标签:
分给我的云服务器只有2台= = 所以只用两台来搭建~多台也就是多配几个slave节点木有关系的啦~那么下来开始啦
一、首先准备好编译过的hadoop2.6版本,以及相关jar包~准备开始搞啊~
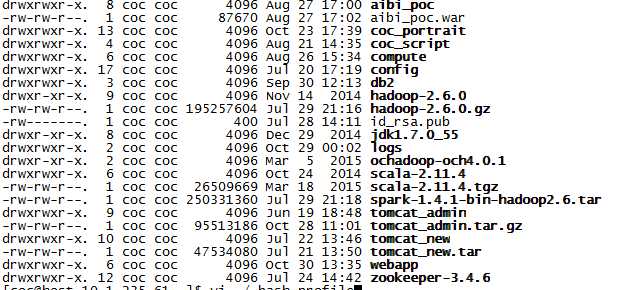
解压命令是 tar zxvf xxxxxxx(文件名)
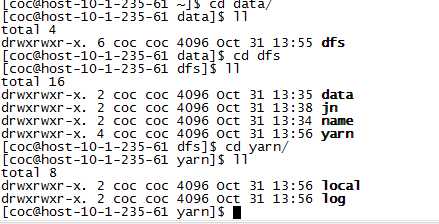
创建tmp路径 用于hadoop相关路径
mkdir tmp
在tmp下创建hadoop路径
mkdir hadoop
创建在根目录创建data路径 随后路径如图
二、配置环境变量
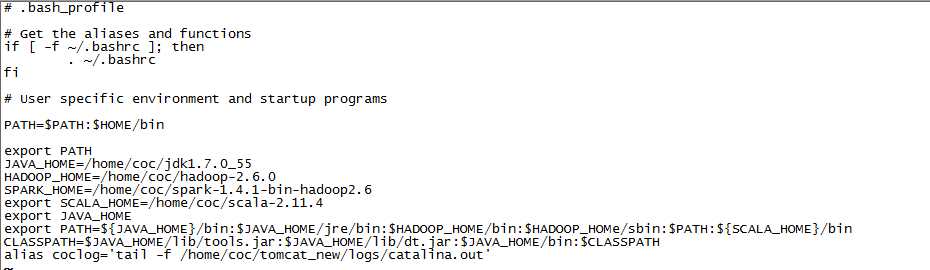
随后输入命令 source ~./bash_profile
修改host配置文件,配置主机hostname
vi /etc/hosts

三、修改hadoop配置文件
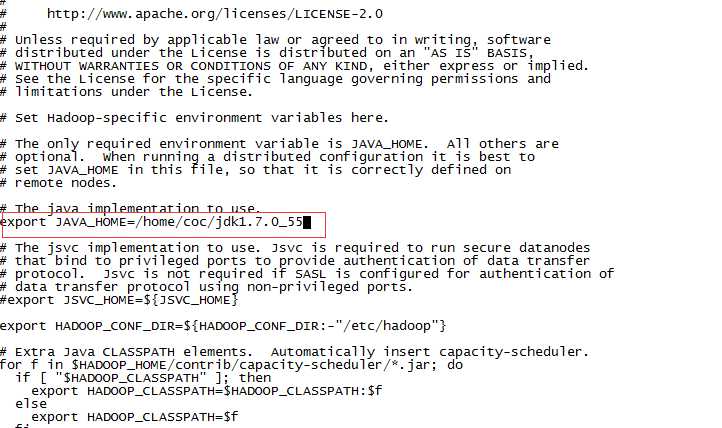
1.vi hadoop-env.sh
2.修改host 增加slave节点ip映射关系
3.修改core-site.xml 增加如下配置项

6、hdfs-site.xml中 增加如下配置项 (namenode,datanode端口和目录位置)
<configuration> <property> <name>dfs.nameservices</name> <value>streamcluster</value> <description> Comma-separated list of nameservices. </description> </property> <property> <name>dfs.datanode.address</name> <value>0.0.0.0:50012</value> <description> The datanode server address and port for data transfer. If the port is 0 then the server will start on a free port. </description> </property> <property> <name>dfs.datanode.http.address</name> <value>0.0.0.0:50077</value> <description> The datanode http server address and port. If the port is 0 then the server will start on a free port. </description> </property> <property> <name>dfs.datanode.ipc.address</name> <value>0.0.0.0:50022</value> <description> The datanode ipc server address and port. If the port is 0 then the server will start on a free port. </description> </property> <property> <name>dfs.nameservices</name> <value>streamcluster</value> </property> <property> <name>dfs.ha.namenodes.streamcluster</name> <value>nn1,nn2</value> <description></description> </property> <property> <name>dfs.namenode.name.dir</name> <value>//home/coc/data/dfs/name</value> <description>Determines where on the local filesystem the DFS name node should store the name table.If this is a comma-delimited list of directories,then name table is replicated in all of the directories,for redundancy.</description> <final>true</final> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/coc/data/dfs/data</value> <description>Determines where on the local filesystem an DFS data node should store its blocks.If this is a comma-delimited list of directories,then data will be stored in all named directories,typically on different devices.Directories that do not exist are ignored. </description> <final>true</final> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.permission</name> <value>true</value> </property> <property> <name>dfs.datanode.hdfs-blocks-metadata.enabled</name> <value>true</value> <description> Boolean which enables backend datanode-side support for the experimental DistributedFileSystem*getFileVBlockStorageLocations API. </description> </property> <property> <name>dfs.permissions.enabled</name> <value>false</value> <description> If "true", enable permission checking in HDFS. If "false", permission checking is turned off, but all other behavior is unchanged. Switching from one parameter value to the other does not change the mode, owner or group of files or directories. </description> </property> <property> <name>dfs.namenode.rpc-address.streamcluster.nn1</name> <value>oc98:8033</value> <description>鑺傜偣NN1鐨凴PC鍦板潃</description> </property> <property> <name>dfs.namenode.rpc-address.streamcluster.nn2</name> <value>oc62:8033</value> <description>鑺傜偣NN2鐨凴PC鍦板潃</description> </property> <property> <name>dfs.namenode.http-address.streamcluster.nn1</name> <value>oc98:50083</value> <description>鑺傜偣NN1鐨凥TTP鍦板潃</description> </property> <property> <name>dfs.namenode.http-address.streamcluster.nn2</name> <value>oc62:50083</value> <description>鑺傜偣NN2鐨凥TTP鍦板潃</description> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://oc61:8489;oc62:8489/streamcluster</value> <description>閲囩敤3涓猨ournalnode鑺傜偣瀛樺偍鍏冩暟鎹紝杩欐槸IP涓庣鍙/description> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/coc/data/dfs/jn</value> <description>journaldata鐨勫瓨鍌ㄨ矾寰/description> </property> <property> <name>dfs.journalnode.rpc-address</name> <value>0.0.0.0:8489</value> </property> <property> <name>dfs.journalnode.http-address</name> <value>0.0.0.0:8484</value> </property> <property> <name>dfs.client.failover.proxy.provider.streamcluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> <description>璇ョ被鐢ㄦ潵鍒ゆ柇鍝釜namenode澶勪簬鐢熸晥鐘舵€/description> </property> <property> <name>dfs.ha.fencing.methods</name> <value>shell(/bin/true)</value> </property> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>10000</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> <description> Whether automatic failover is