标签:
郑昀编著,文字资料来自于张帆、白俊华、刘飞宇以及网络资料 创建于2015/10/21 最后更新于2015/10/29
关键词:Docker,容器,持续集成,持续发布,CI,私有云
本文档适用人员:广义上的技术人员
提纲:
- 集装箱还是卷挂载?
- Host Networking 还是 Bridge Networking?
- 容器要固定IP吗?
- 容器内部如何获取宿主机的IP?
- 待续
首先,你要明白容器并不是虚拟机,虽然它可以解决虚拟机能够解决的问题,同时也能够解决虚拟机由于资源要求过高而无法解决的问题,但它真的不是虚拟机。以往我们的开发、配置管理、部署发布、监控报警思路都要跟着变。
其次,一开始注定只有一少部分工程迁移到容器私有云上,既然还有大多数应用服务还在虚拟机或物理机上,那么它们之间如何通讯就成了一个必须解决的问题。
那么,我们在构建基于容器的私有云以及相应的持续发布时,遇到并解决了哪些问题呢?
0x00 集装箱还是卷挂载?
先抛出问题,下面这个选择题你怎么选:
- 代码不放入 Image(镜像) 里,而是放在 Volume(卷) 上,这样镜像只需要维护程序运行的环境(如 Resin+JDK1.7)即可,准备几种 Java、PHP、Python 运行时环境的镜像即可,不同的应用运行不同的容器挂载不同的代码;
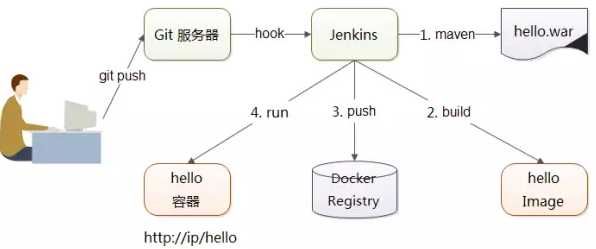
- 代码打包放入 Image 里,典型场景如下图(图源自出处3)所示:
|
我们再来看一下 Docker 的 Logo,它隐含天机:
一艘鲸鱼大船,载着无数集装箱。操作系统就是这艘货轮,每一个容器就是一个集装箱,交付运行环境如同海运。大家知道吗,集装箱的英文单词就是 container!
集装箱有什么好处?
- 规格标准,在港口和船上可以层叠摆放,节省大量空间,
- 可以进行快速装卸,并可从一种运输工具方便地换装到另一种运输工具,
- 途中转运不用移动箱内货物,就可以直接换装,
- 货物的装满和卸空很方便。
那么,上面的选择题如何回答呢?
触控科技运维负责人萧田国认为,把代码放在宿主机上,让容器通过卷组映射来读取,不建议采用这种方案,原因是,将代码拆分出容器,这违背了 Docker 的集装箱原则:
- 从货运工人角度考虑,整体才是最经济的。
- 这也导致装卸复杂度增加。
或者说,容器时代,一切版本化,抛弃过去文件分发的思想,才是正途,这样也才能实现真正意义上的容器级迁移。
我们是怎么考虑的呢?
假定是代码和 Image 分开的场景,主要有两种实现方式:
- 代码放到 slave 节点的本地磁盘:那么必须要有一种机制,来确保每台 slave 上代码包版本的一致性,而且对于磁盘空间和网络分发来讲也是一种浪费(考虑一下 100 台 slave,其中可能只有 10 台需要运行这个版本的代码)
- 代码放到分布式共享文件系统(如 ceph):它倒是解决了数据过度冗余以及一致性的问题,但分布式共享文件系统本身成为了『单点』,虽然可以设置多个副本。它的性能和可靠性都必须得到充分保障才行。
在容器云之前,我们采用的是基于 OpenStack 的虚拟机管理方案。在线下环境用 OpenStack 时,我们将所有的虚拟机放置到 ceph(注:Linux PB 级分布式文件系统) 上,但是由于线下 ceph 节点太少,单节点出问题时影响较大。每次 ceph 出现问题,所有的虚拟机都特别慢。
来到了容器时代,如果还把代码放置到 ceph 上,对 ceph 的依赖太高了,ceph 一旦有问题,有可能使用了 ceph 的所有容器都会出问题 。线上业务主要考虑的是性能(容器本地运行代码 vs 通过网络获取代码)和可靠性(每个 slave 都本地运行容器 vs 所有容器依赖共享文件系统),结论不言而喻。所以一开始决策时,没敢把代码放在 ceph 上,而是放在镜像里。所以我们选的是方案2,代码在镜像里。
在我们的场景里,镜像会被下载到 mesos slave 物理机的本地磁盘上,所以启动容器时读的是本地磁盘。
多说一句,Qunar 等公司在2014年选择的是卷挂载方案,业界也有人认为,这事儿得分环境具体问题具体分析,开发集成环境和生产环境可能就不一样。
0x01 Host Networking 还是 Bridge Networking?
