标签:
如上次分析,其实map函数中的context.write()调用过程如下所示:

梳理下调用过程,context的write方法其实是调用了TaskInputOutputContext类的write方法,而在这个write方法内部又调用了output字段的write方法,这个output字段是NewOutputCollector类的一个对象,自然就回到了NewOutputCollector(reduce数量不是0)这个类的write方法,而这个方法内部又调用了本类的一个字段collector的collector方法,而collector字段是MapOutputBuffer类型,接下来就主要分析这两个类。
1)NewOutputCollector
private final MapOutputCollector<K,V> collector; private final org.apache.hadoop.mapreduce.Partitioner<K,V> partitioner; private final int partitions;
在构造函数初始化这三个字段,collector初始化MapOutputBuffer的一个对象,partitions就是这次运行job的reduce数量,partitioner就是使用的分区器,利用partitioner对象的getPartitioner(K,V,partitions)就可以得到键值对对应的分区号,然后将这三个参数传给collector的collect方法。MapOutputBuffer才是重点,接下来对其分析。
2)MapOutputBuffer
map的结果并不是直接输入到硬盘的,而是先写入内存缓冲区,这个内存缓冲区是通过三个环形结构的数组组成的,这三个环形数组分别是kvoffsets,kvindices,kvbuffer。这个三个数组又有对应的指示器变量,首先给出三个的关系图:
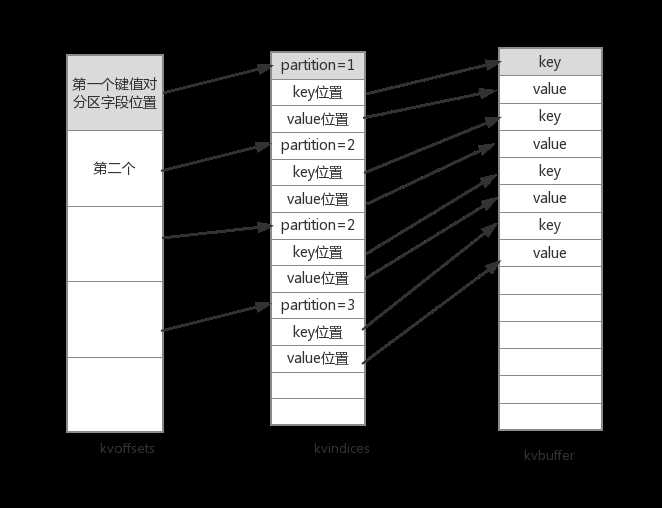
kvoffsets和kvindices都是int[]型数组,而kvbuffer是byte[]类型。kvoffset数组中的一个元素就存储一个键值对对应的分区号在kvindices数组中的索引。而kvindices每次使用三个元素来一个键值对的先关信息:在kvbuffer中key的起始存储位置、在kvbuffer中value的起始存储位置、以及此键值对对应的分区号partition。而kvbuffer就负责存储键值对。需要注意的是,如上图所示,kvoffsets和kvindices存储信息的大小都是确定的,因为我们完全可以一个int型的正数存储索引值和分区号,但是kvbuffer中存储的key、value大小却不是确定的。所以我们在kvindices中只是存储了这些key、value的起始位置。我们不能发现,存储一个键值对会带来16个字节的额外开销(一个int型变量是4个字节),分别是kvoffsets中的1个int变量+kvindices中的3个int变量。
其实,这三个数组的大小是由"io.sort.mb"指定,默认io.sort.mb=100,也就是sortmb=100,那么有maxmemUsage=sortmb<<20,也就是100M。默认这100M中kvoffsets和kvindices占5M(由"io.sort.record.percent"指定,默认值是0.05)其中,kvoffsets与kvindices的比例是1:3(kvoffset中一个索引值对应kvindices中的三个元素)。
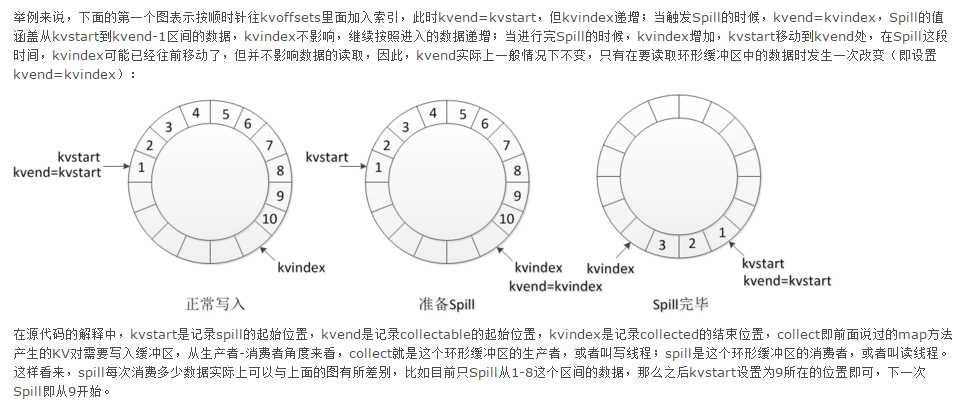
