标签:
最近1 ~2年电商行业飞速发展,各种创业公司犹如雨后春笋大量涌现,商家通过各种活动形式的补贴来获取用户、培养用户的消费习惯;但任何一件事情都具有两面性,高额的补贴、优惠同时了也催生了"羊毛党"。
"羊毛党"的行为距离欺诈只有一步之遥,他们的存在严重破环了活动的目的,侵占了活动的资源,使得正常的用户享受不到活动的直接好处。
今天主要分享下腾讯自己是如何通过大数据、用户画像、建模来防止被刷、恶意撞库等的。会偏业务安全一些,有些组件,也会从逻辑、代码层面进行介绍。
"羊毛党"一般先利用自动机注册大量的目标网站的账号,当目标网站搞促销、优惠等活动的时候,利用这些账号参与活动刷取较多的优惠,最后通过淘宝等电商平台转卖获益。
他们内部有着明确的分工,形成了几大团伙,全国在20万人左右:
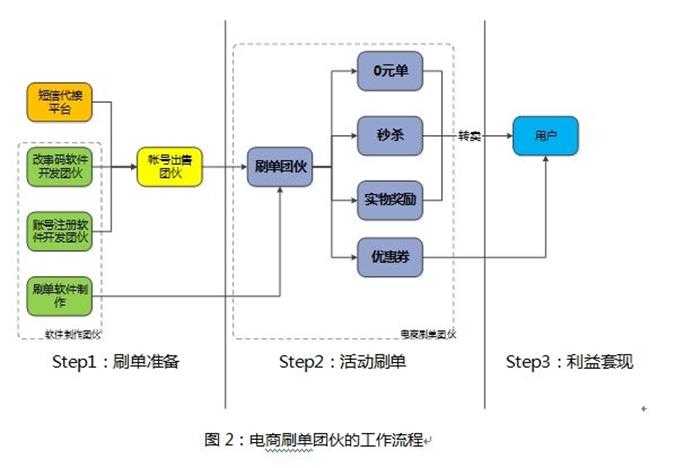
这些黑产团队,有三个特点:
对抗刷单,一般来讲主要从三个环节入手:
腾讯内部防刷的架构大概如下:
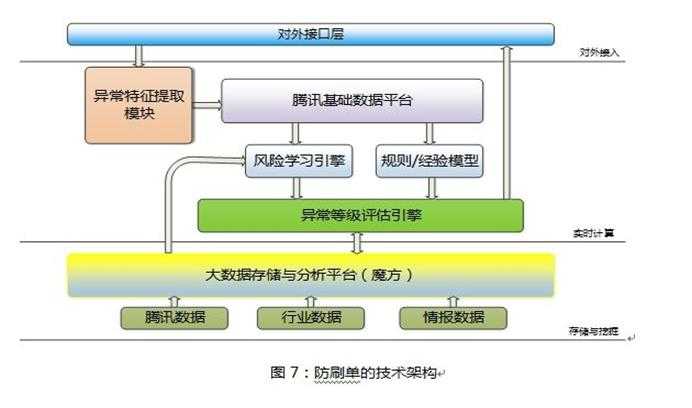
风险学习引擎:是利用python脚本来实现,训练和调优的大部分工作都在线下进行,线下分析完成之后会形成一个配置文件同步到线上系统,线上系统在check配置文件的有效性ok之后,才会启动更新。
线下我们一般在linux环境下通过crontab设定python脚本定时启动分析过程,训练完成之后会对比新老分类器的效果,如果新分类器在参数显著性检验、R^2、AIC等参数指标明显高于旧有分类器情况下就会启动更新,这种情况一般都是恶意模式发生了明显的变化。
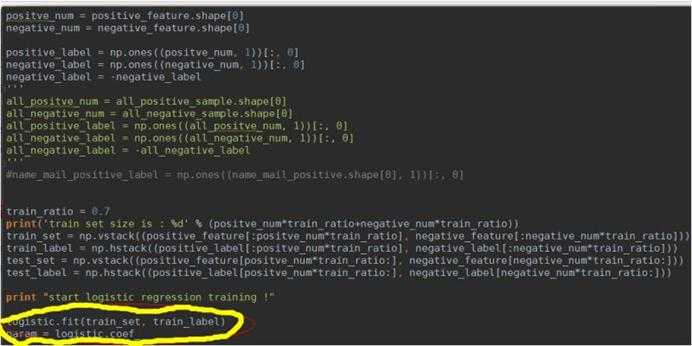
逻辑回归部分的python训练代码如下
风险学习引擎:效率问题,由于主要的工作都是线下进行,所以线上系统不存在学习的效率问题。线上采用的都是C++实现的DBScan等针对大数据的快速聚类算法,基本不用考虑性能问题。
线下一些机器学习的算法,比如层次聚类算法,随着样本的增加,训练的开销也呈指数级的增加:1W条记录需要20分钟左右训练时间(40维度特征)