网络基础
Docker 现有的网络模型主要是通过使用 Network namespace、Linux Bridge、iptables、veth pair 等技术实现的。(
出处8)
- Network namespace:它主要提供了网络资源的隔离,包括网络设备、IPv4/IPv6 协议栈、IP 路由表、防火墙、/proc/net 目录、/sys/class/net 目录、端口(socket)等。
- Linux Bridge:功能相当于物理交换机,为连在其上的设备(容器)转发数据帧,如 docker0 网桥。
- Iptables:主要为容器提供 NAT 以及容器网络安全。
- veth pair:两个虚拟网卡组成的数据通道。在 Docker 中,用于连接 Docker 容器和 Linux Bridge。一端在容器中作为 eth0 网卡,另一端在 Linux Bridge 中作为网桥的一个端口。
容器的网络模式
用来设置网络接口的 docker run --net 命令,它的可用参数有四个:
- none:关闭了 container 内的网络连接。容器有独立的 Network namespace,但并没有对其进行任何网络设置,如分配 veth pair 和网桥连接,配置 IP 等。
- bridge:通过 veth 接口来连接其他 container。这是 docker 的默认选项。
- host:允许 container 使用 host 的网络堆栈信息。容器和宿主机共享 Network namespace。
- container:使用另外一个 container 的网络堆栈信息。kubernetes 中的 pod 就是多个容器共享一个 Network namespace。
我们需要从中选一个作为我们的网络方案,实际上只有 bridge 和 host 两种模式可选。(想了解这四个参数,请翻到附录B之 Network settings。)
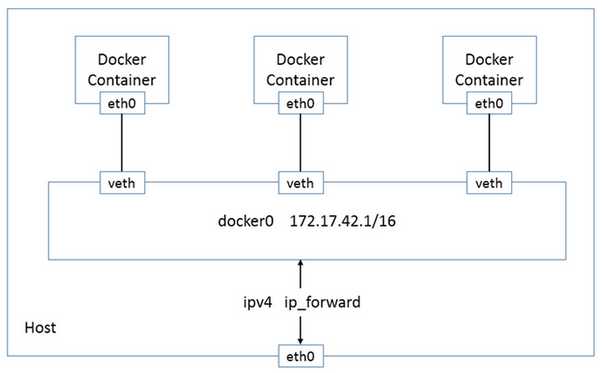
在 docker 默认的网络环境下,单台主机上的容器可以通过 docker0 网桥直接通信,如下图(图作者冯明振)所示:
而不同主机上的容器之间只能通过在主机上做端口映射进行通信。这种端口映射方式对集群应用来说极不方便。(出处8)我们重点要解决这个问题。
先看一下其他学生怎么做这道选择题的:
|
公司
|
网络方案
|
备注
|
|
网易(2014)
|
tinc+quagga+pipework
|
Pipework 是对 Docker Bridge 的扩展,它由 200 多行 shell 脚本实现。通过使用 ip、brctl、ovs-vsctl 等命令来为 Docker 容器配置自定义的网桥、网卡、路由等。
|
|
CoreOS(2014)
|
flannel
|
flannel 属于隧道方案,UDP 广播,VxLan。
|
| 大众点评网(2015) |
Bridge Networking 工作在 level 2 的模式,使公共 IP 得以暴露出来,这部分是做了定制的
|
|
| 汽车之家(2015) |
Bridge Networking
|
|
|
去哪儿(2015)
|
Host Networking
|
『大吞吐量平台下,bridge 模式性能测试都偏低,于是选择了 host 模式』——20150915,徐磊
|
|
芒果TV(2015)
|
Macvlan
|
属于路由方案。『从逻辑和 Kernel 层来看隔离性和性能最优的方案,基于二层隔离,所以需要二层路由器支持,大多数云服务商不支持,所以混合云上比较难以实现』——20150505,彭哲夫
|
|
新浪微博(2015)
|
Host Networking
|
|
先说一下 host 模式。
容器的网络直接和外部网络打通,解决了不同 slave 物理机之间容器互联互通的问题,减少了 NAT 转换的损耗,但需要自行来维护容器的 IP 地址和端口,否则会冲突,这增加了管理上的复杂度。请考虑这个场景:在同一个 slave 物理机上运行两个 80 端口 Nginx 容器的情况,除非分配两个不同的 IP 地址,这种方案我们之前在 shipyard 方案中使用过。
Docker 部署被诟病最多就是网络,平台目前采用的是 host 模式,为什么没有采用 NAT 或者 Bridge 呢?由于涉及的技术细节比较繁冗,这里仅分享一些踩过的坑。例如 NAT 使用 iptables 底层流量转发依靠内核 netfilter 模块,其默认仅保持 65536 个链接,在服务有大量链接的场景下,会出现大量拒绝链接的现象。再如 Bridge 的 MAC 地址默认是选择其子接口中最先的一个,这样就会导致一个宿主机下多个容器启停时出现网络瞬断。还有很多问题不一一列举,平台未来计划采用 vlanif 的方案来解决容器网络部署难题。
再看 bridge 模式,它是 docker 默认的网络模式,为了解决容器间互通问题,通常有两种解决方案:
- 采用 SDN(软件定义网络) 技术,如 flannel,weave 等,直接将容器内网打通;