在kvbuffer中如果容量达到一个的比例就会触发spill(溢写)操作,这个比例由"io.sort.spill.percent"指定,默认值是0.8。同样的kvoffsets容量达到一定程度也会触发spill操作,也是由"io.sort.spill.percent"指定。那么为什么要达到一定的比例就spill,而不是写满在spill?原因很简单,如果是写满缓存才spill,那么在刷写磁盘的时候就不能写入(因为我要读取这个缓存区域,写之前“这块区域”就是归写线程所有,其他线程不能访问),那么写线程就会阻塞,map结果就要等待写入缓存,如果达到一定比例就spill,刷写磁盘的时候就只是缓存中一定比例的区域归写线程所有,其他的部分就可以通过写线程写入map的输出,提高了吞吐量。这样就又存在一个问题,如果写线程比spill的过程块,写线程的那块儿区域已经写满了,但是spill还没有完成,也要等待,虽然spill可能已经进行了一大半,spill区域的前半部分已经读取到磁盘。所以才把kvoffsets设计为逻辑上环形数组,写到末尾的时候通过查看下一个可写的位置(kvindex)来决定是否可以写入。如下图所示:
首先给出kvoffsets的相关变量:
kvoffsets:
private volatile int kvstart = 0; //表示当前已写的数据的开始位置 private volatile int kvend = 0; // 未执行spill是等于kvstart,执行spill是不等于kvstart(等于kvindex) private int kvindex = 0; // 表示下一个可写的位置 private final int[] kvoffsets; //volatile修改的字段表示此字段可以被不同线程访问和修改
kvbuffer:
private volatile int bufstart = 0; // marks beginning of spill private volatile int bufend = 0; // marks beginning of collectable private volatile int bufvoid = 0; // marks the point where we should stop // reading at the end of the buffer private int bufindex = 0; // marks end of collected private int bufmark = 0; // marks end of record private byte[] kvbuffer;
bufstart、bufend、bufindex与kvsetoffs中对应的变量意义是相同的,不过又增加了两个变量:bufvoid和bufmark。bufvoid表示实际使用的缓存的最尾部,由于键值对的大小是不确定的,所以使用bufmark来标记一个键值对的结束,每当写入一个键值对,就更新这个值。
map输出的键值对存入缓存之前要首先经过序列化,序列化之后此才存储到缓存中。因为我们是先将序列化的key存入缓存,再将序列化了的value存入缓存,这就存在一个问题:剩下的空间存不下key或者value。
a.如果说存不下value,就会抛出MapBufferTooSmallException异常(这就是触发spill,开始spill过程了)。
b.如果存不下key,那么就要采取措施了。上张图:

红色区域表示已经写入的键值对,第一个图中bufvoid-bufindex即使当前剩余的存储空间,而第二章图中的两块蓝色部分就是存入序列化的key所需要的空间,很明显key的存储跨越了缓存的尾端和首端,但是执行spill的之后我们需要使用RawComparator方法按照key对键值对排序,而这个方法只能对连续的二进制内存buffer进行排序,也就需要每个key都是连续存储的,因此就需要调用BlockingBuffer的reset方法尾端的蓝色部分移动到首端,此时更新bufvoid的值。
c.上面是情况是可以存下key,如果key存不下呢,那么就会直接输出key、value,也就是调用spill线程将键值对写入到文件(这就是触发了spill机制,开始spil了呀!)。
标签:
原文地址:http://www.cnblogs.com/lz3018/p/4940904.html