因此,线下训练采用抽样的办法,每次随机抽取2W条记录,总共抽取5个批次(经验值),最终的模型参数是这个5个批次训练出来的均值。
风险引擎:采用了黑/白双分类器风险判定机制,之所以采用黑/白双分类器的原因就在于减少对正常用户的误伤。
例如,某个IP是恶意的IP,那么该IP上可能会有一些正常的用户,比如大网关IP
再比如,黑产通过ADSL拨号上网,那么就会造成恶意与正常用户共用一个IP的情况。
黑分类器:根据异常特征、通过机器学习算法,或者规则/经验模型来判断本次请求属于异常的概率;
白分类器:根据异常特征、通过机器学习算法,或者规则/经验模型来判断本次请求属于异常的概率。
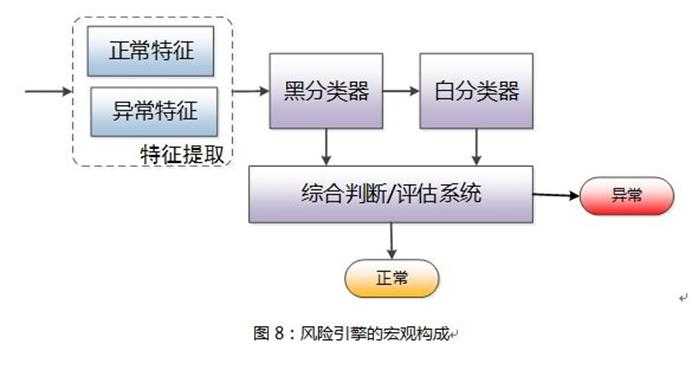
我们以黑分类器为例来剖析下分类器的整个逻辑框架
总的来讲我们采用了矩阵式的逻辑框架,最开始的黑分类器我们也是一把抓,随意的建立一个个针对黑产的检测规则、模型;
结果发现不是这个逻辑漏过了,那是那个逻辑误伤量大,要求对那一类的账号加强安全打击力度改动起来也非常麻烦;
因此我们就设计了这个一个矩阵式的框架来解决上述的问题。
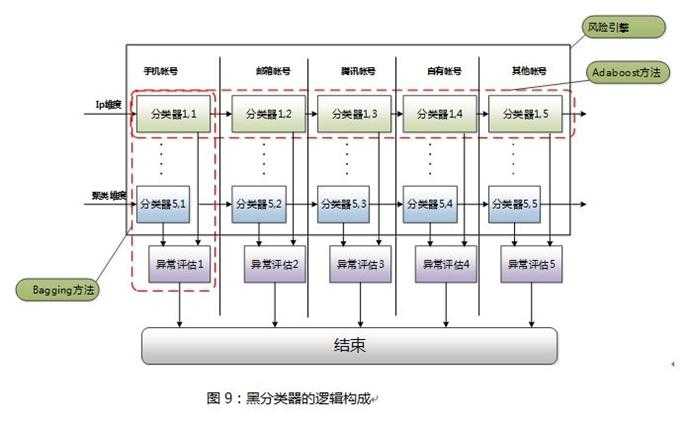
矩阵的横向采用了Adaboost方法,该方法是一种迭代算法,其核心思想是针对同一个训练集训练不同的弱分类器,然后把这些分类器集合起来,构成一个最终的分类器;
而我们这里每一个弱分类器都只能解决一种帐号类型的安全风险判断,集中起来才能解决所有账户的风险检测。
那么在工程实践上带来三个好处:
上面讲的部分东西理解起来会比较艰涩,这里大家先理解框架,后续再理解实现细节
而且,矩阵的横向有多个维度,比如IP维度、密码维度、路径维度、频率限制维度、层次聚类维度、DBScan维度等,这样一来相比单个维度作弊行为被漏检的概率更低,提高了召回率;
矩阵纵向采用了Bagging方法,该方法是一种用来提高学习算法准确度的方法,该方法在同一个训练集合上构造预测函数系列,然后以一定的方法将他们组合成一个预测函数,从而来提高预测结果的准确性。