- 采用 NAT(网络地址转换) 技术,直接使用 slave 主机的 IP 地址互通。
我们认为,bridge 模式加 NAT 方式,是当前 mesos+marathon 支持的最好的模式(采用的是 container port,host port,service port 的对应关系)。我们的容器云主要构建于 mesos+marathon 之上,封装了我们的业务逻辑,采用一些方式解决了容器与现存非容器架构之间的互通问题, 如 consul 的服务注册和发现机制,dubbo 的应用注册和发现机制等。
最终我们选择了 Bridge Networking。
Libnetwork 是 Docker 官方 2015年初推出的项目,旨在将 Docker 的网络功能从 Docker 核心代码中分离出去,形成一个单独的库。 Libnetwork 以插件的形式为 Docker 提供网络功能,使得用户可以根据自己的需求实现自己的 Driver 来提供不同的网络功能。 Libnetwork 所要实现的网络模型基本是这样的: 用户可以创建一个或多个网络(一个网络就是一个网桥或者一个 VLAN ),一个容器可以加入一个或多个网络。 同一个网络中容器可以通信,不同网络中的容器隔离。 Docker 网络的发展以后就都在这个项目上了。
0x02 容器要固定IP吗?
默认情况下,当 docker 启动时,它会在宿主机器上创建一个名为 docker0 的虚拟网络接口。它会从 RFC 1918 定义的私有地址中随机选择一个主机不用的地址和子网掩码,并将它分配给 docker0。(出处9)所以,容器的 IP 是动态变化的。
于是乎大家一开始接触 Docker 就纷纷提出给容器分配静态 IP 的需求。看一下
各大公司容器云技术栈对比,几家历史包袱较重的公司都选择不让上层应用感知到底层是 VM 还是容器,如360/点评/汽车之家,都改了docker 代码,固定了容器 IP。
docker 官方对此需求的态度是,Docker maintainers prefers a more abstract way to separate user intent from operational intent. Based on this feedback and various other discussions on a flexible ip address management, we feel that having a pluggable IPAM will help a great deal.
上一章节里提到的
Pipework 可以做到让容器有一个可以直接访问的静态 IP 地址,just like this:
If you’re using named Docker instances, then adding the IP address 10.40.33.21 to a Docker instance bind is as simple as:
pipework br0 bind 10.40.33.21/24
If you want to route out of 10.40.33.1, change it to:
pipework br0 bind 10.40.33.21/24@10.40.33.1
(出处:https://opsbot.com/advanced-docker-networking-pipework/)
|
这样的话,需要在容器启动后在宿主机上运行 pipework 来设置容器的 ip,这样就增加了自动化的难度。
我们的考虑是,第一,容器应该是无状态的,分配固定 IP 违背了这个理念,第二,Docker 刚出来一两年,还在飞速发展中,现在你改了内核代码,将来它大版本升级,你怎么跟随?第三,使用固定 IP 很大程度上是为了让技术人员能像以前一样直接登录虚拟机操作,但我们的持续集成管理平台里使用 webconsole 也能登到容器里面操作。
我们的实践是:首先,我们内部调用都走内部域名,有专门的 DNS Server,其次,我们很早以前就引入了服务治理框架 Dubbo,基本做到了服务的注册和发现。再次,我们在容器云里引入了 consul 的注册和发现服务,配合 slave 节点上的 registrator 容器,以及 haproxy 和 consul-template 组件,实现了完整的容器服务的注册和发现架构。
第一,dubbo 能帮我们解决什么容器问题:
进驻容器云后 java 工程之间的调用:直接将物理机的 ip 和容器 java 工程对外提供的随机端口,注册到 dubbo 里。例如, 容器 javaA 要调用容器 javaB,容器 javaB 已经将它对外提供的 ip 和随机端口注册到了 dubbo 里,容器 javaA 可以从 dubbo 里找到容器 javaB 相关的信息直接调用。
第二,dubbo 不能解决的问题有:
- 我们的线上还有 php 或者其他开发语言的应用,它怎么调用容器化的 java 工程呢?
