标签:
本文使用的XML文档格式
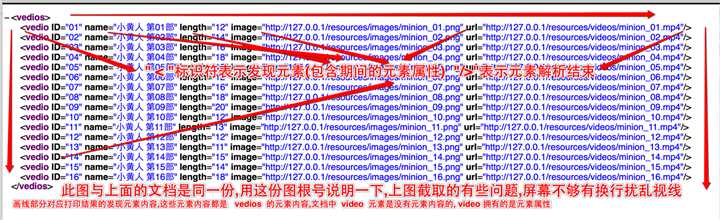
SAX解析XML数据是一行一行的解析,与DOM方式将整个文档加入内存解析方式不同,
SAX解析使用NSParser(apple自带框架)DOM依靠GData(谷歌开发)
SAX解析数据原理:事件驱动,每发现一个元素就通知代理,在代理方法中将发现的元素封装存储到字典中,我们通过遍历字典拿到发现的每个元素,模型化后存放在数据源数组中
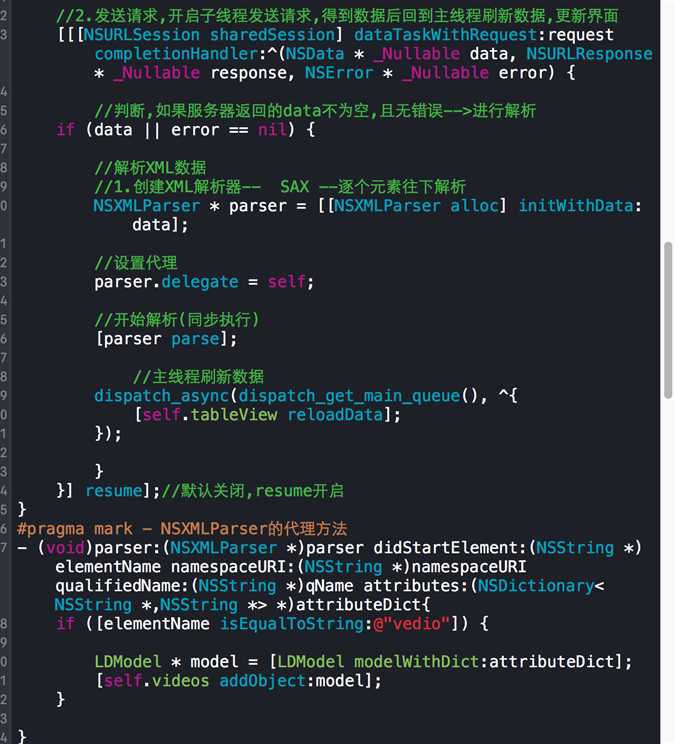
下面给出这个XML文档的SAX解析代码,其余部分代码与前面几篇文章相同
SAX解析常用的代理方法:(都是代理方法,解析器发现一个数据就通知对应代理方法,事件驱动)
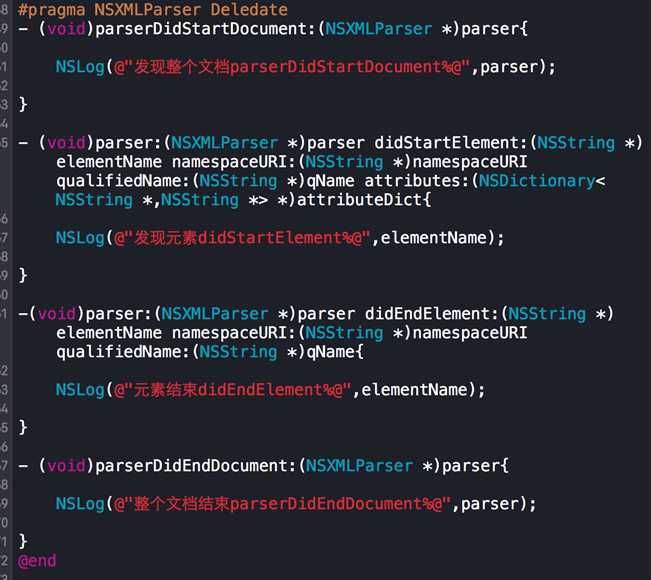
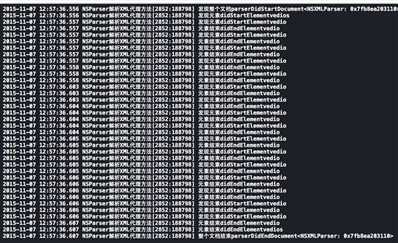
方法执行顺序见下图打印结果,都是成对出现,发现文档与结束文档相对应,发现元素与元素结束相对应.
