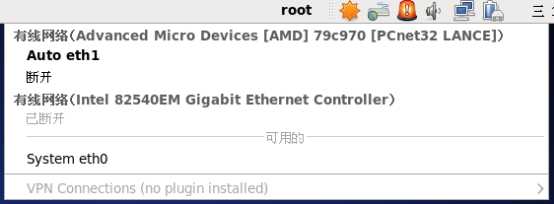
网卡1 Eth0是nat转发如果计算机联网可以直接访问外网,但虚拟机间无法ping
网卡2 eth1 是桥接方式 连接上后虚拟机将处于同一个网段
可以相互ping通。但是我们不用动态分配ip我们手动设置ip。
右击网络图标,点击编辑连接
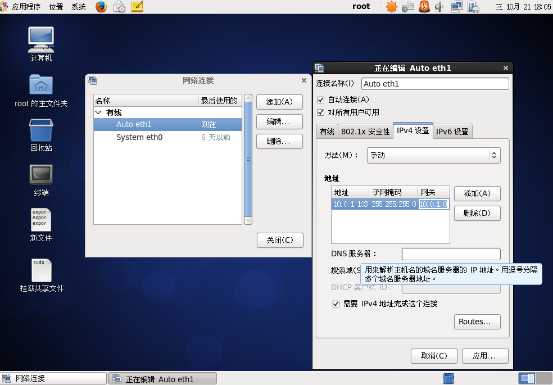
点击IPv4设置,方法设置为手动,添加地址并应用
Hadoop1可以设置为
10.0.1.101 255.255.255.0 10.0.1.0
另一台虚拟机hadoop3可以设置为
10.0.1.103 255.255.255.0 10.0.1.0
最后一步修改hosts
在 /etc/hosts 目录,修改如下:
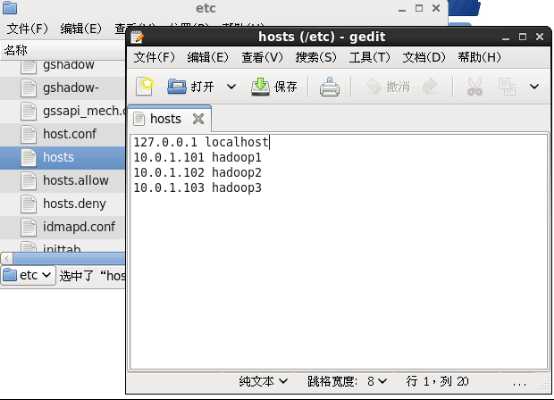
同样的操作对于另一台虚拟机hadoop2的文件配置也是如此
五、配置SSH免密码登录
1、以root登录,在A机器上执行
ssh-keygen -t rsa
一路回车,不需要输入密码(随意)
执行该操作将在/root/.ssh下生成id_rsa, id_rsa.pub文件,其中id_rsa.pub是公钥。(可以自己设置路径和文件名,为了区别不同公钥可以设置为/root/.ssh/hadoop1_id_rsa)
2、在B机器上做步骤1或自行创建/home/user/.ssh文件夹,将id_rsa.pub拷贝到B机器上
scp id_rsa.pub B:~/.ssh/A.id_rsa.pub
3、将拷贝到B机器上的A.id_rsa.pub复制到authorized_keys文件中
cp A.id_rsa.pub authorized_keys
或没有authorized_keys用
cat A.id_rsa.pub >> authorized_keys
若有多个主机要访问,使用>>添加到authorized_keys文件中
注意:要进入到相应文件cd .ssh(在查看中显示隐藏文件)
解释:
A将公钥发给B,不是说让B来访问A,而是A就可以访问B了。也就是说B在.ssh文件夹下的authorized_keys保留A的公钥,保存就是把自己让给别人来访问!