我们以手机账号为例来说明下明下:
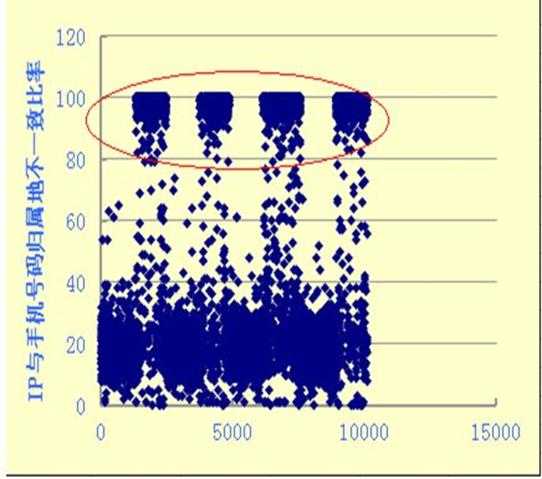
这张是散点图,横坐标无意义,纵坐标是IP与手机号码归属地不一致的比率,按照常识,不一致的比率越高,那么这种IP应该越少,也就是说在图上自底向上的点应该是逐渐稀疏,而该图在80%以上的区域有明显的聚集,不正常。
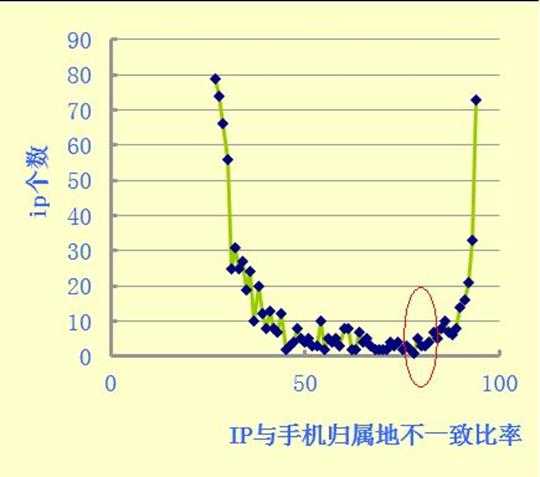
这张是IP统计图,横纵坐标的意义如图所示,一般正常情况下第二张图应该满足正态分布,图的尾部不应该往上翘,这个就是黑产通过自动机拨号的方式作恶的量比较大从而导致尾部曲线的拉升。
大数据一直在安全对抗领域发挥着重要的作用,从我们的对抗经验来看,大数据不仅仅是数据规模很大,而且还包括两个方面:
所以想要做风控和大数据的团队,自己一定要注意埋点拿到足够多的数据。
我们的团队研发了一个叫魔方的大数据处理和分析的平台,底层我们集成了mysql、mongodb,Spark、hadoop等技术,在用户层面我们只需要写一些简单的SQL语句、完成一些配置就可以实现例行分析;
这里我们收集了社交、电商、支付、游戏等场景的数据,针对这些数据我们建立一些模型,发现哪些是恶意的数据,并且将数据沉淀下来。
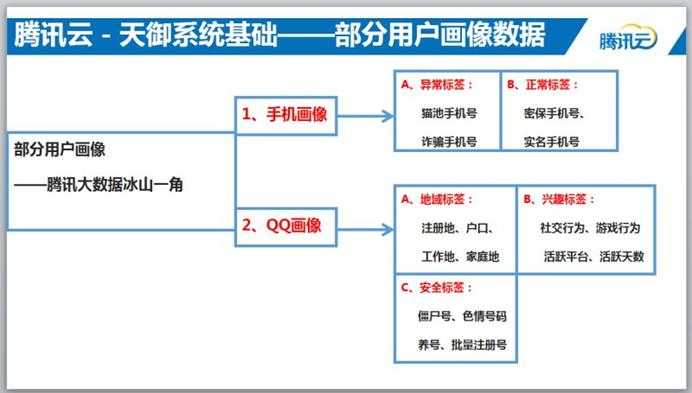
画像,本质上就是给账号、设备等打标签;
我们这里主要从安全的角度出发来打标签,比如IP画像,我们会标注IP是不是代理IP,这些对我们做策略是有帮助的;
以QQ的画像为例,比如,一个QQ只登录IM、不登录其他腾讯的业务、不聊天、频繁的加好友、被好友删除、QQ空间要么没开通、要么开通了QQ空间但是评论多但回复少,这种号码我们一般会标注QQ养号(色情、营销)。
类似的我们会采用一些逻辑发现QQ是不是工作室号码,仓库号等
画像等于打标签
所以这里可能大家有一个认识的误区,以为画像就是描绘图像
标签的类别和明细,需要做风控的人自己去设定,比如:地理位置,按省份标记。性别,安男女标记。其他细致规则以此规律自己去设定。
所以画像=标签
先来看看ip画像,沉淀的逻辑如下图