根据不同情况与需求选择在恰当的方法中执行相应的代码.上篇文章选择didStartElement这个方法中实现数据模型化操作,发现一个跟元素(videos)的子元素(video)就创建一个模型,传递数据后添加到数组中.XML文档中有多少个video元素数组的长度与之对应,
下面单独说一下这个方法:
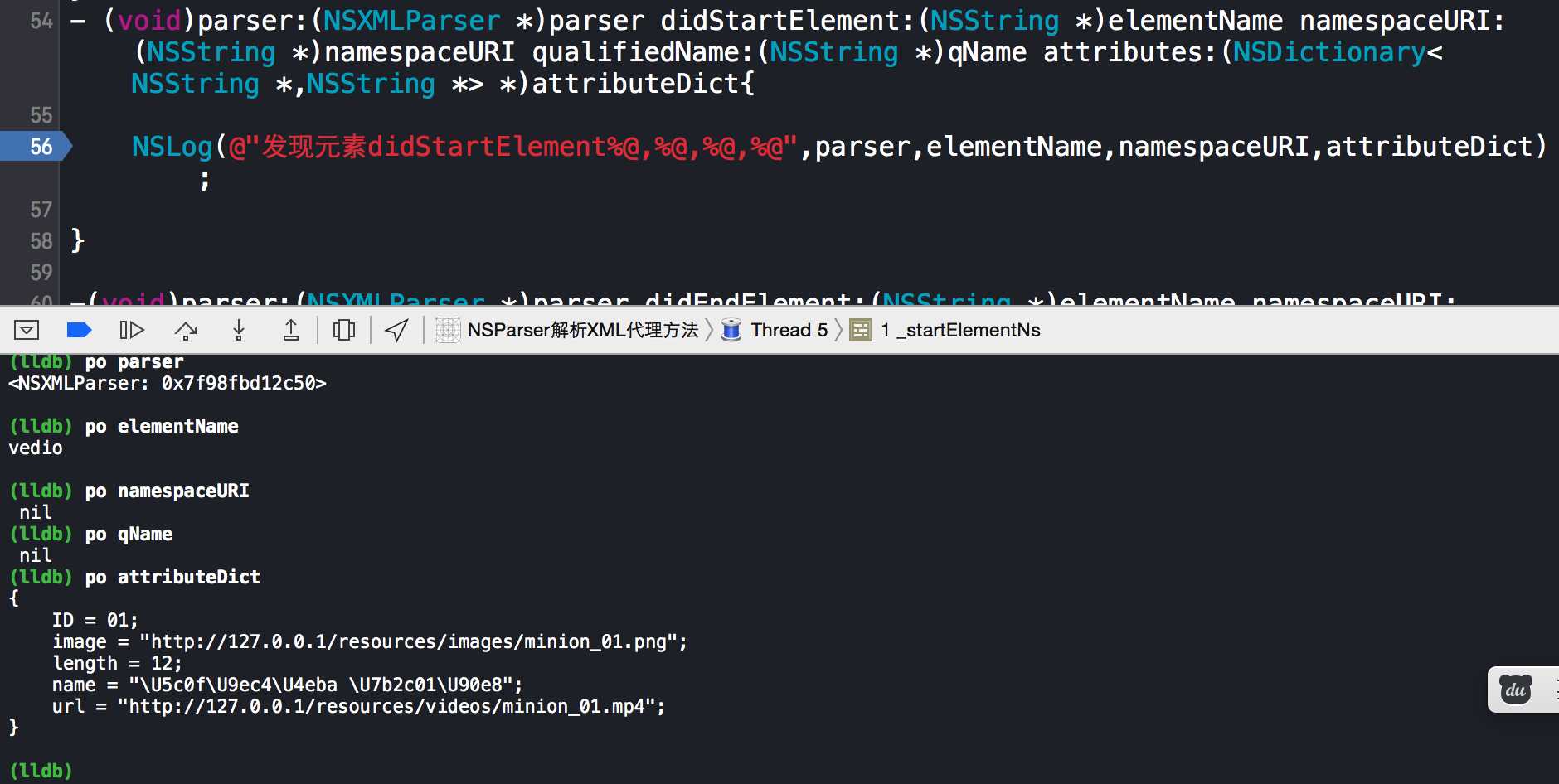
这个方法中其他的参数不知道是干什么的,只发现字典里面有我们需要的数据

这篇文章使用的XML形式,本文使用的方法是didStartElement,这个方法在解析器发现元素的时候通知代理,自动调用,此时附带元素的属性值在内我们都可以获取到,

这是下一篇文章要使用的XML数据,我们需要获取到元素的内容,而非元素(元素属性).注意区分XML这两种形式,清楚我们需要的是哪些数据,注意需要的数据元素(属性),还是元内容.文档格式不同,我们需要的数据锁在的位置不同,意味着我们解析的方式也会不同.
标签:
原文地址:http://www.cnblogs.com/CDSmallCat/p/4945885.html