标签:
研究了上下文缓存的实现方案,其原理类似Apache Commons Collections 项目中LRUMap,它继承于AbstractLinkedMap 抽象类,其基本思想是将最近使用的数据放置于链表的头上,进行LRUMap进行淘汰时只需要删除链表最后一个即可。
继承关系如下图:
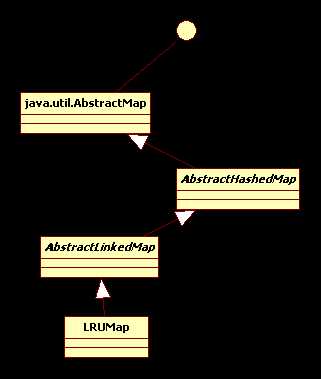
从AbstractHashedMap看起,在此之前先学习一下hashMap的实现原理,然后分析AbstractLinkedMap和LURMap。
1、通用的HashMap的一般原理
Hashmap实际上是一个数组和链表的结合体,通过key值得到一个hashcode,作为数组的下表,能够快速定位到value。如果多个不同的key值计算出了相同的hashcode,就会有多个value定位到数组的同一个位置,这就是所谓的冲突。这种情况下,这多个value会组成链表,访问效率就会降低,所以key值计算出来的hashcode要尽量的分散,这样就会有比较高的效率,下面是一个从网上找的一个HashMap的数据结构图:
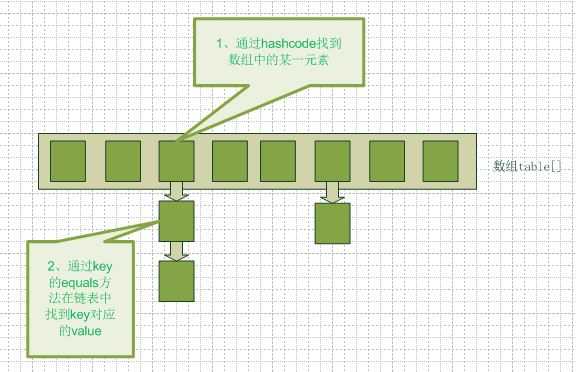
上面提到了根据key值计算hashcode,这个计算过程叫做Hash算法,一般通用的做法是key值对数组的长度取模,当然还有很多其他精妙的算法,在此不赘述……
当hashmap中的元素越来越多的时候,冲突的几率也就越来越高(因为数组的长度是固定的),所以为了提高查询的效率,就要对hashmap的数组进行扩容,数组扩容这个操作也会出现在ArrayList中,所以这是一个通用的操作,。
hashmap什么时候进行扩容呢?当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。
2、AbstractHashedMap
AbstractHashedMap实现了Map接口,并自己单独实现了Hash算法,使自己成为一个HashedMap。
API介绍如下所示,我只拣几个重要属性和方法介绍一下
http://commons.apache.org/proper/commons-collections/javadocs/api-3.2.1/org/apache/commons/collections/map/AbstractHashedMap.html
2.1属性 protected AbstractHashedMap.HashEntry[] data;
全局数组,每个数组的元素是一个带有后续指针(next)、key、hashcode、hashvalue的数据结构,可以说所有的操作都是为了维护这个数组
2.2属性 protected static int
DEFAULT_CAPACITY默认的数组大小,可以通过构造函数指定
2.3属性 protected float loadFactor
扩展因子,默认为0.75,即数组填充率达到数组大小的75%的时候,会默认调整大小,重新计算元素在数组中的位置。
2.4方法 java.lang.Object
get(java.lang.Object key)从data[]中与链表结构中取得value
2.5方法 java.lang.Object put(java.lang.Object key, java.lang.Object value)
首先查看该value是否在data[]中,如果存在就更新一下就完事;否则就调用addMapping方法,生成一个新的HashEntry结构,加入到data[hashcode]对应位置的链表头上。
2.6方法 java.lang.Object
remove(java.lang.Object key)从维护的data结构中删除对应的value
2.7方法 protected void reuseEntry(AbstractHashedMap.HashEntry entry, int hashIndex, int hashCode, java.lang.Object key, java.lang.Object value)
???
2.7其他方法,作用见名知意
protected void addEntry(AbstractHashedMap.HashEntry entry, int hashIndex)
protected void addMapping(int hashIndex, int hashCode, java.lang.Object key, java.lang.Object value)
protected void removeEntry(AbstractHashedMap.HashEntry entry, int hashIndex, AbstractHashedMap.HashEntry previous)
protected void removeMapping(AbstractHashedMap.HashEntry entry, int hashIndex, AbstractHashedMap.HashEntry previous)
3、AbstractLinkedMap
AbstractLinkedMap继承自前面的AbstractHashedMap,在AbstractHashedMap的基础上,将所有的HashEntity维护成双向的链表
API地址如下:
http://commons.apache.org/proper/commons-collections/javadocs/api-3.2.1/org/apache/commons/collections/map/LinkedMap.html
3.1属性 protected AbstractLinkedMap.LinkEntry header
LinkEntry包含了before、after两个指针,形成双向链表
3.2方法 protected void addEntry(AbstractHashedMap.HashEntry entry, int hashIndex)重写了父类的增加节点的方法,不但维护data[],同时维护了双向链表
3.3方法 protected void removeEntry(AbstractHashedMap.HashEntry entry, int hashIndex, AbstractHashedMap.HashEntry previous)重写了父类的删除节点的方法,不但维护了data[],同时维护了双向链表
4、LRUMap
LRUMap也是非线程安全。主要是在父类AbstractLinedMap的基础上,在更新双向链表的时候增加了moveToMRU/removeLRU操作
4.1方法 protected void moveToMRU(AbstractLinkedMap.LinkEntry entry)
将entry移动到双向链表的头部
4.2方法 protected boolean removeLRU(AbstractLinkedMap.LinkEntry entry)
???
4.3方法 protected void reuseMapping(AbstractLinkedMap.LinkEntry entry, int hashIndex, int hashCode, java.lang.Object key, java.lang.Object value)???
5、扩展
在上下文实现方案中,重写了该类,采用synchronized关键字实现了线程安全。
增加了对缓存数据大小的控制,超过一定大小则将旧的数据remove掉。
参考:
http://annegu.iteye.com/blog/539465
http://www.blogjava.net/xmatthew/archive/2012/06/28/380150.html
标签:
原文地址:http://www.cnblogs.com/mingziday/p/4910004.html