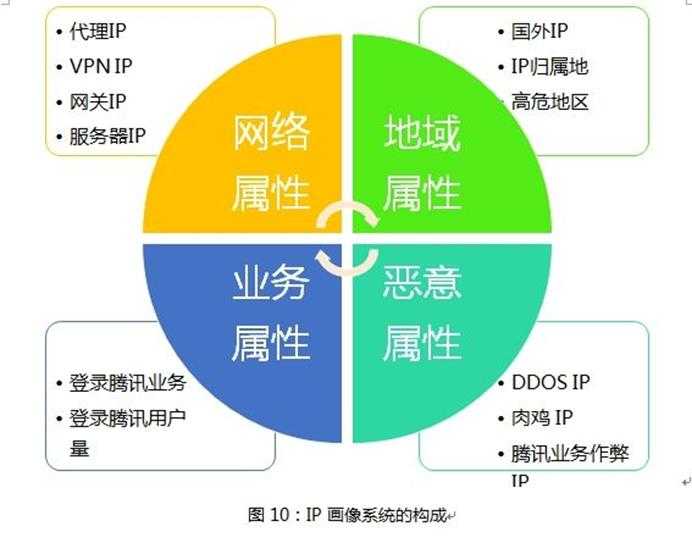
一般的业务都有针对IP的频率、次数限制的策略,那么黑产为了对抗,必然会大量采用代理IP来绕过限制。
既然代理IP的识别如此重要,那我们就以代理IP为例来谈下腾讯识别代理IP的过程。
识别一个IP是不是代理IP,技术不外乎就是如下四种:
以上代理IP检测的方法几乎都是公开的,但是盲目去扫描全网的IP,被拦截不说,效率也是一个很大的问题。
因此,我们的除了利用网络爬虫爬取代理IP外,还利用一下三种办法来加快代理IP的收集:
我们再看一下手机号(同时绑定QQ号)的画像
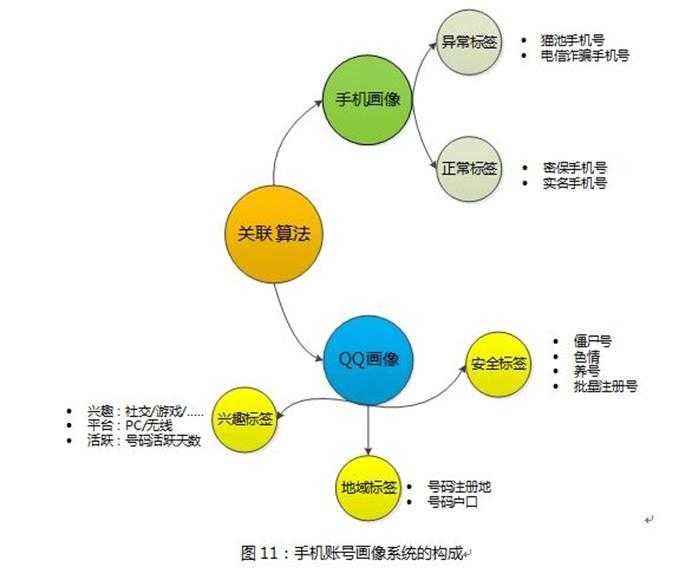
腾讯平台的业务,有比较多的场景需要关联用户的手机号码:比如,QQ帐号的密保手机等;我们分成两个方面来对手机号码进行画像:
比如,某IP上的手机号码关联的都是僵尸QQ,那么该IP上的这些手机号码属于恶意的概率比较大;
又比如,某IP上的手机号码关联的QQ都是非社交领域QQ(比如游戏),同样该IP属于恶意IP的概率也很大,因为一个不喜欢社交的账号,有理由相信其对电商也不会有太多的兴趣。
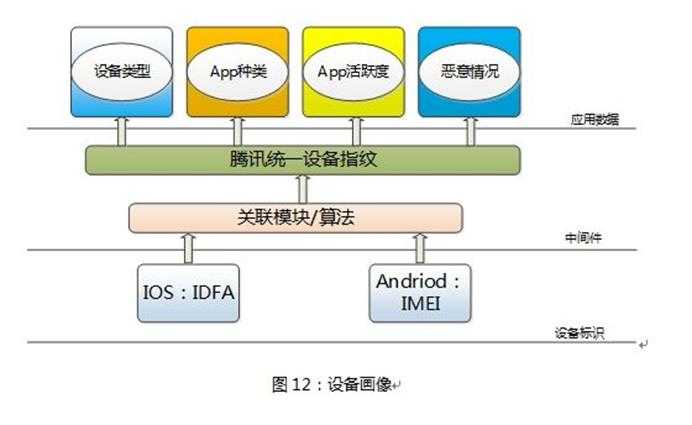
第三个是设备画像。
这主要是描述设备上安装App的情况,以及设备历史上是否有恶意行为。
设备画像的基本内容如下图12所示,由于这块跟手机账号画像内容差不多,所以就不做过多的阐述了。
前面我们说过,我们最终会根据逻辑回归来判定当前的风险概率。
风险概率<=0.5 对应我们的风险等级0,
0.5<风险等级>0.6对应等级1,
0.6<风险等级>0.7对应等级2,
0.7<风险等级>0.8对应等级3,
风险等级>0.8对应等级4;
经过我们人工核实发现,等级3 准确率在85%+,等级4准确率在90%左右,等级 1 &2它们的准确率相比较低,70%+;
核对模型的结果是否准确,理论上通过独立模型互验、交叉验证、人工审核等方式来进行;
比如,邮箱帐号可以通过肉眼看出来,手机帐号可以打电话的方式来验证;