同样的操作将B的公钥发给A,这样B也可以访问A了。其实不必做这一步,以为我们之后是将A作为master ,B作为salve,只需要A可以免密码登陆B即可
六、安装jdk
我们使用离线安装jdk1.7,先下载jdk-7u79-linux-x64.gz,
官方地址:http://www.oracle.com/technetwork/cn/java/javase/downloads/jdk7-downloads-1880260.html
然后通过共享文件夹,传到虚拟机上,解压到/usr/jdk1.7/目录下,需要解压两次才可以。
想在线安装亦可以,百度相关资料有很多。
最后需要设置环境变量
在/etc/profile目录文件下最后增加如下内容
export JAVA_HOME=/usr/jdk1.7/jdk1.7.0_79
export HADOOP_HOME=/opt/hadoop-1.2.1
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
其中hadoop 是后面需要配置hadoop的环境变量而增加,为了方便,一次性加上避免重复修改。从机节点(datanode)不需要,即只要
export JAVA_HOME=/usr/jdk1.7/jdk1.7.0_79
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
Ps:从机加上hadoop_home,也无法执行hadoop命令(⊙﹏⊙)b
后面再介绍
最后为了使其生效,需要执行命令:
#source /etc/profile
通过#java -version 可以验证是否安装成功
七、安装hadoop1.2.1
实验采用的是hadoop1.2.1,最新版已达2.7.1但是我根据百度经验配置,最后没成功,datanode节点hadoop1(namenode节点)始终认为未启动,而在hadoop2中通过#jps命令却表示已经有datanode进程。后来才发现可能是防火墙没有关闭。但是没机会去验证了,在这个版本的hadoop也需要关闭防火墙。否则会遇到同样的问题,出现问题是”....0 datanode...“问题。
hadoop2.7.1经验地址:
http://jingyan.baidu.com/article/f00622283a76c0fbd3f0c839.html
回到我们的实验,此次hadoop安装我们采用在线安装
先确保连接到网卡1 (eth0),可以访问外网
7.1 下载hadoop1.2.1
使用命令
#wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
然后移动到/opt/目录
#mv hadoop-1.2.1.tar.gz /opt/
#cd /opt
解压文件
#tar -zxvf hadoop-1.2.1.tar.gz
#cd hadoop-1.2.1
Ps:采用离线方式,就如同jdk安装方式,先下载后解压到你想要放的目录下。
7.2配置conf
我们需要配置六个文件
进入在hadoop-1.2.1文件下打开conf文件,我们需要配置如下六个文件
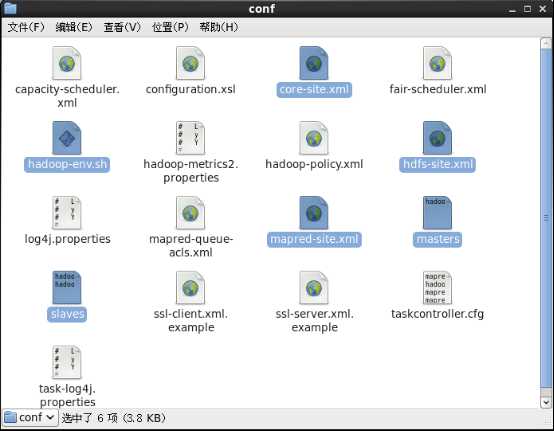
7.2.1 hadoop-env.sh
用编辑打开
修改一处为
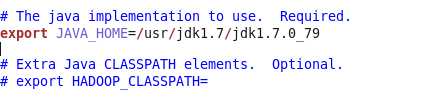
原文件export是被#注释了,并且需要改成你现在的Java_home地址
7.2.2 masters文件
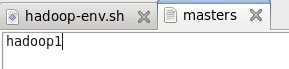
7.2.3 slaves 文件
