标签:
原文网址链接:http://url.cn/kVjUVO
众所周知,系统监控一直是拥有复杂IT架构的企业所面临的一个重要问题,而这也并不是每家企业都能够轻松解决的技术挑战。OPPO作为一家国际智能终端设备及移动互联网服务供应商,推出过多款外观精细、功能可靠的智能手机产品,其品牌知名度也一直名列前茅。但实际上OPPO公司与其他快速发展的现代企业一样面临着自己的IT挑战,而更加鲜为人知的,则是其品牌背后同样出色的IT团队与信息化支持能力。
OPPO后端系统规模近几年快速发展,系统重构以后采用了服务化的架构,各系统之间耦合降低,开发效率得到了很大的提升。然而在服务化带来了好处的同时,难于监控的问题也一并出现。由于服务之间调用关系错综复杂,接口出现问题,多个系统报错,因此很难定位真正的故障源头。整个请求调用链就像一个黑盒子,无法跟踪请求的整个调用路径,发现性能瓶颈点。
为了解决这些问题,OPPO公司自行开发了一套监控系统,并结合第三方监控系统,形成了从App请求开始到后端处理过程的完整监控体系。OPPO监控系统的简称为OMP(OPPO Monitor Platform),历时半年开发,分为两期上线,现在已全面接入OPPO线上项目。
三大理由决定自主研发
之所以选择自主研发监控系统,主要是考虑到三方面的原因:定制化需求、易用性、以及开发成本低。
首先,在对比之后发现现有的开源监控软件无法满足OPPO 的需求。对于监控系统来说最核心的一条需求,就是要能够监控每个App请求的完整调用链,从App发起请求,到后端的负载均衡接入、API Server、微服务调用、缓存、消息队列、数据库访问时间等。系统架构微服务化以后,服务跟踪和服务调用链监控尤为重要,否则系统故障及性能瓶颈就很难排查了。
为了打通用户请求的完整调用链,需要在API框架、RPC框架、缓存操作、数据库操作、队列消费等代码埋点,以及高性能处理和存储系统,而目前的开源软件无法满足需求,各大公司也因此才开发了自己的监控平台。由于服务调用跟踪功能跟开发框架深度关联,各公司选用的框架并不相同,所以业界鲜有类似开源的产品。
第二个原因是考虑到权限及一体化管理界面的需求。监控平台不仅仅面向运维人员,开发人员、运营人员、测试人员也需要经常使用。例如根据监控平台采集到JVM Young GC/Full GC次数及时间、耗时Top 10线程堆栈等信息,经常查看监控平台,开发、测试人员便可以评估代码质量,排除隐患。
监控平台面向用户众多,安全性及权限管理要求较高,同时需要一体化的管理界面,简洁易用,而组合多个开源软件,权限和管理便捷性很难满足需求。
第三,监控系统的开发难度比较低。自行研发的监控平台虽有千般好处,但是如果开发的难度太大,以至于无法持续的投入,那也是没有意义的。基于Sigar、kafka、Flume、HBase、Netty等技术,开发高性能、可伸缩的系统难度实际上并不大,需要投入的资源不需要很多。
六项目标内容实现线上应用全面监控
OMP的最终目标是提供一体化的监控系统,在同一套管理界面及权限体系之下,对线上应用系统进行多维度的监控。OMP现阶段主要监控内容包括:主机性能指标监控、中间件性能指标监控、服务调用链实时监控、接口性能指标监控、日志实时监控、业务指标实时监控。
主机性能指标监控方面的开源软件非常多,比如Zabbix、Cacti等。主要采集主机的CPU负载、内存使用率、各网卡的上下行流量、各磁盘读写速率、各磁盘读写次数(IOPS)、各磁盘空间使用率等。
借助开源的Sigar库,可以轻松采集主机信息,为了保证整个监控系统体验的一致性,以及系统扩展性、稳定性的要求,我们没有直接采用Zabbix等开源监控系统,而是自己开发Agent程序,部署在主机上采集信息。
Sigar(System Information Gatherer And Reporter),是一个开源的工具,提供了跨平台的系统信息收集的API。核心由C语言实现的,可以被以下语言调用: C/C++、Java 、Perl 、NET C# 、Ruby 、Python 、PHP 、Erlang 。