另外,在腾讯自己的平台上,我们核实数据一般都采用交叉验证的方式,登录检测到的恶意数据跟业务侧发现的恶意数据、客服投诉举报数据、假客户端等数据做交叉验证。
实时系统使用c/c++开发实现,所有的数据通过共享内存的方式进行存储,相比其他的系统,安全系统更有他自己特殊的情况,因此这里我们可以使用"有损"的思路来实现,大大降低了开发成本和难度:
据一致性,多台机器,使用共享内存,如何保障数据一致性?其实,安全策略不需要做到强数据一致性;
从安全本身的角度看,风险本身就是一个概率值,不确定,所以有一点数据不一致,不影响全局。
但是安全系统也有自己的特点,安全系统一般突发流量比较大,我们这里就需要设置各种应急开关,而且需要微信号、短信等方式方便快速切换,避免将影响扩散到后端系统。
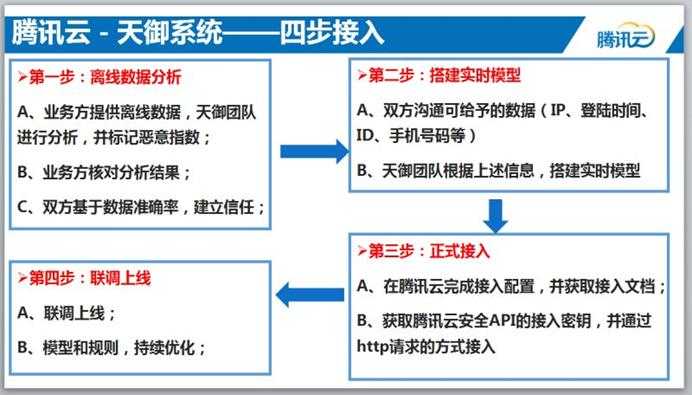
适应的场景包括:
1:电商o2o刷单、刷券、刷红包
2:防止虚假账号注册
3:防止用户名、密码被撞库
4:防止恶意登录

问题1:风险学习引擎是自研的,还是使用的开源库?
风险学习引擎包括两个部分,线上和线下两部分:
线上:自己利用c/c++来实现
线下:涉及利用python开源库来做的,主要是一些通用算法的训练和调优
问题2:都有哪些电商o2o使用这些系统?他们的访问量大概多少? 有什么特别复杂吗?可否简单指出一个?
京东、58、饿了么、聚美优品、携程、龙珠直播、微盟;
做活动的时候访问量较高,但是qps目前还不到一万
特别复杂的主要是在业务侧埋点获取数据、跑通实时模型流程、匹配风控规则。
问题3:请问魔方平台中用到的mongdb是不是经过改造?因为mongdb一直不被看好,出现问题也比较多
我们做了部分改造,主要是db的引擎方面
问题4:请问黑分类器和白分类器有什么区别?
白分类器主要用来识别正常用户,黑分类器识别虚假用户。
问题5:设备指纹算法 能说下不?
抱歉、这个属于腾讯集团涉密范围
问题6:风险概率的权重指标是如何考虑的?
标签:
原文地址:http://www.cnblogs.com/yufan27209/p/4920757.html