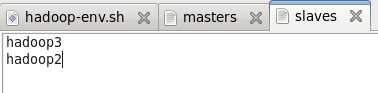
7.2.4 core-site.xml
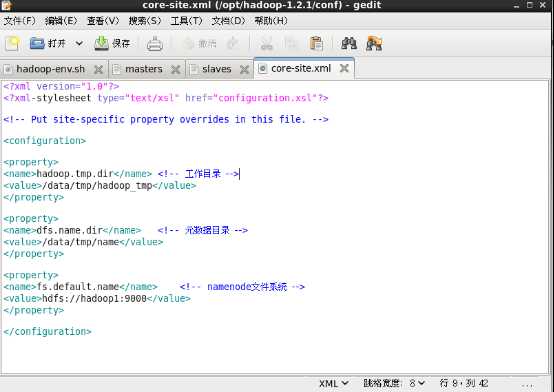
<property>
<name>hadoop.tmp.dir</name> <!-- 工作目录 -->
<value>/data/tmp/hadoop_tmp</value>
</property>
<property>
<name>dfs.name.dir</name> <!-- 元数据目录 -->
<value>/data/tmp/name</value>
</property>
<property>
<name>fs.default.name</name> <!-- namenode文件系统 -->
<value>hdfs://hadoop1:9000</value>
</property>
7.2.5 hdfs-site.xml
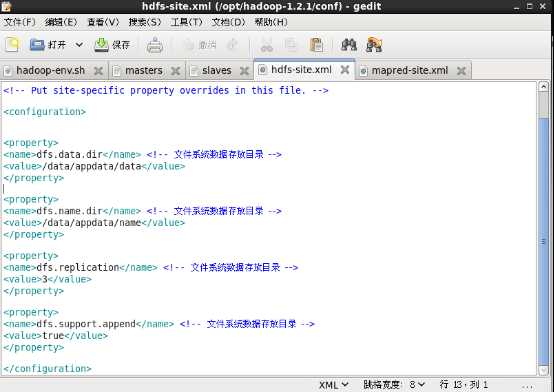
<property>
<name>dfs.data.dir</name> <!-- 文件系统数据存放目录 -->
<value>/data/appdata/data</value>
</property>
<property>
<name>dfs.name.dir</name> <!-- 文件系统数据存放目录 -->
<value>/data/appdata/name</value>
</property>
<property>
<name>dfs.replication</name> <!-- 文件系统数据存放目录 -->
<value>3</value>
</property>
<property>
<name>dfs.support.append</name> <!-- 文件系统数据存放目录 -->
<value>true</value>
</property>
7.2.6 mapred-site.xml
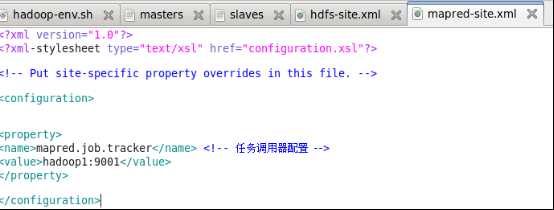
<property>
<name>mapred.job.tracker</name> <!-- 任务调用器配置 -->
<value>hadoop1:9001</value>
</property>
7.3 拷贝hadoop到其他节点
#scp -r /opt/hadoop-1.2.1 hadoop3:/opt/
7.4初始化
Hadoop环境变量设置见前jdk处,执行#hadoop可以检测hadoop命令是否起作用
在配置好conf之后,我们需要在使用hadoop之前
格式化系统
#hadoop namenode -format
重点提醒:
记得关闭防火墙,每次开机使用hadoop前关闭防火墙
命令
#service iptables stop
进入bin,其目录下有许多程序,
执行#./start-all.sh 启动所有

Hadoop1执行#jps
观察到
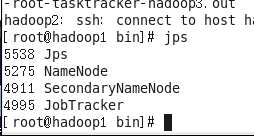
Namenode ,secondarynamenode,jobtracker都运行了,表明正常启动如果没有,可能是之前执行了,没有格式化,重新格式化一下。还可能是你防火墙没有关闭
Hadoop2执行#jps
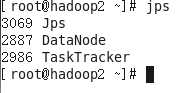
Ps:可能出现有的进程没有启动,比如namenode,datanode,可以多次尝试格式化,./start-all.sh ,./stop-all.sh
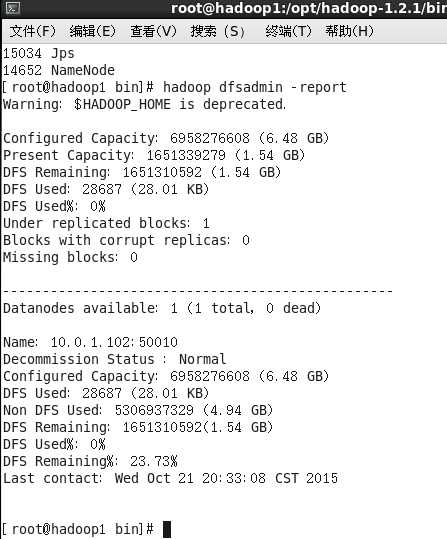
