标签:
首先说下信息熵
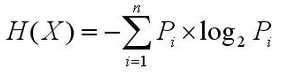 <1>
<1>
其中X可以取x1,x2,...xn,Pi为X取xi的概率,信息熵反应X携带的信息量
引申到分类系统,类别C可以取值C1,C2...Cn,整个分类系统的熵为
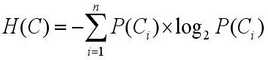 <2>
<2>
其中P(Ci)=Ci类文档数/文档集总文档数
信息增益针对的是特征词t,整个系统有t和没t的信息量的差就是信息增益。
(1)系统有t时候的信息量,即公式<1>
(2)系统没有t的信息量是什么意思呢,分成两种情况:文档中本来就不含有t;文档中含有t,但我们认为t是固定的
这时候使用条件熵来求,即在t存在/不存在的条件下,系统的信息量
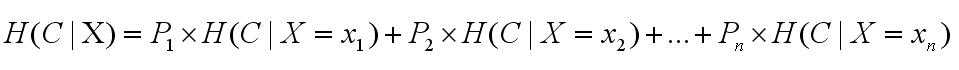 <3>
<3>
具体使用到分类系统中为:
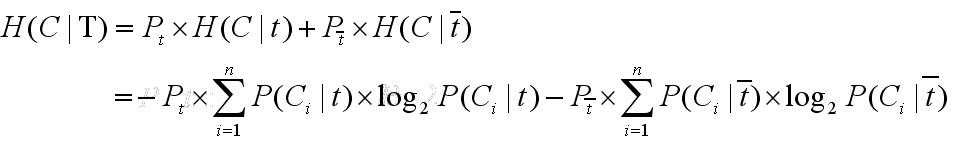 <4>
<4>
其中前半部分是对于包含t的文档,后半部分是对于不包含t的文档
Pt=包含t的文档数/总文档数
P(Ci|t)=Ci类中包含t的文档数/文档集中包含t的文档数
后面反之。
那么特征t的信息增益为: IG(t)=H(C)-H(C|T)
对于给定的训练文档集,要进行文本特征提取,只需将所有IG(t)排序,挑选出前k个即可。
因为对所有t,H(C)是固定的,其实只需要比较H(C|T)即可。
对于类别分布高度不均的文档集,信息增益倾向于选择稀有词汇。
例如,A类文档数>>B类文档数
这样,对于B类中的词,在整个文档集中几乎只出现在B类中,而大部分文档都没有出现
这时候IG取决于公式<4>的后半部分,导致IG值偏高。
标签:
原文地址:http://www.cnblogs.com/IvanSSSS/p/4945924.html