enabled. See the HDFS High Availability documentation for details on automatic HA configuration. </description> </property> <property> <name>ha.zookeeper.quorum</name> <value>oc61:2183,oc62:2183</value> <description>2涓獄ookeeper鑺傜偣</description> </property> <property> <name>dfs.datanode.max.xcievers</name> <value>4096</value> </property> <property> <name>dfs.datanode.max.transfer.threads</name> <value>4096</value> <description> Specifies the maximum number of threads to use for transferring data in and out of the DN. </description> </property> <property> <name>dfs.blocksize</name> <value>67108864</value> <description> The default block size for new files, in bytes. You can use the following suffix (case insensitive): k(kilo), m(mega), g(giga), t(tera), p(peta), e(exa) to specify the size (such as 128k, 512m, 1g, etc.), Or provide complete size in bytes (such as 134217728 for 128 MB). </description> </property> <property> <name>dfs.namenode.handler.count</name> <value>20</value> <description>The number of server threads for the namenode.</description> </property> </configuration>
7、yarn-site.xml配置
<?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <!-- Site specific YARN configuration properties --> <!-- Resource Manager Configs --> <property> <name>yarn.resourcemanager.connect.retry-interval.ms</name> <value>2000</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.ha.automatic-failover.embedded</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-rm-cluster</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <description>Id of the current ResourceManager. Must be set explicitly on each ResourceManager to the appropriate value.</description> <name>yarn.resourcemanager.ha.id</name> <value>rm1</value> <!-- rm1涓婇厤缃负rm1, rm2涓婇厤缃畆m2 --> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.resourcemanager.zk.state-store.address</name> <value>oc61:2183,oc62:2183</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>oc61:2183,oc62:2183</value> </property> <property> <name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name> <value>5000</value> </property> <!-- RM1 configs --> <property> <name>yarn.resourcemanager.address.rm1</name> <value>oc61:23140</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>oc61:23130</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>oc61:23188</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm1</name> <value>oc61:23125</value> </property> <property> <name>yarn.resourcemanager.admin.address.rm1</name> <value>oc61:23141</value> </property> <property> <name>yarn.resourcemanager.ha.admin.address.rm1</name> <value>oc61:23142</value> </property> <!-- RM2 configs --> <property> <name>yarn.resourcemanager.address.rm2</name> <value>oc62:23140</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>oc62:23130</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>oc62:23188</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm2</name> <value>oc62:23125</value> </property> <property> <name>yarn.resourcemanager.admin.address.rm2</name> <value>oc62:23141</value> </property> <property> <name>yarn.resourcemanager.ha.admin.address.rm2</name> <value>oc62:23142</value> </property> <!-- Node Manager Configs --> <property> <description>Address where the localizer IPC is.</description> <name>yarn.nodemanager.localizer.address</name> <value>0.0.0.0:23344</value> </property> <property> <description>NM Webapp address.</description> <name>yarn.nodemanager.webapp.address</name> <value>0.0.0.0:23999</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value>/home/coc/data/dfs/yarn/local</value> </property> <property> <name>yarn.nodemanager.log-dirs</name> <value>/home/coc/data/dfs/yarn/log</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>0.0.0.0:12345</value> </property> <property> <name>yarn.application.classpath</name> <value> $HADOOP_CONF_DIR, $HADOOP_COMMON_HOME/share/hadoop/common/*, $HADOOP_COMMON_HOME/share/hadoop/common/lib/*, $HADOOP_HDFS_HOME/share/hadoop/hdfs/*, $HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*, $HADOOP_YARN_HOME/share/hadoop/yarn/*, $HADOOP_YARN_HOME/share/hadoop/yarn/lib/* </value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.4</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>6144</value> </property> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> </property> </configuration>
8、将配置信息拷贝到另一台机器上~
scp -r hadoop-2.6.0/ coc@10.1.235.62:/home/coc
9、在hadoop的bin目录下执行namenode和datanode的初始化
/bin/hdfs namenode -format
/bin/hdfs datanode -format
标签:
原文地址:http://www.cnblogs.com/yangsy0915/p/4925523.html