Sigar可以收集的信息包括:
CPU信息,包括基本信息(vendor、model、mhz、cacheSize)和统计信息(user、sys、idle、nice、wait);
文件系统信息,包括Filesystem、Size、Used、Avail、Use%、Type;
事件信息,类似Service Control Manager;
内存信息,物理内存和交换内存的总数、使用数、剩余数;RAM的大小;
网络信息,包括网络接口信息和网络路由信息;
进程信息,包括每个进程的内存、CPU占用数、状态、参数、句柄;
IO信息,包括IO的状态,读写大小等;
服务状态信息;
系统信息,包括操作系统版本,系统资源限制情况,系统运行时间以及负载,JAVA的版本信息等。
对于中间件性能指标监控,目前根据业务使用中间件的情况来看,主要采集的中间件包括Nginx、MySQL、MongoDB、Redis、Memcached、JVM、Kafka等。实现方式为部署独立的采集服务器,通过中间件的java客户端执行状态查询命令,解析出相应的性能指标,采集的部分指标如下表所示:
JVM |
堆内存、永久代内存、老年代内存、线程CPU时间、线程堆栈、Yong GC、Full GC |
MySQL |
慢查询、QPS、TPS、连接数、空间大小、表锁、行锁… |
Redis |
QPS、命中率、连接数、条目数、占用内存… |
Memcached |
QPS、命中率、占用内存、条目数、连接数… |
Nginx |
每秒请求数、连接数、keepalive连接数、持久连接利用率… |
系统架构微服务化以后,服务调用错综复杂,出了问题或性能瓶颈,往往很难定位。所以服务调用链实时监控极为重要。
服务调用链监控是从一个App发起请求开始,分析各环节耗时及错误情况,包括负载均衡接入、API Server耗时、微服务调用耗时、缓存访问耗时、数据库访问耗时、消息队列处理耗时等,以及各环节的错误信息,便于跟踪性能瓶颈及错误。
由于服务调用量巨大,同时便于管理员查看,监控系统不能存储所有请求的调用链,主要存储以下几种请求:
接口性能指标监控,主要监控接口的可用性和响应时间,由内部监控和外部监控两部分组成:
外部监控:外部监控由第三方公司负责,分为两种,一是App中埋点,采集真实的业务请求性能指标。二是通过第三方公司部署在各地的采集点,主动监控接口在各地区的可用性和性能指标。外部监控只能监控负载均衡器对外的最终接口服务地址的可用性和性能指标,如果要监控机房内部接口服务器,则需要机房内部部署第三方公司的Agent,这样会带来非常大安全风险,所以机房内部节点监控由内部监控完成。
内部监控:内部监控采用OMP,监控负载均衡层后面的接口服务器的可用性和性能指标,及时发现异常节点,同时OMP根据异常原因,回调业务系统提供的恢复URL,尝试恢复系统。
应用产生的日志分散在各应用服务器当中,由于安全管理非常严格,开发人员查看线上系统的日志非常不方便,同时日志内容匹配关键字需要发送告警通知相关人员。OMP将日志统一采集存储到Elastic Search集群,实现日志检索。OMP日志实时监控主要包括如下功能:
日志实时在线查看:监控平台可以实时查看日志文件的内容,效果类似tail –f 命令,同时屏蔽内容中的敏感信息(如密码等);
日志全文检索:全文检索日志内容及高亮显示;
关联日志查看:查看日志产生时刻,日志所属应用关联组件和应用的日志;
关键字告警:用户自己定义告警规则,符合匹配规则发送邮件和短信通知。
最后一项监控内容,是业务指标实时监控。除了监控系统主动采集的信息,还有业务层指标需要进行监控,如周期内订单数量、第三方数据同步结果等。这些业务层的指标数据,由各业务系统负责采集,然后上报到监控系统,监控系统完成图表展现及告警通知。
四大方面详解OPM系统设计
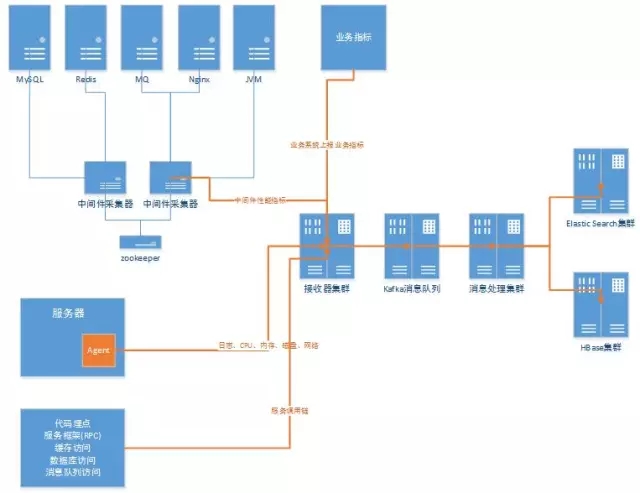
首先来了解一下OPM的系统体系架构,如下图所示:

中间件采集器:独立部署多台中间件性能指标采集器,通过Zookeeper实现故障转移和任务分配。中间件采集器通过中间件的Java客户端执行状态查询命令,解析命令结果得到性能指标,由于状态查询得到的是最新累计值,采集器还负责计算周期内的均值、最大值、最小值等周期数据。中间件采集将采集到的数据实时上报到接收器集群。
Agent监控代理:Agent监控代理部署在各服务器上,实时采集服务器的日志文件内容、CPU负载、内存使用率、网卡上下行流量、磁盘读写速率、磁盘读写次数(IOPS)等。Agent采集到的数据实时上报到接收器集群,对于日志文件,为防止阻塞,上传过程还需要做流控和丢弃策略。
代码埋点:代码埋点主要采集服务调用链数据,通过封装的缓存访问层、数据库访问层、消息队列访问层,以及分布式服务框架(RPC),获得服务调用链耗时和错误信息。代码埋点采集数据本机暂存,一分钟合并上报一次到接收器集群。
业务指标上报:业务指标由各业务系统负责采集,上报到接收器集群,上报周期和策略由各业务决定。
接收器集群:OPPO自研的Data Flow组件,架构参考Flume,内部包括输入、通道、输出三部分,将接收到的数据输出到Kafka队列,后文将作详细介绍。
Kafka消息队列:由于监控数据允许丢失和重复消费,所以选择高性能的Kafka做为消息队列,缓冲消息处理。
消息处理集群:消息处理集群订阅Kafka主题,并行处理消息,处理告警规则、发送通知、存储到HBase和ES。
Hbase:HBase存储指标类数据,管理控制台通过查询HBase生成实时图表。
Elastic Search:存储日志内容,实现日志全文检索。
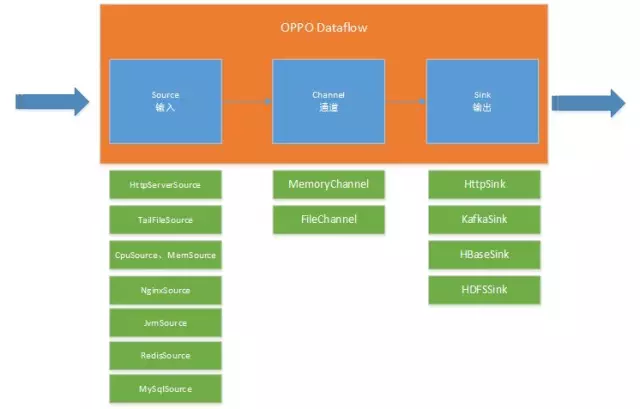
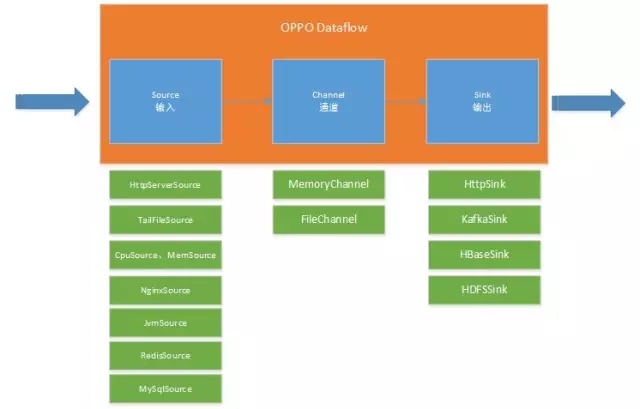
OPPO Data Flow实现了数据流配置和管理,设计参考Flume,内部包括Source(输入)、通道(Channel)、输出(Sink)三部分,通道是一个队列,具备缓冲数据的功能。之所以不采用Flume,主要考虑如下几个原因:
Flume提供了良好的SourceàchannelàSink框架,但具体的Source、Sink需要自己去实现,以兼容oppo线上使用软件版本,以及优化的参数配置。
Flume资源占用较大,不适合作为Agent部署在业务服务器
Flume配置文件采用properties方式,不如xml配置直观,更不能管理界面来配置。
Flume管理界面不友好,不能查看输入、输出的实时流量图表以及错误数量。
参考Flume 的设计思想,OPPO Data Flow是更易管理、配置更便捷的数据流工具。使用开源软件,并不只是拿来就用这一种方式,学习其设计精华,从而进一步改进也是一种方式。
实际上,Agent监控代理、中间件采集器、接收器集群都是OPPO Data Flow组件,组合不同的Source和Sink。Source、Sink采用OSF服务框架开发,实现Agentà接收器的自动发现、负载均衡及故障转移功能。
|
输入(Source) |
通道(Channel) |
输出(Sink) |
Agent监控代理 |
TailFileSource CPUSource MemorySource NetworkSource DiskSource |
MemoryChannel |
HttpSink |
中间件采集器 |
NginxSource MySqlSource MongoDBSource RedisSource JvmSource MemcachedSource |
MemoryChannel |
HttpSink |
接收器 |
HttpSource |
FileChannel |
KafkaSink |
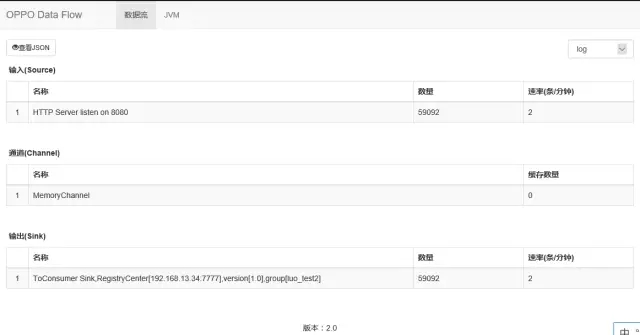
下图为Data Flow内嵌管理界面,可以查看数据流量和错误信息,点击名称可以查看历史流量。