7.5 验证hadoop启动成功
可以执行命令
#hadoop dfsadmin -report有结果
八、运行一个hadoop程序
功能:根据wordcount程序改编而成,统计子串数目
SubStringCount.java文件:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class SubStringCount {
public static class SubStringCountMap extends
Mapper<LongWritable, Text, Text, IntWritable> {
private final IntWritable intvalue = new IntWritable(1);
private Text word = new Text();
private int SubString(String str1, String substr)
{
int counter = 0;
for (int i = 0; i <= str1.length() - substr.length(); i++) {
if (str1.substring(i, i + substr.length()).equals(substr)) {
counter++;i+=substr.length()-1;
}
}
return counter;
}
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer token = new StringTokenizer(line);
//获取参数,SubString
String substring=context.getConfiguration().get("SubString");
word.set(substring);
while (token.hasMoreTokens()) {
int temp=SubString(token.nextToken(),substring);
if(temp>0)
{
intvalue.set(temp);
context.write(word, intvalue);
}
}
}
}
public static class SubStringCountReduce extends
Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
if(args.length<3)
{
System.err.println("please input three args:<inputfile> <outfile> <substring>");
System.exit(2);
}
Configuration conf = new Configuration();
String substring=args[2];
conf.set("SubString",substring);
Job job = new Job(conf);
job.setJarByClass(SubStringCount.class);
job.setJobName("substringcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(SubStringCountMap.class);
job.setReducerClass(SubStringCountReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
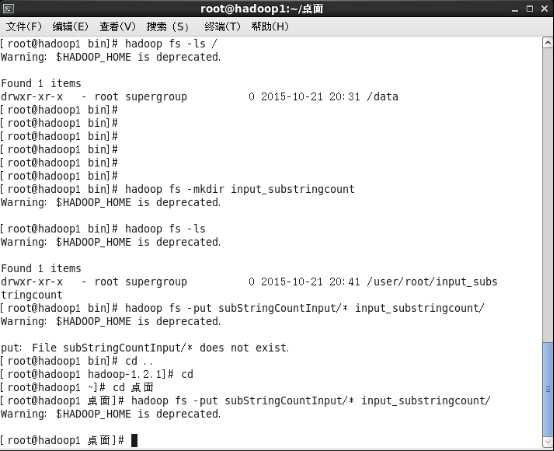