- 容器化的工程如何对外网提供服务 ,如何把它放入 nginx 和 F5中呢?
基于以上两个需求、以及同一个工程的容器也要做负载均衡 ,我们引入了 consul + consul-template + registrator + haproxy,来做服务注册和发现。
实施详细流程如下:
第一步,每一台 slave 节点上都会启动一个 registrator 的容器,该容器检测 docker 引擎的 unix socket 地址:/var/run/docker.sock,从中获得该 slave 上所有容器的启动、停止以及其他运行时相关的信息;
第二步,registrator 容器同时会把它获取的其他容器的信息(IP、端口等)注册到 consul 集群中,服务信息如下面的输出:
curl 172.28.128.3:8500/v1/catalog/service/python-micro-service
"Address":"172.28.128.3",
"ServiceID":"registrator:service1:5000",
"ServiceName":"python-micro-service",
第三步,consul-template 组件从 consul 中获得所有容器注册的服务信息,应用相应的规则(如,区分为镜像环境和生产环境)后,将容器提供的服务信息写入 haproxy 中,并 reload haproxy 以生效配置。
第四步,client 端通过 DNS 中注册的域名指向 haproxy 的地址,访问到具体提供服务的容器。
0x03 容器内部如何获取宿主机的IP?
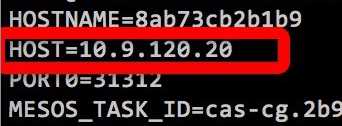
容器启动后,宿主机 IP 会被写入容器的环境变量里。
容器内的程序可以从环境变量里读取。
——未完待续——
附录A:参考资源
3,2015,Docker持续部署图文详解;
附录B:术语简单介绍
|
Registry/Repository/Image/Tag:
Registry 存储镜像数据,并且提供拉取和上传镜像的功能。Registry 中镜像是通过 Repository 来组织的,而每个 Repository 又包含了若干个 Image。
- Registry 包含一个或多个 Repository
- Repository 包含一个或多个 Image
- Image 用 GUID 表示,有一个或多个 Tag 与之关联
比如,你在本地机器上运行 docker image 命令,可能会得到这样的输出结果:
我们常说的“ubuntu”镜像其实不是一个镜像名称,而是代表了一个名为 ubuntu 的 Repository,同时在这个 Repository 下面有一系列打了 tag 的 Image,Image 的标记是一个 GUID,为了方便也可以通过 Repository:tag 来引用。
——《玩转Docker镜像,2014,孙宏亮》
|
|
Network settings:
docker run --net 的四个参数进一步解释如下:
None:
将网络模式设置为 none 时,这个 container 将不允许访问任何外部 router。这个 container 内部只会有一个 loopback 接口,而且不存在任何可以访问外部网络的 router。
Bridge:
默认为 bridge 模式。此时在 host 上面将存在一个 docker0 的网络接口,同时会针对 container 创建一对 veth 接口。其中一个 veth 接口是在 host 充当网卡桥接作用,另一个 veth 接口存在于 container 的命名空间中,并且指向 container 的 loopback。docker 会自动给这个 container 分配一个 IP,并且将 container 内的数据通过桥接转发到外部。
如下图(图作者冯明振)所示:
容器 eth0 网卡从 docker0 网桥所在的 IP 网段中选取一个未使用的 IP,容器的 IP 在容器重启的时候会改变。docker0 的 IP 为所有容器的默认网关。容器与外界通信为 NAT。
Host:
此时,这个 container 将完全共享 host 的网络堆栈。host 所有的网络接口将完全对 container 开放。container 的主机名也会存在于 host 的 hostname 中。这时,container 所有对外暴露的 port 和对其它 container 的 link,将完全失效。
Container:
此时,这个 container 将完全复用另一个 container 的网络堆栈。
|
附录C:
目前,我们容器管理集群的技术栈包括以下内容:
- mesos(资源调度)
- marathon(服务编排)
- chronos(分布式计划任务)
- docker(容器引擎)
- consul+registrator(服务注册和发现)
- haproxy(负载均衡)
- prometheus(服务监控)
- nagios/zabbix(节点监控)
- salt(节点配置管理)
- cobbler(节点自动化装机)
- ELK(日志收集分析)
窝窝持续集成管理平台在这些技术的基础上,实现了我们的集群管理、容器管理、应用管理等业务流程。
欢迎订阅我的微信订阅号『老兵笔记』,请扫描二维码关注:
-EOF-
基于Docker的持续发布都要解决哪些问题 第一集
标签:
原文地址:http://www.cnblogs.com/zhengyun_ustc/p/dockernow.html