标签:
一、动手动脑
【String.equals】
程序代码

结果截图
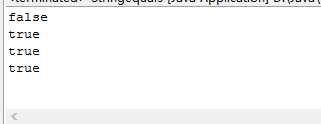
String.equals()方法用于判断两个对象表示的值是否相等,判断结果为bool型,即结果为ture || false.
使用方法示例:s1.equals(s2);
[String.Length()]
public int length()
返回此字符串的长度。长度等于字符串中 Unicode 代码单元的数量。
CharSequence中的length[String.charAt()]
public char charAt(int index)
返回指定索引处的char值。索引范围为从0到 length()-1。序列的第一个 char 值位于索引0 处,第二个位于索引 1 处,依此类推,这类似于数组索引。
如果索引指定的char值是代理项,则返回代理项值。
CharSequence中的 charAtindex char值的索引。char 值。第一个 char 值位于索引 0 处。IndexOutOfBoundsException-如果 index 参数为负或小于此字符串的长度。[String.getChars()]
public void getChars(int srcBegin,
int srcEnd,
char[] dst,
int dstBegin)
要复制的第一个字符位于索引 srcBegin 处;要复制的最后一个字符位于索引 srcEnd-1 处(因此要复制的字符总数是 srcEnd-srcBegin)。要复制到 dst 子数组的字符从索引 dstBegin 处开始,并结束于索引:
dstbegin+(srcEnd-srcBegin)-1
srcBegin - 字符串中要复制的第一个字符的索引。srcEnd - 字符串中要复制的最后一个字符之后的索引。dst - 目标数组。dstBegin - 目标数组中的起始偏移量。IndexOutOfBoundsException-如果下列任何一项为 true:
srcBegin 为负。srcBegin 大于 srcEndsrcEnd 大于此字符串的长度dstBegin 为负dstBegin+(srcEnd-srcBegin) 大于 dst.length[String.replace()]
public String replace(char oldChar,
char newChar)
newChar 替换此字符串中出现的所有oldChar 得到的。
如果 oldChar 在此 String 对象表示的字符序列中没有出现,则返回对此 String 对象的引用。否则,创建一个新的 String 对象,它所表示的字符序列除了所有的 oldChar 都被替换为 newChar 之外,与此 String 对象表示的字符序列相同。
示例:
"mesquite in your cellar".replace(‘e‘, ‘o‘)
returns "mosquito in your collar"
"the war of baronets".replace(‘r‘, ‘y‘)
returns "the way of bayonets"
"sparring with a purple porpoise".replace(‘p‘, ‘t‘)
returns "starring with a turtle tortoise"
"JonL".replace(‘q‘, ‘x‘) returns "JonL" (no change)
oldChar-原字符。newChar-新字符。oldChar 替代为 newChar。[String.toUpperCase()]
public String toUpperCase()
String 中的所有字符都转换为大写。此方法等效于 toUpperCase(Locale.getDefault())。
注: 此方法与语言环境有关,如果用于应独立于语言环境解释的字符串,则可能生成不可预料的结果。示例有编程语言标识符、协议键、HTML 标记。例如,"title".toUpperCase() 在 Turkish(土耳其语)语言环境中返回 "T?TLE",其中“?”是 LATIN CAPITAL LETTER I WITH DOT ABOVE 字符。对于与语言环境有关的字符,要获得正确的结果,请使用 toUpperCase(Locale.ENGLISH)。
String。[String.toLowerCase()]
public String toLowerCase(Locale locale)
Locale 的规则将此 String 中的所有字符都转换为小写。大小写映射关系基于 Character 类指定的 Unicode 标准版。由于大小写映射关系并不总是 1:1 的字符映射关系,因此所得 String 的长度可能不同于原 String。
下表中给出了几个小写映射关系的示例:
| 语言环境的代码 | 大写字母 | 小写字母 | 描述 |
|---|---|---|---|
| tr (Turkish) | \u0130 | \u0069 | 大写字母 I,上面有点 -> 小写字母 i |
| tr (Turkish) | \u0049 | \u0131 | 大写字母 I -> 小写字母 i,无点 |
| (all) | French Fries | french fries | 将字符串中的所有字符都小写 |
| (all) | 将字符串中的所有字符都小写 |
locale - 使用此语言环境的大小写转换规则String。[String.trim()]
public String trim()
如果此 String 对象表示一个空字符序列,或者此 String 对象表示的字符序列的第一个和最后一个字符的代码都大于 ‘\u0020‘(空格字符),则返回对此 String 对象的引用。
否则,若字符串中没有代码大于 ‘\u0020‘ 的字符,则创建并返回一个表示空字符串的新 String 对象。
否则,假定 k 为字符串中代码大于 ‘\u0020‘ 的第一个字符的索引,m 为字符串中代码大于 ‘\u0020‘ 的最后一个字符的索引。创建一个新的 String 对象,它表示此字符串中从索引 k 处的字符开始,到索引 m 处的字符结束的子字符串,即 this.substring(k, m+1) 的结果。
此方法可用于截去字符串开头和末尾的空白(如上所述)。
[String.toCharArray()]
public char[] toCharArray()
二、字串加密
设计思路
实现字符串加密时利用String.charAt()函数实现字符串的加密,即改变字符串。
流程图
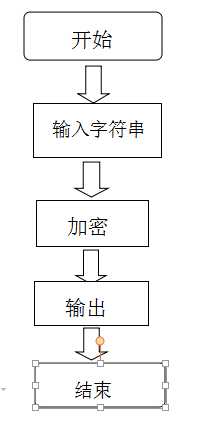
源代码
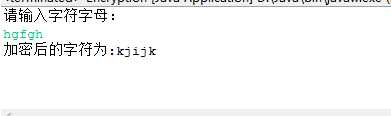
验证结果
标签:
原文地址:http://www.cnblogs.com/Againzg/p/4909771.html