1.在桌面建立一个subStringCountInput文件夹,创建两个文件,里面随意添加些字符串内容
然后在hadoop文件系统下创建一个目录
#hadoop fs -mkdir input_substringcount
并将subStringCountInput的内容上传到dfs文件系统,
#hadoop fs -put subStringCountInput/* input_substringcount/
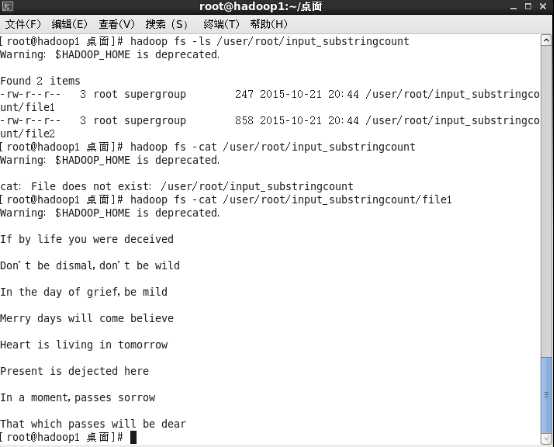
命令#hadoop fs -ls / 用于查看
附录:
DFS 命令:
hadoop fs -mkdir /tmp/input 在HDFS上新建文件夹
hadoop fs -put input1.txt /tmp/input 把本地文件input1.txt传到HDFS的/tmp/input目录下
hadoop fs -get input1.txt /tmp/input/input1.txt 把HDFS文件拉到本地
hadoop fs -ls /tmp/output 列出HDFS的某目录
hadoop fs -cat /tmp/ouput/output1.txt 查看HDFS上的文件
hadoop fs -rmr /home/less/hadoop/tmp/output 删除HDFS上的目录
hadoop dfsadmin -report 查看HDFS状态,比如有哪些datanode,每个datanode的情况
hadoop dfsadmin -safemode leave 离开安全模式
hadoop dfsadmin -safemode enter 进入安全模式
2.生成substringcount.jar
#javac -classpath /opt/hadoop-1.2.1/hadoop-core-1.2.1.jar:/opt/hadoop-1.2.1/lib/commons-cli-1.2.jar -d substring_count_class/ SubStringCount.java
不能直接用javac,因为.java中用到了hadoop的包
#cd substring_count_class/
#jar -cvf substringcount.jar *.class
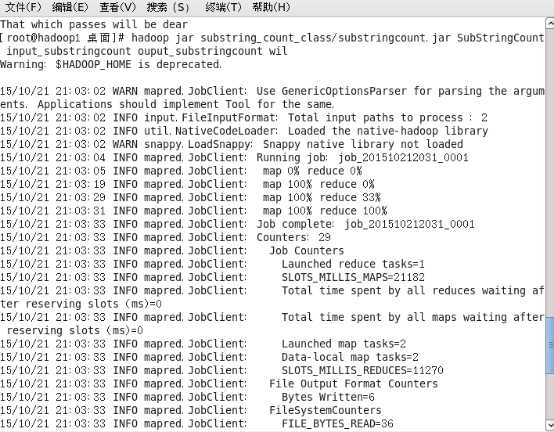
3.执行
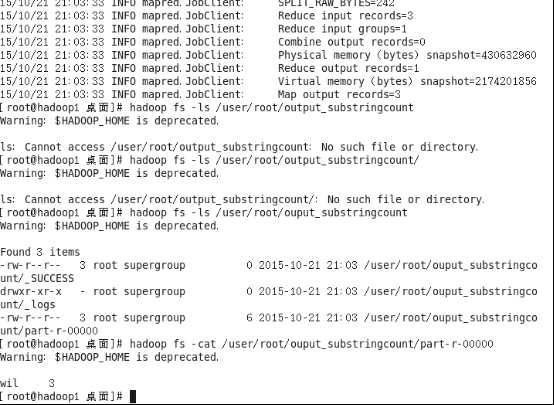
#hadoop jar substring_count_class/substringcount.jar SubStringCount input_substringcount output_substringcount wil(你所要统计的子串)
4.查看结果
#hadoop fs -cat /user/root/output_substringcount/part-r-00000

九、总结
本实验总结了hadoop的安装配置和运行了一个样例程序,仅供参考,可能其中存在谬误的地方,请参考其他人的配置方案。
个人推荐可以看一看慕课网的hadoop课程(1个小时),虽然是单节点方式配置的但对于理解hadoop的架构,工作原理有所帮助。
地址:
Hadoop大数据平台架构与实践--基础篇
http://www.imooc.com/learn/391
另外还可以参考hadoop的配置的文章
地址:
http://www.sxt.cn/u/756/blog/4848
标签:
原文地址:http://www.cnblogs.com/tianjiqx/p/4908276.html