标签:
什么是聚类(clustering)
个人理解:聚类就是将大量无标签的记录,根据它们的特点把它们分成簇,最后结果应当是相同簇之间相似性要尽可能大,不同簇之间相似性要尽可能小。
聚类方法的分类如下图所示:
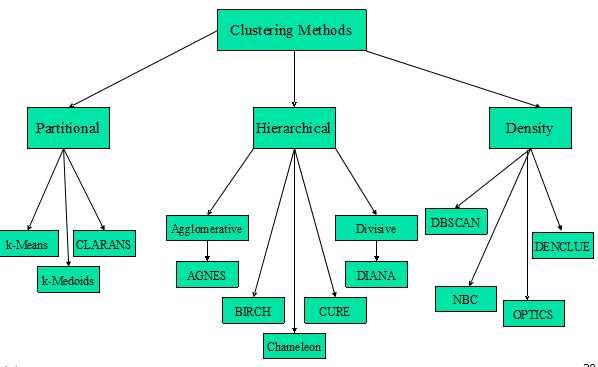
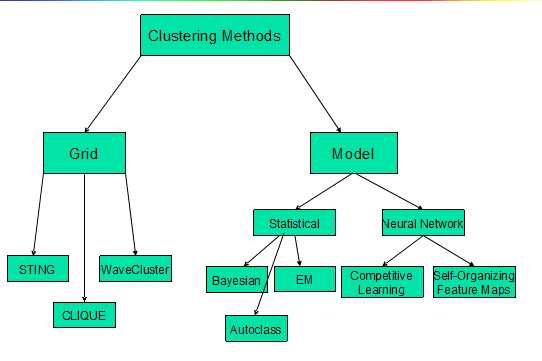
一、如何计算样本之间的距离?
样本属性可能有的类型有:数值型,命名型,布尔型……在计算样本之间的距离时,需要将不同类型属性分开计算,最后统一相加,得到两个样本之间的距离。下面将介绍不同类型的属性的数据计算方法。
对于全部都是连续的数值型的样本来说,首先,对于值相差较大的属性来说,应该进行归一化,变换数据,使其落入较小的共同区间。
标准化的方法:
1.最大-最小规范化

其中Vi 表示在第i条记录在A这个属性上的取值,MINA表示A这个属性上的最小值,new_maxA表示我们希望映射到的区间的右边界,其他同理。
2. Z-score 规范化

其中两个参数分别表示均值和方差。
3. 小数定标规范化
通过移动属性A的小数点位置进行规范化。小数点移动位数依赖于A的最大绝对值。
在进行规范化之后,就可以计算两个样本之间的距离了,计算公式如下:
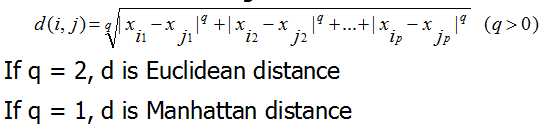
如果每个属性有不同的权重,公式修改如下:
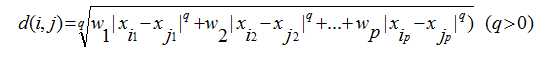
对于全是布尔型的样本来说,计算方式如下:
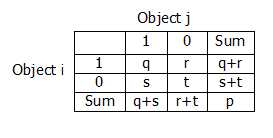
上表表示对与不同的样本i,j,统计它们布尔型同时为1的属性个数,同时为0的属性个数,分别为1和0的属性个数,它们的距离计算方式如下所示:
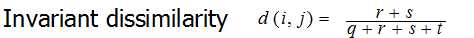
这个公式的含义其实就是两个样本之间,取值不同的属性的数量与所有属性的数量的比值。
对于命名型(nominal variable)来说,其一种简单的距离计算公式为:
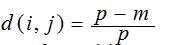
如果样本集的属性类型是混合的,那么有以下公式可以计算距离:
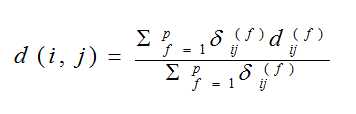
其中分母是属性的权重。
Partitional Clustering
主要思想:首先人为决定将要将数据集分为k个簇,然后根据簇内部相似性要尽可能大,簇之间相似性要尽可能小的思想,将样本分到不同的簇当中去。
1. K-means Clustering
算法过程:首先给k个簇随机分配中心点,然后计算样本集中的每一条数据与k个中心点之间的距离,将这条数据归为距离最小的那个簇。扫描完一轮之后,再重新根据每个簇中的样本,重新计算簇的中心点,然后再扫描样本集,根据新的中心点,计算样本与中心点之间的距离,从而k个簇里的样本更新。迭代几次之后,若重新计算出来的中心点与原来的中心点一样,那么停止迭代。

原理:
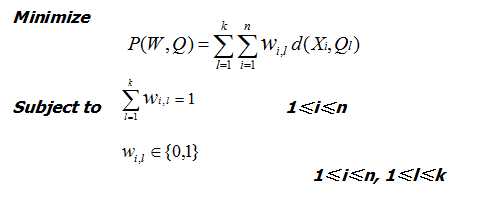
其中l表示l个簇,w(i,l)取值为0,1表示第i个样本是否属于第l个簇,d表示计算i样本与l中心点之间的距离。
我们的目的就是要找到w(i,l)使得这个p函数的值最小。很明显,穷举法时间复杂度太高而不可行。
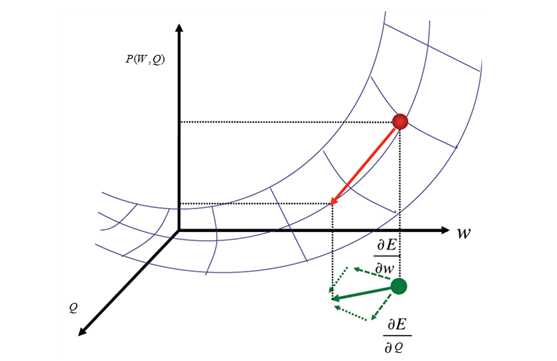
我们采用梯度下降法来解决这个问题,沿着梯度方向下降,从而得到局部最优解。
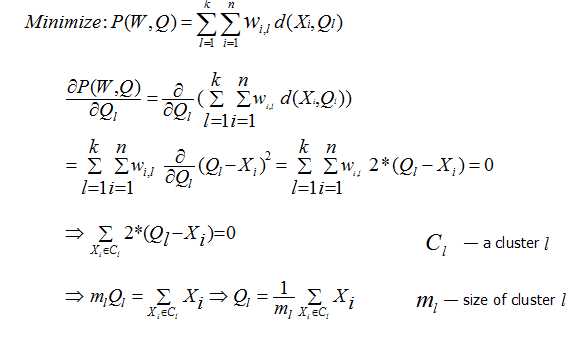
[数据挖掘课程笔记]无监督学习——聚类(clustering)
标签:
原文地址:http://www.cnblogs.com/leeshum/p/4934887.html