标签:
在此举一个例子。比如,某学校共有500名学生,现在要通过抽取样本量为30的一个样本,来推断学生的数学成绩。这时可以依据抽取的样本信息,计算出样本的均值与标准差。如果我们抽取的不是一个样本,而是10个样本,每个样本30人,那么每个样本都可以计算出均值,这样就会有10个均值。也就是形成了一个10个数字的数列,然后计算这10个数字的标准差,此时的标准差就是标准误。但是,在实际抽样中我们不可能抽取10个样本。所以,标准误就由样本标准差除以样本量来表示。当然,这样的结论也不是随心所欲,而是经过了统计学家的严密证明的。
在实际的应用中,标准差主要有两点作用,一是用来对样本进行标准化处理,即样本观察值减去样本均值,然后除以标准差,这样就变成了标准正态分布;而是通过标准差来确定异常值,常用的方法就是样本均值加减n倍的标准差。标准误的作用主要是用来做区间估计,常用的估计区间是均值加减n倍的标准误。
英文:Standard Error
标准偏差反映的是个体观察值的变异,标准误反映的是样本均数之间的变异(即样本均数的标准差,是描述均数抽样分布的离散程度及衡量均数抽样误差大小的尺度),标准误不是标准差,是样本平均数的标准差。
标准误用来衡量抽样误差。标准误越小,表明样本统计量与总体参数的值越接近,样本对总体越有代表性,用样本统计量推断总体参数的可靠度越大。因此,标准误是统计推断可靠性的指标。
在相同测量条件下进行的测量称为等精度测量,例如在同样的条件下,用同一个游标卡尺测量铜棒的直径若干次,这就是等精度测量。对于等精度测量来说,还有一种更好的表示误差的方法,就是标准误差。
计算机建模
先产生一个随机样本,服从正态分布

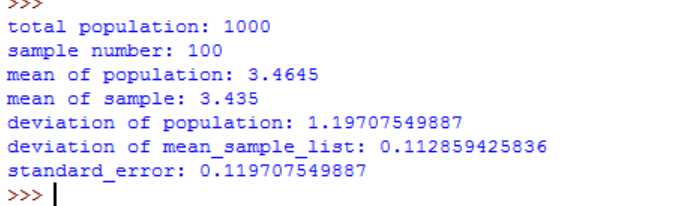
样本100时,标准误和样本平均值集合的方差几乎相同
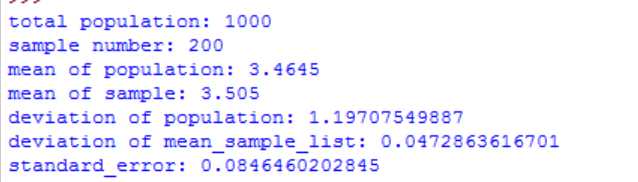
扩大样本到200时,标准误降低,但标准误和样本平均值集合的方差差距较大,但标准误大于真实值,比较安全。
#coding=utf-8
#中心极限理论抽象,不好理解,可简化成两个骰子建模
#从均值mean,方差variance的总体中,抽取样本量为n的随机样本,当n充分大时(n>=30),样本均值服从均值
#为mean,方差为variance/n的正太分布
import math,random,os,statistics_functions,draw,time,pylab,Population
#生成一个真随机数
#骰子选数范围从1-6
number_list=[1,2,3,4,5,6]
#n 表示重复次数,n是总体数量
population=Population.population
n=len(population)
#n=500
#样本数
sample_n=200
#分成份数
#length 表示列表内元素个数,length=2表示丢两颗骰子,length=6表示丢6颗骰子
length=2
def Random_number(number_list):
r=random.SystemRandom()
random_number=r.choice(number_list)
return random_number
#生成一个包含随机数的列表
#length表示列表内元素个数
def Random_list(length):
random_list=[]
for i in range(length):
random_number=Random_number(number_list)
random_list.append(random_number)
return random_list
#生成n个平均数
#元素是length个元素组成列表的平均数
def Mean_list(n1):
mean_list=[]
for i in range(n1):
random_list=Random_list(length)
mean=statistics_functions.Mean(random_list)
mean=round(mean,1)
mean_list.append(mean)
return mean_list
#返回不重复元素的列表
def List_noneRepeat(mean_list):
#去掉重复部分
list_noneRepeat=[]
for i in mean_list:
if i not in list_noneRepeat:
list_noneRepeat.append(i)
#print "list_noneRepeat:",list_noneRepeat
return list_noneRepeat
#频率计算函数
def Frequence(list_noneRepeat):
frequency=[]
#统计频率
for i in list_noneRepeat:
count=mean_list.count(i)
frequency.append(count)
return frequency
#时间测试
def time_test(n):
time3=time.time()
print time1
n
time4=time.time()
print time2
time_comsume=time4-time3
print time_comsume
def Draw_hist(mean_list):
pylab.hist(mean_list,50)
pylab.xlabel(‘X‘)
pylab.ylabel(‘frenquency‘)
pylab.title(‘Central limit theory‘)
pylab.show()
def Mean_sample_list(sample_list):
#所有样本平均数添加到一个列表中
mean_sample_list=[]
for i in sample_list:
mean=statistics_functions.Mean(i)
mean_sample_list.append(mean)
return mean_sample_list
def Analyse(sample_n):
print "total population:",n
print "sample number:",sample_n
print "mean of population:",mean_population
print "mean of sample:",mean_sample_list[0]
print "deviation of population:",deviation_population
print "deviation of mean_sample_list:",deviation_mean_sample_list
print "standard_error:",standard_error
#时间消耗测试
#总体
#population=Mean_list(n)
#总体的平均值
mean_population=statistics_functions.Mean(population)
#总体的标准差
deviation_population=statistics_functions.Deviation(population)
#样本
sample1=population[0:sample_n]
sample2=population[sample_n:2*sample_n]
sample3=population[2*sample_n:3*sample_n]
sample4=population[3*sample_n:4*sample_n]
sample5=population[4*sample_n:5*sample_n]
sample_list=[sample1,sample2,sample3,sample4,sample5]
#所有样本平均数添加到一个列表中
mean_sample_list=Mean_sample_list(sample_list)
#再计算这个列表中所有平均数的标准差
deviation_mean_sample_list=statistics_functions.Deviation(mean_sample_list)
standard_error=(deviation_population*1.0)/math.sqrt(sample_n)
#输出结果,以便观察
Analyse(sample_n)
标签:
原文地址:http://www.cnblogs.com/biopy/p/4915277.html