服务调用链是监控的重点,核心的核心,为了打通服务调用链,OPPO开发了OSF(OPPO Service Framework)分布式服务框架,并对缓存、数据库、消息队列操作进行封装埋点,目的是透明的实现服务调用跟踪。实现方式如下:
在App请求的入口生成唯一requestID,放入ThreadLocal
缓存访问层代码埋点,从ThradLocal取出requestID,记录缓存操作耗时
数据库访问层代码埋点,从ThradLocal取出requestID,记录数据库操作耗时
调用其它微服务 (RPC),将requestID传递到下一个微服务,微服务将接收到的requestID存入ThreadLocal,微服务内部的缓存、数据库操作同样记录requestID操作耗时及错误信息。
消息队列写入、消费代码埋点,传递requestID,记录消息消费耗时。
调用链数据庞大,无法全量存储,监控系统将周期内最慢Top1000请求,采样的部分请求以及符合关键字规则请求的服务调用链存储在HBase中,管理控制台可以快速分析查看。
分布式服务框架是打通服务调用链的关键。开源的Dubbo应用广泛,考虑到Dubbo版本较长时间没有更新(有些Dubbo依赖库已经跟开发生态的其他开源组件版本冲突)、代码量较大,而且服务治理能力较弱,很难完全掌控Dubbo的所有细节,而前文提到的OPPO自行开发的分布式服务框架OSF,代码精简满足核心需求,与监控系统深度集成。
OSF实现微服务RPC调用requestID的传递,记录每个服务的调用耗时及错误信息,框架每分钟汇总上报微服务调用耗时及错误信息到监控平台。
OSF主要特性如下:
由消费方决定序列化方式:
注册中心基于MySQL,同时提供推送、client拉取两种方式,保证服务发现可靠性;
注册中心提供HTTP API,支持多语言、移动设备;
支持多数据中心部署;
I/O线程与工作线程池分离,提供方忙时立即响应client重试其它节点。

从可靠性及伸缩性角度来看,主要包括以下内容:
接收器:接收器的输入采用OSF RESTFul协议开发,通过注册中心,client能够自动发现接收器节点的变化,通过client实现负载均衡及故障转移,从而保证接收器的可靠性、伸缩性。
中间件采集器:中间件采集器通过zookeeper选举Master,由Mater来分配采集任务,采集器节点变化,选举的Master重新分配采集任务,这样任意增减采集器节点,都能重新平衡采集任务,保证采集任务的持续可靠运行。
消息处理:由于多个节点均分同一个kafka topic的消息并且实现高可用比较困难,OMP预先定义了若干个kafka topic,消息处理节点通过zookeeper选举Master,由Master来分配Topic数量,当某个消息处理节点宕机,该节点负责的topic转移到其他节点继续处理。
Agent监控代理:服务器上shell脚本定期检查Agent状态,不可用时自动重启Agent,同时OMP维持与Agent之间的心跳消息,超过3个周期没有收到Agent的心跳消息,OMP发送告警通知相关人员处理。
从OPPO的自主研发监控系统的实践案例来看,一切应当从业务需求出发,目的是解决业务遇到的问题。面对开源软件的选择,要有所“为”,有所“不为”。业界有很多成熟的开源软件,也有一些比较大胆的设计思想可供借鉴,但开源软件并不是拿过来就能用好这么简单的,选择的原则可“管”可“控”。一个开源软件,如果不能“掌控”,不够简单,那就不如不用,自己用土办法也许反而会更好,出了问题至少还能想想应急的办法。同样要具备“管理”性,不然黑盒子般运行,心里没底,那作为IT管理人员来说就睡不安心了。
本文作者罗代均 ,现就职于OPPO基础技术团队,从事监控平台、服务框架等基础技术开发工作。2005年毕业后,先后主导过通信、移动金融、应用商店、PaaS平台等领域多个产品系统设计开发、项目管理工作。本文由作者授权由InfoQ公众平台独家首发。
案例|服务化架构系统监控难题解决方案
标签:
原文地址:http://my.oschina.net/agileai/blog/524745